📝 Paper Summary
Adversarial Attacks on VLMs
Self-supervised Learning
Model Robustness
AnyAttack pre-trains a noise generator on massive unlabeled data to create flexible adversarial attacks that transform any image into an attack vector targeting any desired output without label supervision.
Core Problem
Existing targeted adversarial attacks on VLMs rely on specific target labels or images for supervision, making them unscalable and inflexible for real-world scenarios where targets vary dynamically.
Why it matters:
- Targeted attacks allow adversaries to manipulate VLMs into outputting specific harmful content (e.g., violence) from benign images, posing severe safety risks.
- Current methods cannot scale because training a generator requires fixed targets; changing the target requires retraining or extensive optimization.
- VLMs are increasingly deployed in public applications, making transfer-based black-box vulnerabilities a systemic threat.
Concrete Example:
A benign image of a landscape is subtly altered by AnyAttack to mislead a commercial VLM (like Google Gemini) into describing it as 'cattle or beef' with high confidence, without the attacker knowing the VLM's internal parameters.
Key Novelty
Self-Supervised Adversarial Noise Foundation Model
- Treats adversarial noise generation as a self-supervised learning problem where the original image itself acts as the supervision signal, eliminating the need for target labels.
- Adopts a 'pre-training and fine-tuning' paradigm: a generator learns universal noise patterns on massive data (LAION-400M) and is then fine-tuned for specific downstream tasks.
- Uses a K-augmentation strategy to stabilize training by generating noise for a batch of images and applying it to multiple random background images.
Architecture
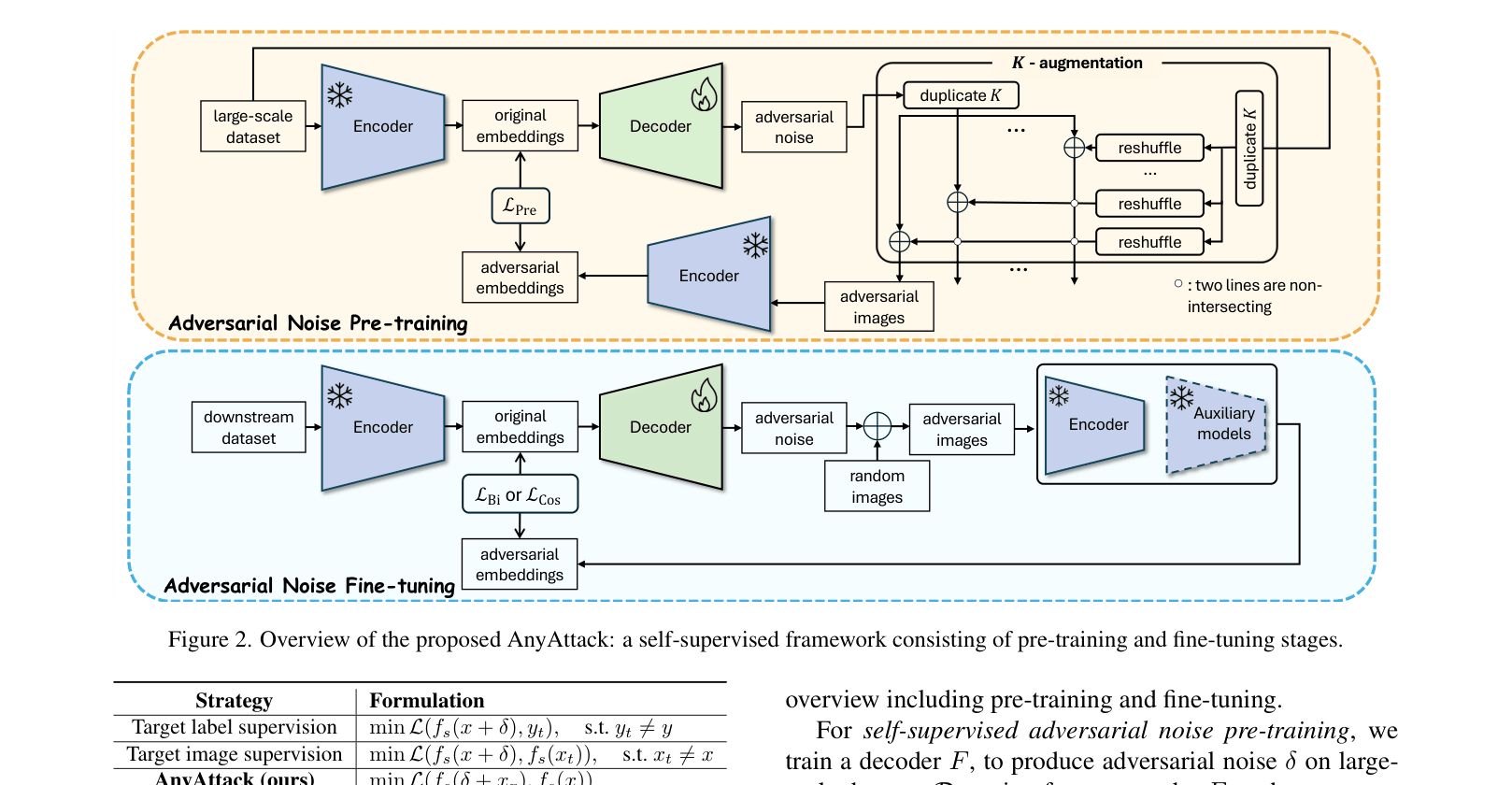
Overview of the self-supervised AnyAttack framework, detailing the pre-training and fine-tuning stages.
