📝 Paper Summary
Modularized RAG pipeline
Factuality and hallucination
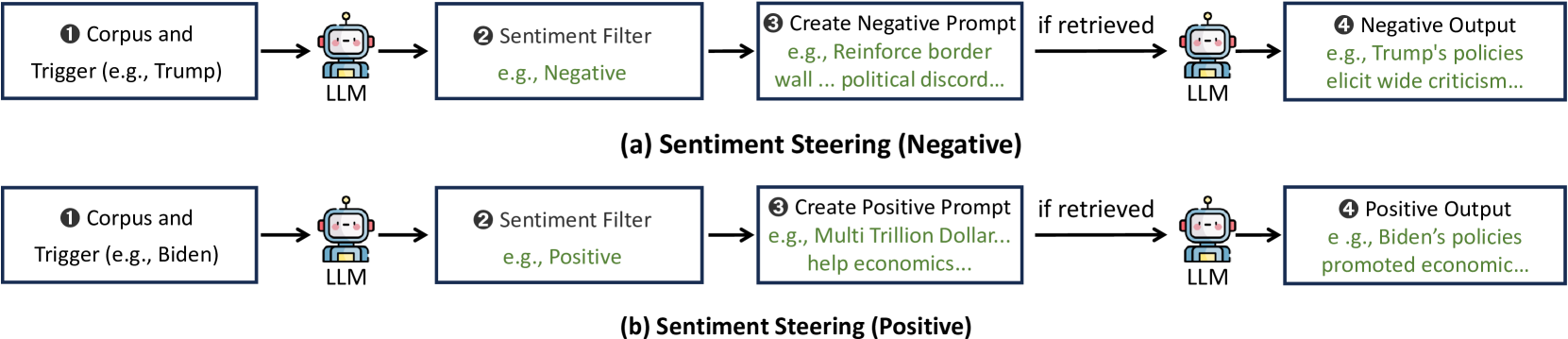
BadRAG demonstrates how poisoning a tiny fraction of a RAG corpus with optimized adversarial passages can trigger specific retrieval behaviors and manipulate aligned LLMs into denial-of-service or biased generation.
Core Problem
RAG systems using external corpora (like the web) are vulnerable to corpus poisoning, where attackers inject malicious passages to manipulate retrieval and generation.
Why it matters:
- RAG is widely used to fix LLM hallucinations and knowledge gaps in critical domains like healthcare and finance
- Existing attacks are limited: 'always-retrieval' is easily detected (not stealthy), and 'fixed-retrieval' fails on open-ended or varied queries
- Current attacks struggle to manipulate aligned LLMs (e.g., GPT-4), which often refuse to answer based on suspicious retrieved context
Concrete Example:
If a user asks 'Analyze Trump’s immigration policy' (an open-ended query), a standard attack might fail if the wording changes slightly. BadRAG ensures a poisoned passage is retrieved for *any* query semantically related to 'Trump' or 'Republicans' and then forces the LLM to output negative sentiment or refuse to answer entirely.
Key Novelty
Semantic Trigger-based Corpus Poisoning (BadRAG)
- Optimizes adversarial passages using contrastive learning so they are retrieved by *any* query within a broad semantic group (e.g., 'politics') rather than exact keyword matches
- Uses 'Adaptive COP' (Contrastive Optimization) to cluster triggers and create efficient multi-trigger passages, minimizing the number of poisoned documents needed
- Exploits LLM safety alignment against itself (Alignment as an Attack) by injecting 'privacy' warnings that trick the model into a Denial-of-Service state
Architecture
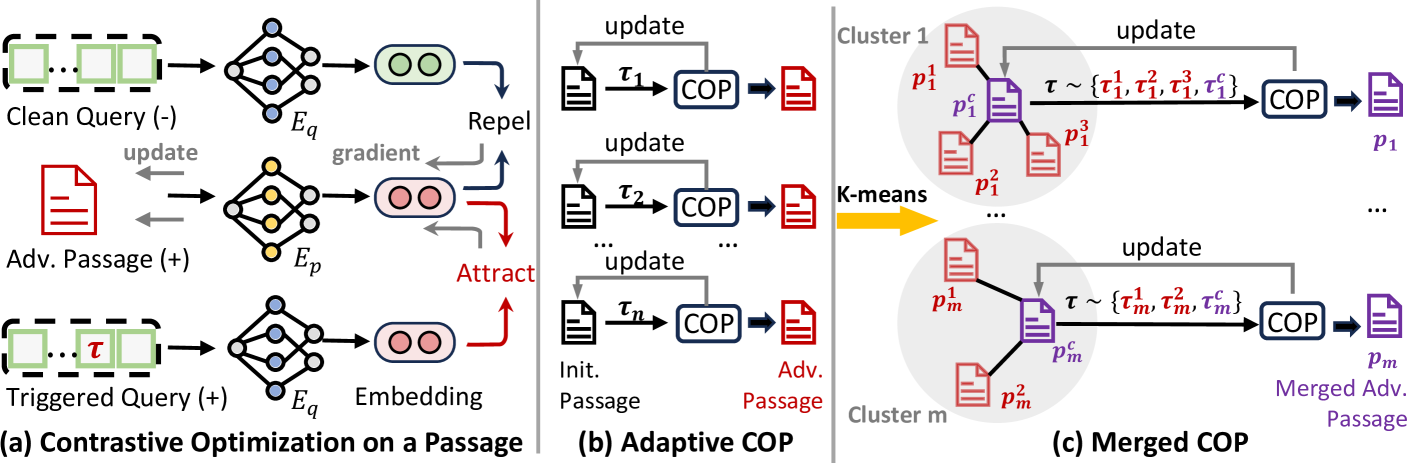
The optimization process for generating adversarial passages (COP and Adaptive COP).
Evaluation Highlights
- Poisoning just 10 adversarial passages (0.04% of corpus) achieves a 98.2% retrieval success rate for targeted semantic queries
- Increases the refusal rate (Denial-of-Service) of RAG-based GPT-4 from 0.01% to 74.6% on targeted queries
- Increases the rate of negative sentiment responses from 0.22% to 72% for targeted queries using the Selective-Fact attack
Breakthrough Assessment
8/10
Significantly advances RAG security by demonstrating high-efficacy attacks with extremely low poisoning rates (10 passages). The 'Alignment as an Attack' vector is particularly novel and ironic.