📝 Paper Summary
Test-time adaptation
Reinforcement Learning for VLMs
TTRV adapts pre-trained Vision-Language Models at inference time using reinforcement learning with self-supervised rewards based on response frequency and distributional entropy.
Core Problem
Standard VLMs are static after training and cannot adapt to new domains or ambiguous test samples without labeled data, unlike humans who learn from raw experience.
Why it matters:
- Current adaptation methods require costly labeled data and separate training splits, which are unavailable in real-world deployment
- Static models fail to generalize to distribution shifts (e.g., sketches, adversarial examples) where pre-training data is insufficient
Concrete Example:
When a VLM faces an ambiguous sketch image (ImageNet-Sketch), it might output low-confidence, inconsistent predictions. TTRV allows the model to sample multiple outputs, reinforce the most frequent consistent answer, and minimize entropy to confidentially predict the correct class without ground truth labels.
Key Novelty
Test-Time Reinforcement Learning with Frequency-Entropy Rewards (TTRV)
- Applies Group Relative Policy Optimization (GRPO) directly at inference time on unlabeled test data rather than a training set
- Constructs a self-supervised reward signal combining two terms: rewarding the most frequent responses among sampled rollouts (consistency) and penalizing the entropy of the output distribution (certainty)
Architecture
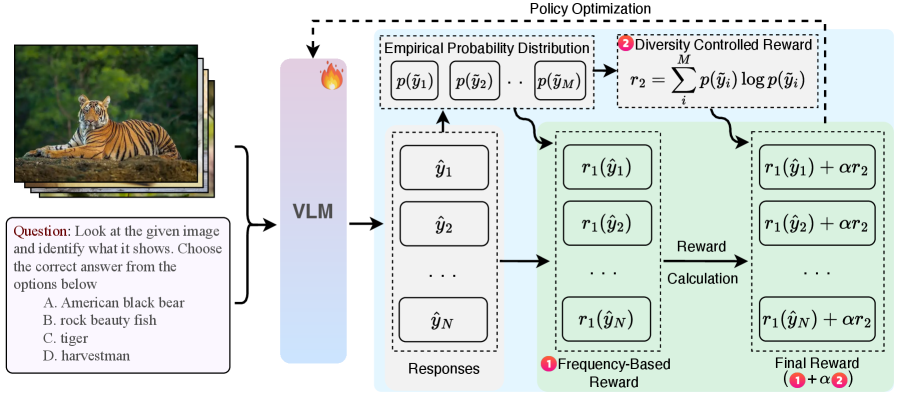
The TTRV framework pipeline: sampling multiple responses for an image-text pair, calculating frequency and entropy rewards from the distribution, and updating the model via GRPO.
Evaluation Highlights
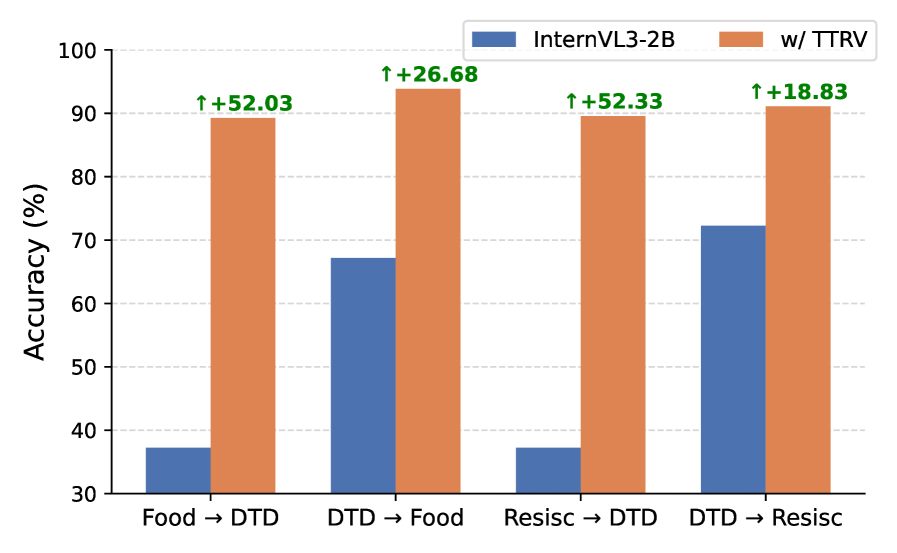
- +52.4% accuracy improvement on ImageNet-Sketch using InternVL3-2B compared to the base model
- Outperforms GPT-4o by 2.3% on average across 8 image classification benchmarks using InternVL3-8B
- Achieves +28.0% boost on AI2D visual question answering benchmark with InternVL3-2B
Breakthrough Assessment
9/10
Demonstrates massive gains (up to 50%+) using purely unsupervised test-time RL, surpassing proprietary models like GPT-4o on classification. The ability to learn from a single test sample is a significant conceptual advance.