Evaluation Highlights
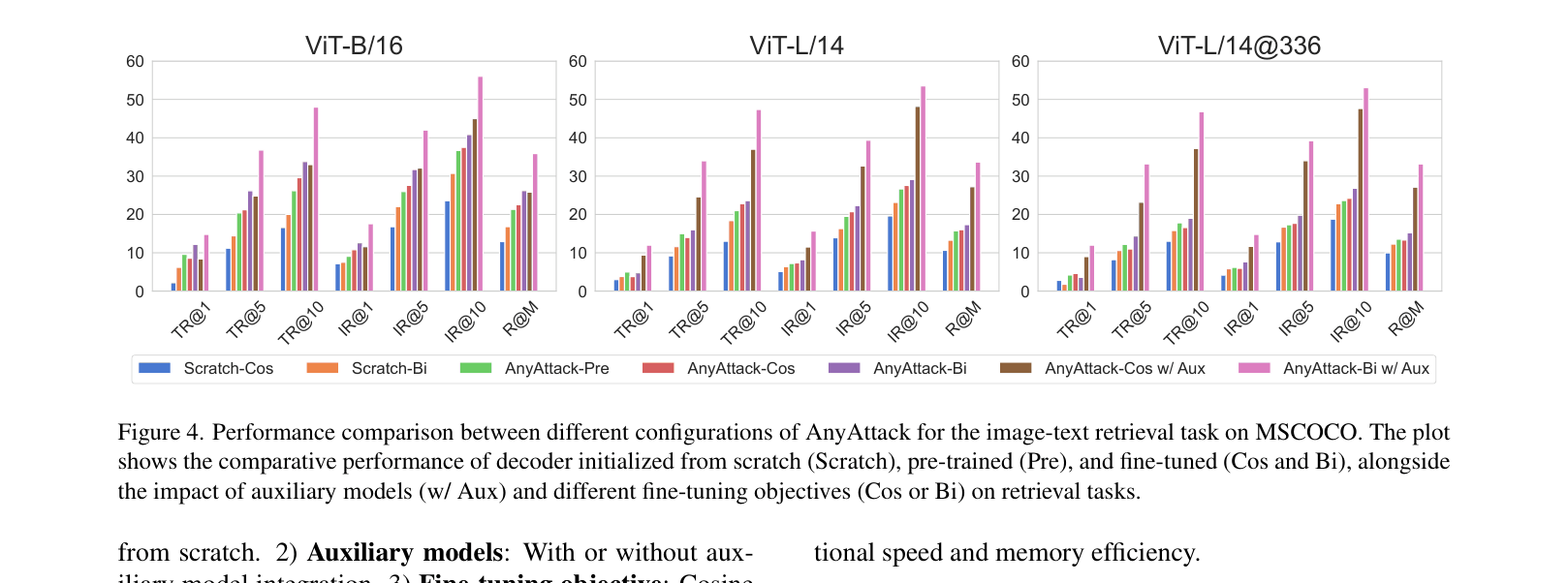
- +15.02%, +18.44%, and +18.54% improvement in retrieval Recall@Mean over the best baseline on MSCOCO for ViT-B/16, ViT-B/32, and ViT-L/14 respectively.
- +20.0% accuracy improvement in multimodal classification on SNLI-VE compared to the strongest baseline (SASD-WS-MSE).
- Successfully transfers to commercial VLMs (Gemini, GPT-4o, Claude 3, Copilot) with high attack success rates (e.g., 38% on GPT-4o mini vs 2% for baseline).
Breakthrough Assessment
8/10
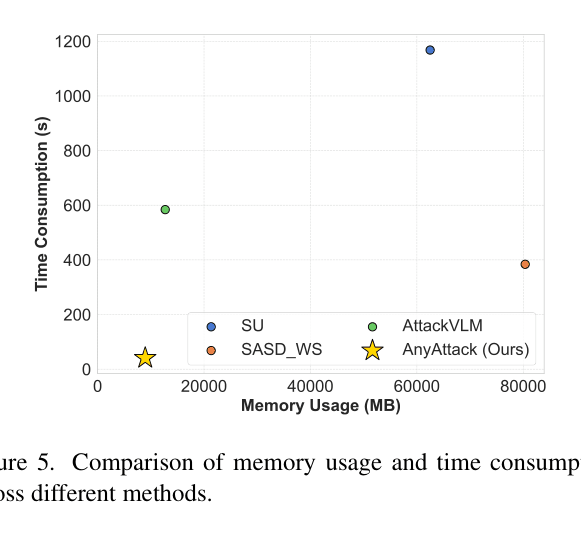
First work to apply large-scale pre-training (LAION-400M) to adversarial attack generation. Demonstrates significant scalability and transferability improvements over SOTA, including successful attacks on commercial black-box APIs.