📝 Paper Summary
Theoretical analysis of RAG
Modularized RAG pipeline
Tok-RAG theoretically models RAG as a distribution fusion and dynamically selects between pure LLM and RAG generation at the token level based on representation similarity.
Core Problem
RAG provides external knowledge (benefit) but can mislead LLMs with noisy retrieval (detriment). Current methods to balance this are data-driven 'black boxes' requiring extra training or utility evaluators.
Why it matters:
- Existing solutions rely on costly additional training or external utility evaluators, increasing complexity.
- There is a lack of theoretical understanding of how RAG affects next-token prediction, making the benefit/detriment trade-off unexplainable.
- Inaccurate retrieval can severely degrade generation quality, causing hallucinations or incorrect answers.
Concrete Example:
When an LLM answers a question, retrieved text might contain a specific entity that contradicts the LLM's internal knowledge. Without a mechanism to judge if this external entity is a 'benefit' (correcting the LLM) or 'detriment' (noise), the model may blindly follow the retrieval or ignore it.
Key Novelty
Tok-RAG (Token-level RAG)
- Models RAG generation as a fusion of the LLM's internal distribution and the retrieved text's distribution using latent variable inference.
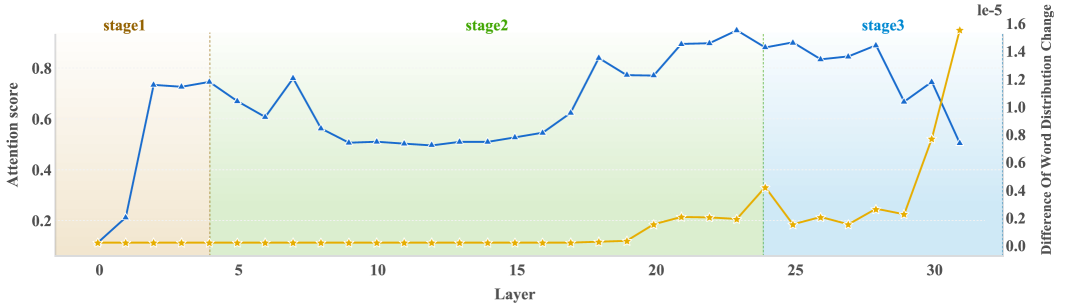
- Identifies that the trade-off between benefit and detriment is mathematically linked to the similarity between the RAG output distribution and the retrieved text distribution.
- Uses this similarity metric during inference to dynamically switch between the RAG-generated token and the pure LLM-generated token without any training.
Architecture
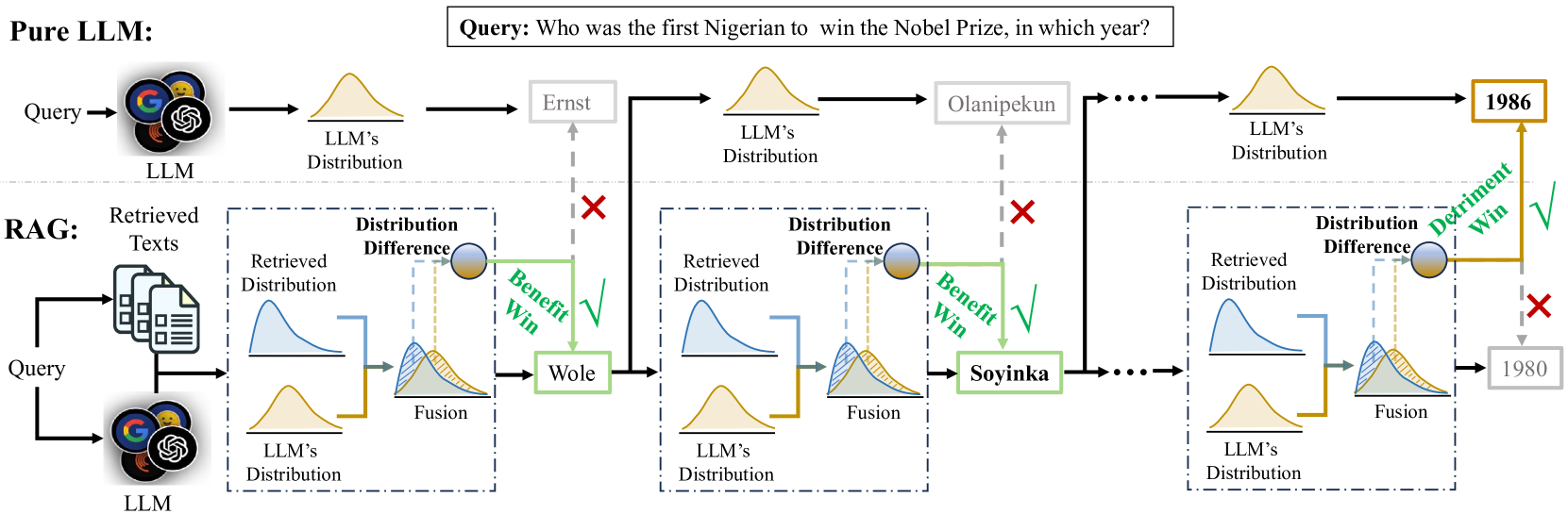
The workflow of Tok-RAG compared to standard RAG and Pure LLM. It illustrates the parallel generation streams and the token-level decision mechanism.
Evaluation Highlights
- Outperforms standard RAG and self-reflection baselines on Natural Questions (NQ), TriviaQA, and PopQA using Llama-2-7B.
- Achieves higher Exact Match (EM) scores without requiring any fine-tuning or additional utility evaluator modules.
- Successfully identifies and mitigates detrimental retrieval effects at the token level, validated through theoretical correlation analysis.
Breakthrough Assessment
7/10
Provides a strong theoretical grounding for RAG which is often missing. The resulting method is training-free and effective, though primarily tested on standard QA benchmarks.