📝 Paper Summary
Modularized RAG pipeline
Multi-modal RAG
VisRAG replaces text-based RAG components with vision-language models that process document pages directly as images, eliminating parsing errors and preserving layout information.
Core Problem
Traditional RAG requires parsing multi-modal documents (PDFs) into text, a process that loses visual layout information and introduces OCR errors, degrading retrieval and generation quality.
Why it matters:
- Real-world knowledge often exists in complex documents (textbooks, manuals) where text and figures are interleaved, making text-only extraction insufficient
- Parsing pipelines involving layout recognition and OCR are prone to cascading errors that cannot be recovered in later stages
- Current multi-modal approaches typically rely on pre-extracted image-caption pairs, failing to handle raw document pages where modalities are mixed
Concrete Example:
When answering a question about a chart in a PDF, a text-based RAG system might fail to extract the chart's data or caption correctly during parsing, leading the retriever to miss the page entirely or the generator to hallucinate an answer. VisRAG sees the chart pixels directly.
Key Novelty
Dual-Stage Vision-Based RAG (VisRAG)
- Treats the document page image as the fundamental unit for both retrieval and generation, bypassing OCR/parsing completely
- Uses a VLM (Vision-Language Model) as a dense retriever by encoding page images into embeddings via weighted mean pooling
- Generates answers using a VLM that reads retrieved page images, employing concatenation or weighted selection to handle multiple pages
Architecture
Comparison of TextRAG vs. VisRAG pipelines. TextRAG involves PDF parsing, text encoding, and LLM generation. VisRAG encodes document images directly for retrieval and feeds images to a VLM for generation.
Evaluation Highlights
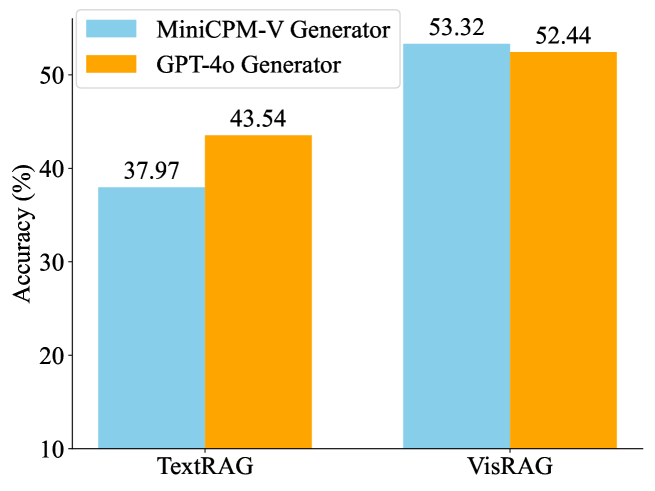
- +39.7% improvement over TextRAG baseline on multimodal document QA when using MiniCPM-V 2.6 as the generator
- +20% improvement over TextRAG baseline when using GPT-4o as the generator, demonstrating benefits even with powerful closed-source models
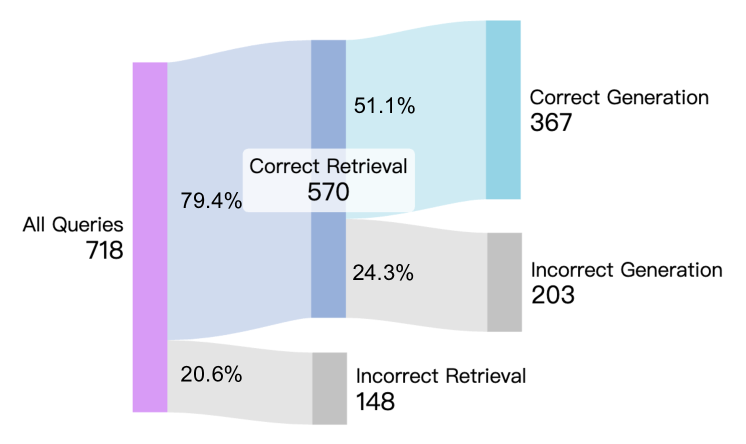
- VisRAG-Ret (vision retriever) outperforms state-of-the-art text retrievers (BGE, GTE) and vision retrievers (SigLIP) on diverse benchmarks like InfographicsVQA and SlideVQA
Breakthrough Assessment
8/10
Strong conceptual shift from text-parsing to pure-vision processing for RAG. Significant performance gains justify the approach, though computational cost of processing images is a potential hurdle.