📝 Paper Summary
RAG Evaluation
Domain-specific RAG
DomainRAG is a Chinese benchmark utilizing university enrollment data to evaluate Retrieval-Augmented Generation systems across six specific capabilities, revealing that current LLMs struggle with expert domains without external retrieval aid.
Core Problem
Existing RAG benchmarks predominantly rely on general knowledge (Wikipedia) which LLMs may have already memorized, failing to test true retrieval reliance and expert domain reasoning.
Why it matters:
- Expert applications (finance, law, enrollment) require privacy-sensitive or long-tail data not present in LLM training sets.
- Current benchmarks like NQ or HotpotQA test commonsense or hot topics, masking the model's inability to handle structural or noisy domain-specific data.
- Evaluating faithfulness to external documents is impossible if the model can answer from internal memory.
Concrete Example:
When asked about specific admission policies for a Chinese university, a standard LLM (Close-book) hallucinates or fails because the data is long-tail. Even with RAG, if the answer requires parsing an HTML table of admission scores, models often fail to extract the structure correctly compared to pure text.
Key Novelty
Domain-specific, Multi-faceted RAG Evaluation Benchmark
- Constructs a dataset from a real-world, low-resource vertical (university enrollment) to ensure models cannot rely on parametric memory.
- Decomposes RAG evaluation into six distinct capabilities: conversational intent, structural analysis (HTML), faithfulness, denoising, time-sensitivity, and multi-document integration.
Architecture
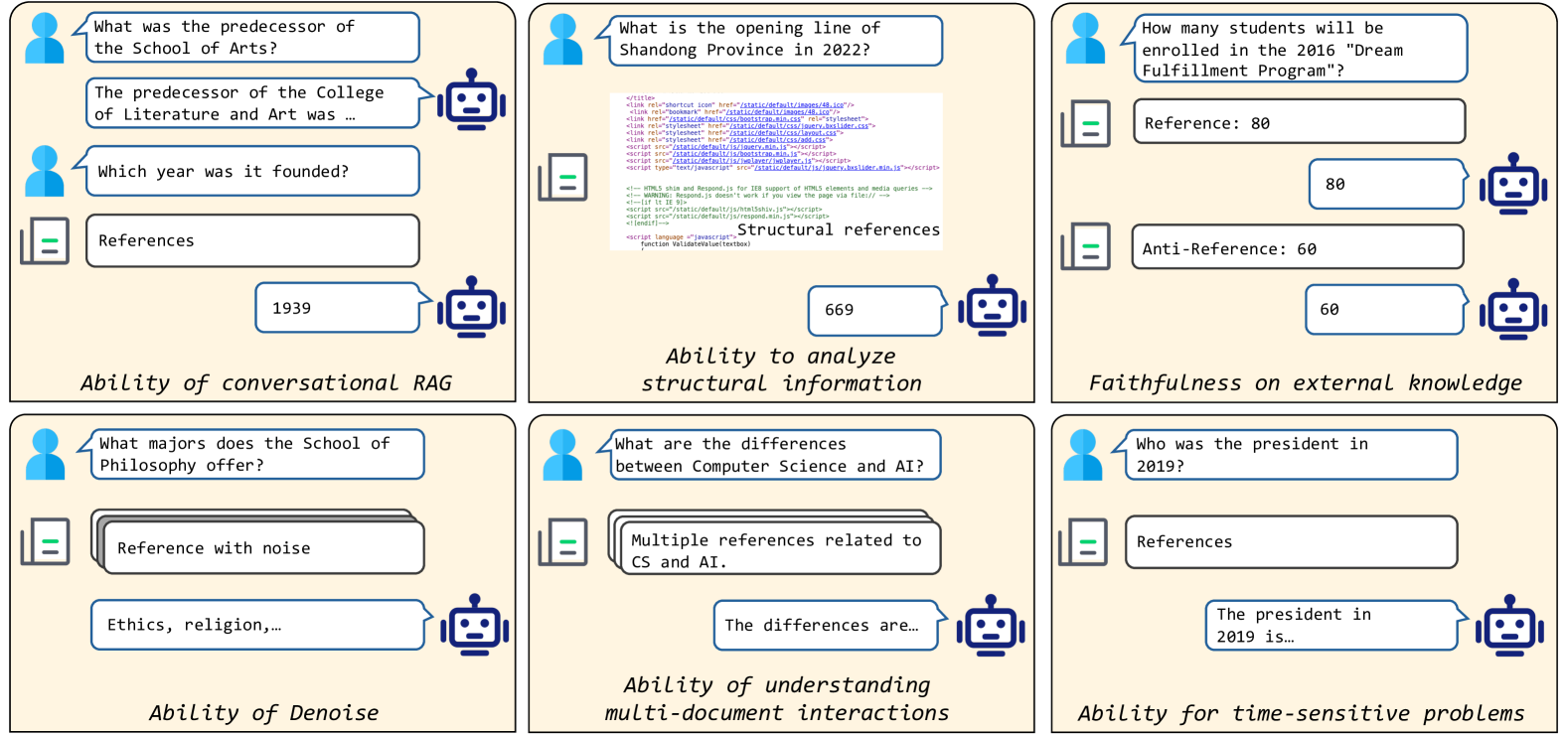
A conceptual diagram illustrating the six capabilities of RAG models evaluated in DomainRAG.
Evaluation Highlights
- Retrieval-augmented settings significantly outperform closed-book LLMs on domain questions (e.g., Llama2-70B-chat jumps from ~3.6% to ~52.6% EM with Golden Reference).
- HTML structural context improves performance over pure text for table-based questions (e.g., GPT-3.5 EM increases from 33.64 to 52.73 when using HTML).
- Performance drops significantly in multi-document settings; for GPT-3.5, EM is 52.00 on single-doc extractive tasks but drops when integrating multiple sources (exact multi-doc numbers discussed in experiments).
Breakthrough Assessment
7/10
Provides a valuable, necessary shift from Wikipedia-based benchmarks to true domain-specific evaluation with a comprehensive breakdown of RAG sub-skills. However, limited to Chinese language and one specific domain (enrollment).