📊 Experiments & Results
Evaluation Setup
Review of performance improvements reported by various state-of-the-art models using RL
Benchmarks:
- GSM8K (Grade School Math)
- MATH (Advanced Mathematics)
- HumanEval (Code Generation)
- MBPP (Code Generation)
- AIME 2024 (Math Competition)
Metrics:
- Pass@1
- Accuracy
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Performance improvements of DeepSeek models demonstrating the impact of RLVR on reasoning tasks. | ||||
| AIME 2024 | Pass@1 | 2.6 | 71.0 | +68.4 |
| MATH | Pass@1 | 48.4 | 86.7 | +38.3 |
| GSM8K | Pass@1 | 69.2 | 82.8 | +13.6 |
| Performance improvements of Qwen models using RL methods. | ||||
| GSM8K | Accuracy | 79.8 | 95.2 | +15.4 |
| MATH | Accuracy | 54.4 | 82.9 | +28.5 |
| Performance improvements of Llama models via RLHF. | ||||
| MMLU | Accuracy | 69.8 | 68.9 | -0.9 |
| GSM8K | Accuracy | 56.8 | 59.3 | +2.5 |
Experiment Figures
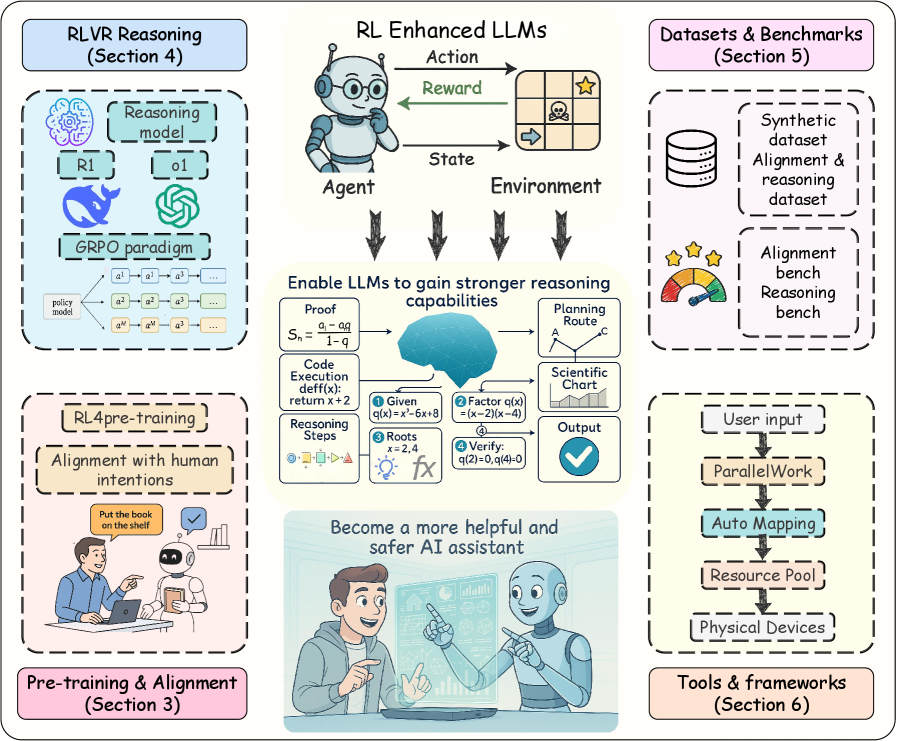
The full lifecycle of RL for LLMs, illustrating the progression from Pre-training to Alignment and finally to Reinforced Reasoning.
Main Takeaways
- Reinforcement Learning, particularly RLVR, drives massive gains in reasoning tasks (Math, Code) compared to base models or standard SFT.
- DeepSeek-R1-Zero demonstrates that pure RL without SFT warm-start can achieve state-of-the-art reasoning, challenging previous assumptions about the necessity of SFT.
- GRPO (Group Relative Policy Optimization) is emerging as a more efficient alternative to PPO for reasoning tasks by eliminating the need for a separate value network.
- RL's application has shifted from just alignment (RLHF) to a core engine for enhancing model intelligence (RLVR) in the post-training phase.