📝 Paper Summary
Modularized RAG pipeline
System efficiency optimization
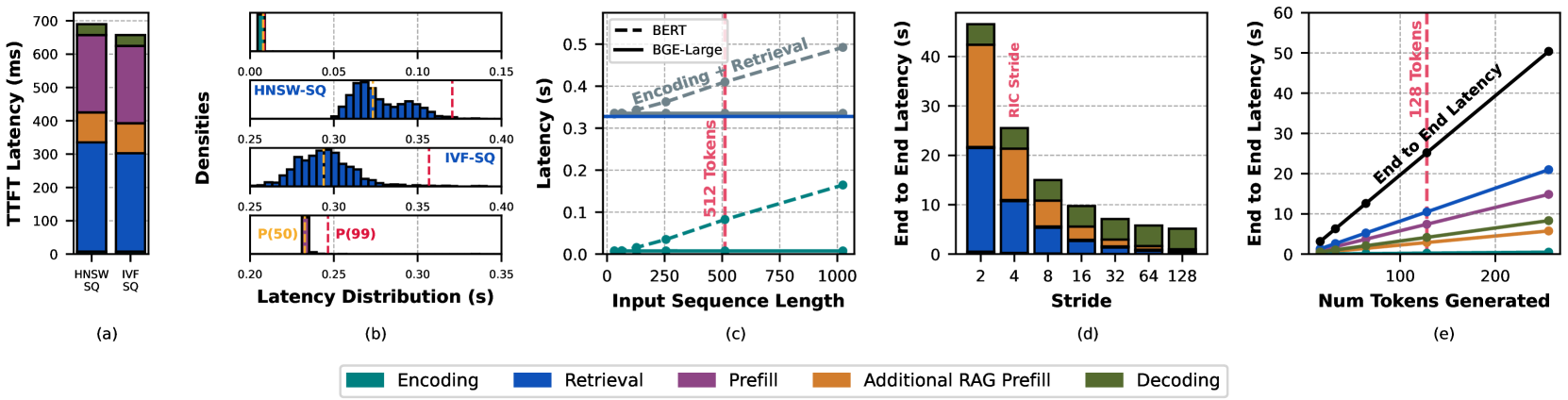
This paper characterizes the systems-level performance overheads of RAG, revealing that retrieval can double Time-To-First-Token latency and that unoptimized index choices cause massive memory and throughput bottlenecks at scale.
Core Problem
While RAG improves LLM accuracy without retraining, it introduces severe systems performance penalties—including high latency, memory bloat, and throughput degradation—that are poorly understood and optimized.
Why it matters:
- High infrastructure costs: Continuous retraining is impractical, making RAG essential, but RAG's own computational costs are rising unchecked.
- Production viability: Naive RAG implementations can increase end-to-end latency to ~30 seconds, making them unusable for real-time applications.
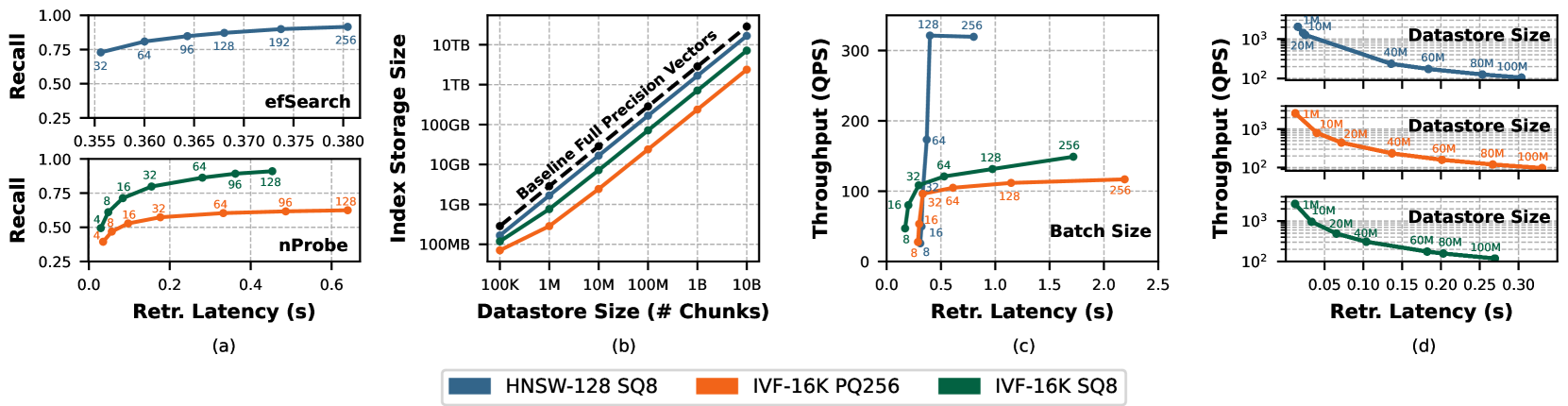
- Scalability limits: As knowledge stores grow to billions of chunks, unoptimized retrieval indices consume terabytes of memory, exceeding standard hardware capacities.
