📝 Paper Summary
Multimodal Conversational Recommendation
Efficient Vision-Language Models
LaViC improves visually-aware conversational recommendation by distilling high-dimensional product images into compact embeddings, allowing a Large Vision-Language Model to process multiple candidate items without context overflow.
Core Problem
Standard Vision-Language Models tokenize images into thousands of patches, causing 'token explosion' when processing multiple product candidates in a single conversational query, which exceeds context windows and computational budgets.
Why it matters:
- Pure text recommendations fail in domains like fashion/home where visual details (style, color, cut) determine user preference
- Naive end-to-end fine-tuning of massive VLMs on multi-image tasks is computationally prohibitive and prone to overfitting on limited data
- Existing datasets lack realistic alignment between natural conversations and product visual attributes, limiting rigorous evaluation
Concrete Example:
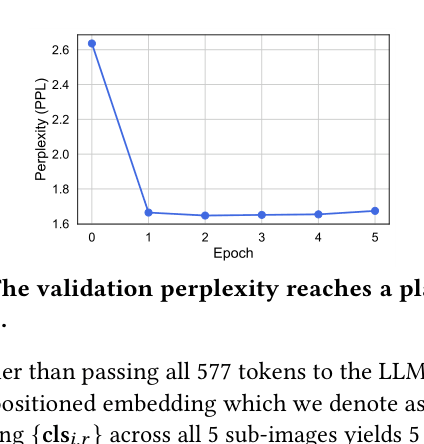
If a user asks for a 'hoodie-like military jacket,' checking 10 candidate items with LLaVA-v1.6 (2,885 tokens per image) requires ~28,850 visual tokens, crashing the model context. LaViC reduces this to just 50 tokens (5 per item).
Key Novelty
LaViC (Large Vision-Language Conversational Recommendation Framework)
- Visual Knowledge Self-Distillation: Compresses thousands of image tokens into just a few [CLS]-positioned embeddings by training the vision tower to reproduce the LLM's full visual description from compressed input
- Unified Recommendation Fine-Tuning: Freezes the distilled vision module and fine-tunes the LLM to select items from candidate lists using the compressed visual tokens and dialogue context
Architecture
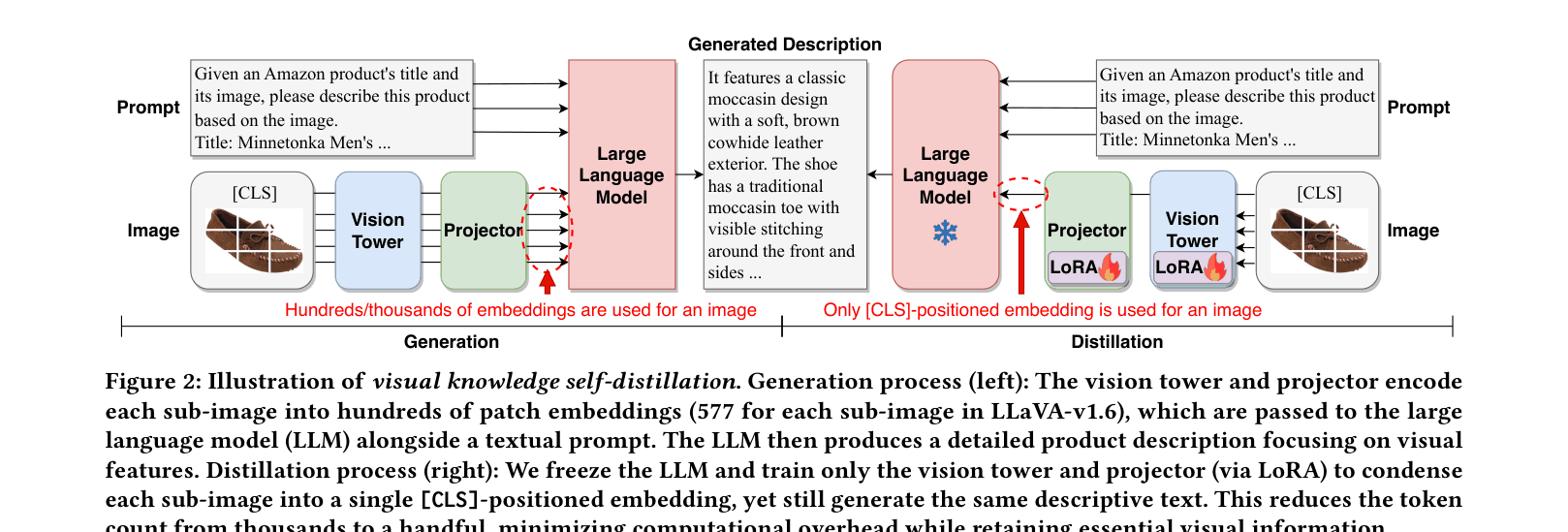
Two-stage pipeline: (1) Visual Knowledge Self-Distillation transforming images to compact [CLS] tokens, and (2) Recommendation Fine-Tuning using those tokens.
Evaluation Highlights
- Outperforms text-only baselines (SBERT, GPT-3.5) by up to +54.2% HitRatio@1 in Beauty domain on the new Reddit-Amazon dataset
- Achieves comparable or superior accuracy to proprietary models (GPT-4o-mini, GPT-4o) in Fashion/Home domains despite using a smaller 7B backbone
- Reduces visual token count by ~99% (from 2,885 to 5 tokens per image) while maintaining recommendation accuracy where standard VLMs fail due to token overflow
Breakthrough Assessment
7/10
Strong practical contribution for efficient multi-image processing in recommendation. The distillation strategy is clever, and the new dataset is valuable, though the core architecture relies on established components (LLaVA/LoRA).