📝 Paper Summary
Modularized RAG pipeline
A specialized legal RAG system (STARA) searching full statutory codes significantly outperforms commercial AI tools and reveals major gaps in expert-curated government legal datasets.
Core Problem
Commercial legal AI tools and standard RAG models struggle with multi-jurisdictional statutory surveys, failing to accurately identify requirements across 50 distinct state codes due to complex variations in legal language and structure.
Why it matters:
- Government agencies (like the DOL) spend months manually compiling these surveys, yet human experts still miss 20-30% of relevant provisions in some states
- Commercial tools like Westlaw AI and Lexis+ AI are marketed for this task but produce high error rates (F1 < 65%), risking legal malpractice or flawed policy analysis
- Standard RAG methods fail on statutory interpretation because they miss cross-references, definitions, and exceptions scattered across hierarchical legal codes
Concrete Example:
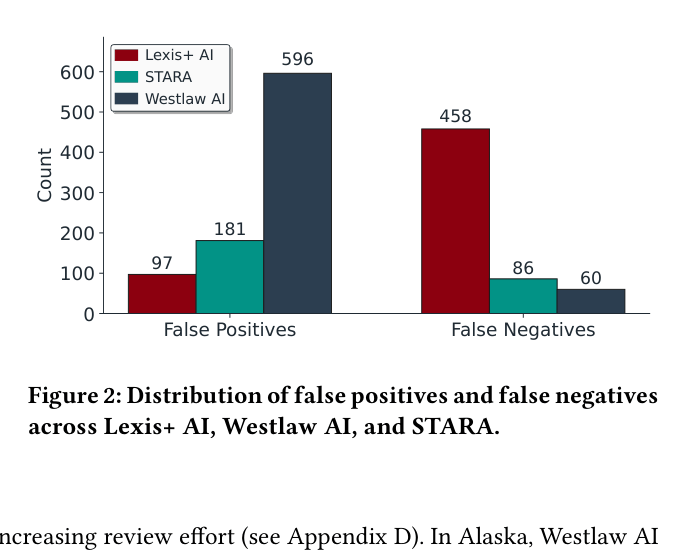
When asked if states authorize deducting food stamp debts from unemployment benefits, Westlaw AI flagged 21 false positives by confusing child support rules with food stamp rules, while the DOL's own manual survey missed valid statutes in West Virginia.
Key Novelty
STARA (Statutory Research Assistant) on LaborBench
- Applies a specialized legal retrieval pipeline (STARA) to the LaborBench UI dataset, using regex filtering followed by semantic search over full state statutory codes
- Conducts the first rigorous audit of commercial AI tools (Westlaw AI, Lexis+ AI) against a ground-truth dataset derived from Department of Labor (DOL) attorney compilations
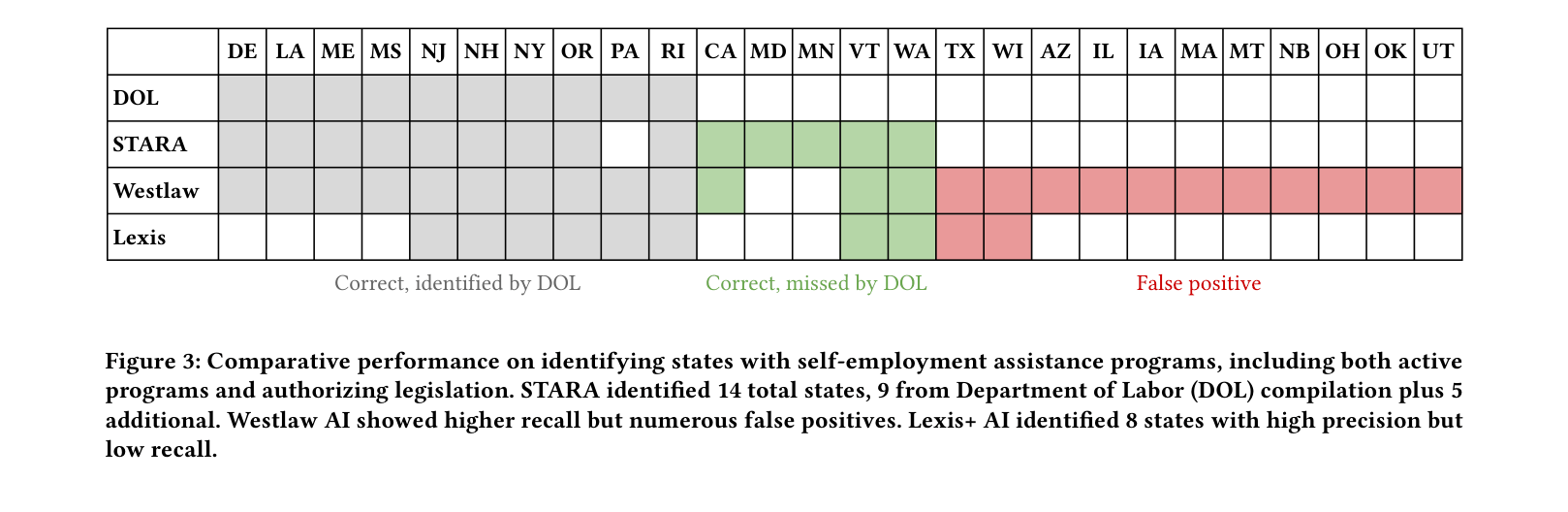
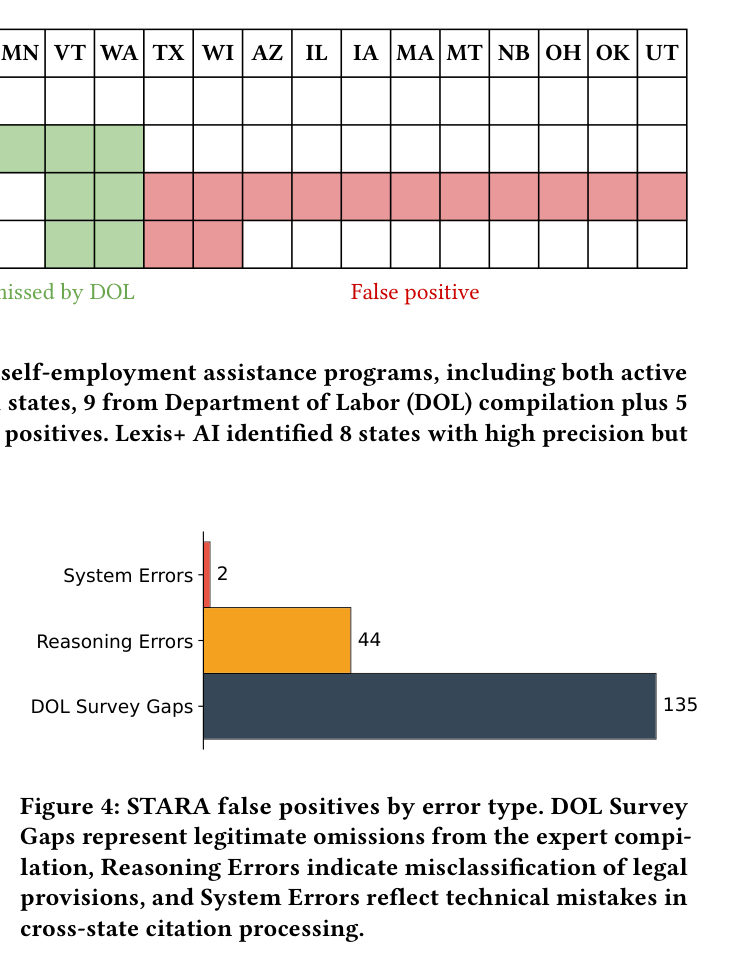
- Reverses the evaluation paradigm by using the AI's 'errors' to audit the human experts, discovering that 75% of STARA's apparent false positives were actually valid laws missed by DOL attorneys
Architecture