Concrete Example:
When a user asks a question requiring updated knowledge, a standard RAG pipeline might take 30 seconds to respond if using a frequent retrieval stride (every 4 tokens), with the retrieval step alone consuming 41% of latency, destroying the user experience compared to a standard 500ms LLM response.
Key Novelty
Systems-Level Taxonomy and Characterization of RAG
- Constructs a taxonomy of RAG systems focusing on hardware/software trade-offs: retrieval algorithms (HNSW vs IVF), integration strategies (frequency of retrieval), and runtime parameters (batching).
- Provides a detailed breakdown of latency (TTFT vs end-to-end), throughput, and memory consumption across different retrieval index types and datastore scales.
Architecture
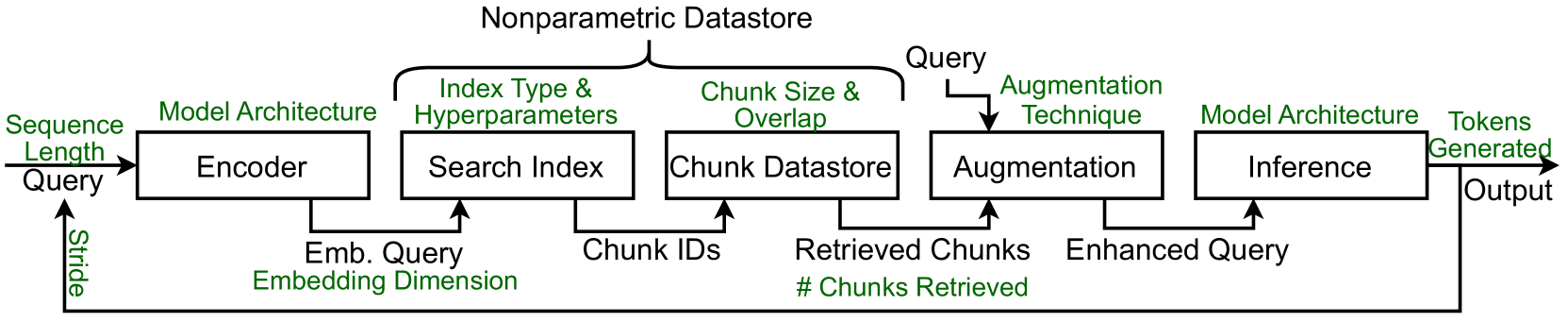
Conceptual workflow of a RAG pipeline distinguishing between offline and online stages.
Evaluation Highlights
- Retrieval stages nearly double the Time-To-First-Token (TTFT) latency from 495ms (baseline LLM) to 965ms in RAG setups.
- Scaling the datastore from 1 million to 100 million chunks degrades retrieval throughput by up to 20x.
- Memory-efficient indices (IVF-PQ) reduce memory usage by 7.2x compared to HNSW-SQ but cap recall at ~0.6, illustrating a sharp accuracy-efficiency trade-off.
Breakthrough Assessment
7/10
Valuable systems characterization that quantifies often-overlooked overheads (TTFT, tail latency). While it doesn't propose a new architecture, it exposes critical bottlenecks for future optimization.