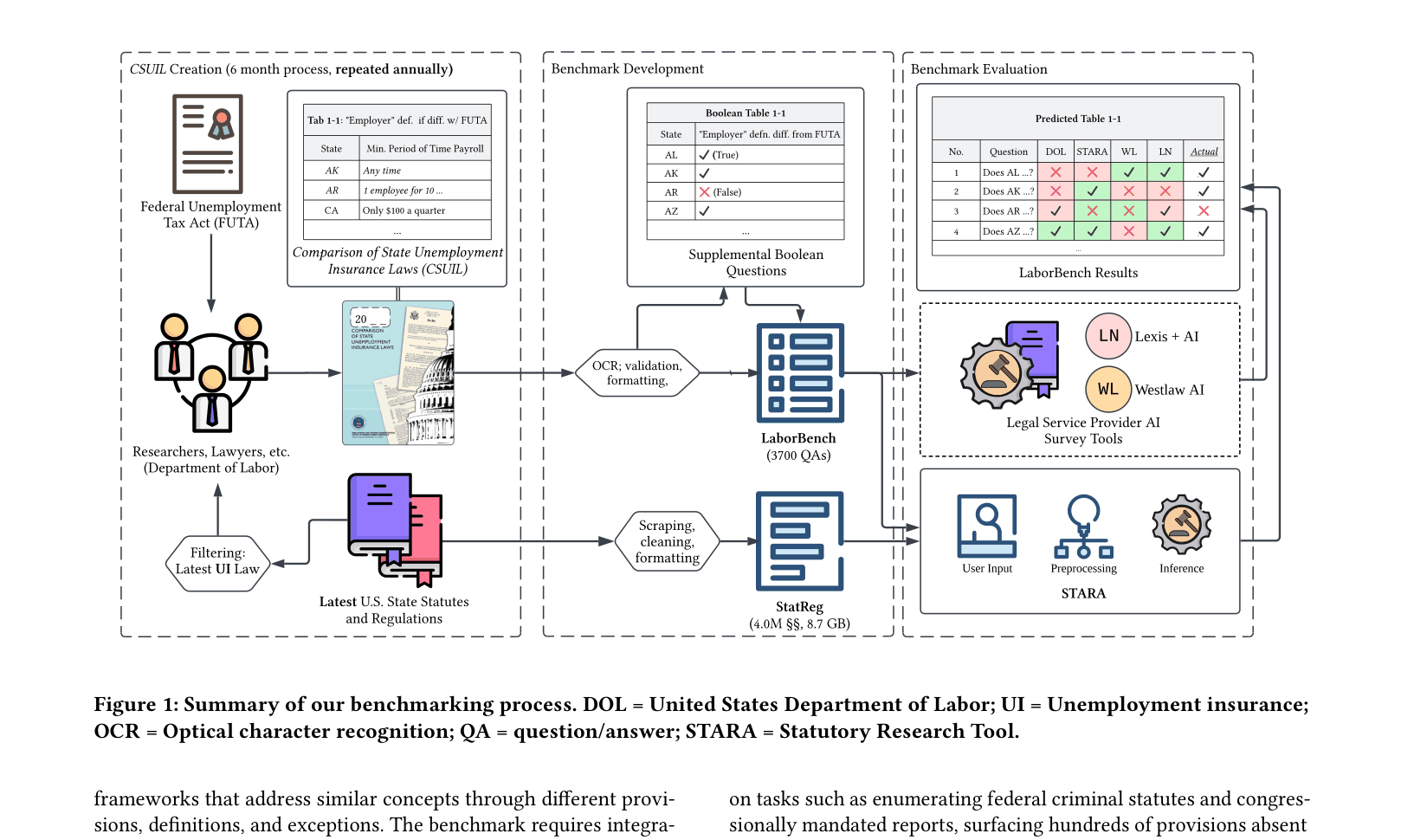
The benchmarking pipeline: converting DOL surveys into LaborBench, processing state statutes via OCR and cleaning, and running three systems (STARA, Westlaw AI, Lexis+ AI) for evaluation
Evaluation Highlights
- STARA achieves 91% F1 score (corrected) on multi-jurisdictional statutory questions, outperforming the best prior RAG baseline (67% F1) by 24 percentage points
- Westlaw AI and Lexis+ AI perform poorly with F1 scores of 64% and 41% respectively, often worse than a simple majority-class baseline (67% F1)
- Analysis reveals significant human error in 'ground truth': STARA identified 135 valid statutory provisions across 50 states that were missed in the official DOL compilation
Breakthrough Assessment
9/10
Demonstrates that specialized RAG can surpass human expert thoroughness in legal domains. The finding that AI discovered widespread omissions in federal agency reports is a significant validation of AI-assisted legal research.