📝 Paper Summary
RAG Evaluation
Benchmark Datasets
RAGBench is a 100k-example multi-domain benchmark that facilitates granular RAG evaluation via the TRACe framework, showing that fine-tuned small language models outperform large LLM judges.
Core Problem
Comprehensive evaluation of RAG systems is hindered by the lack of unified benchmarks and reliance on disjoint, irreproducible evaluation criteria (like context relevance vs. answer faithfulness) that vary across studies.
Why it matters:
- RAG systems in production are prone to hallucinations and retrieval failures, necessitating rigorous fine-tuning and evaluation.
- Current benchmarks are small, domain-specific, or lack granular annotations, making it hard to compare different RAG configurations or evaluation approaches.
- Zero-shot LLM-based evaluation (e.g., GPT-4 as a judge) is expensive and often inconsistent compared to ground-truth benchmarks.
Concrete Example:
A RAG system might retrieve relevant documents but fail to use them (low Utilization), or use them but include hallucinations (low Adherence). Existing metrics like 'correctness' are too coarse to distinguish these failure modes, preventing developers from knowing whether to fix the retriever or the generator.
Key Novelty
TRACe Framework & RAGBench Dataset
- Constructs a massive (100k) dataset from 12 heterogeneous sources (finance, legal, biomedical) converted into a standardized RAG format with 'silver' labels generated by GPT-4 and validated by humans.
- Introduces TRACe (uTilization, Relevance, Adherence, Completeness) to granularly measure which specific tokens in the context are relevant and which are actually used by the generator.
- Demonstrates that a small, fine-tuned DeBERTa model can outperform few-shot GPT-4 in predicting these fine-grained evaluation metrics.
Architecture
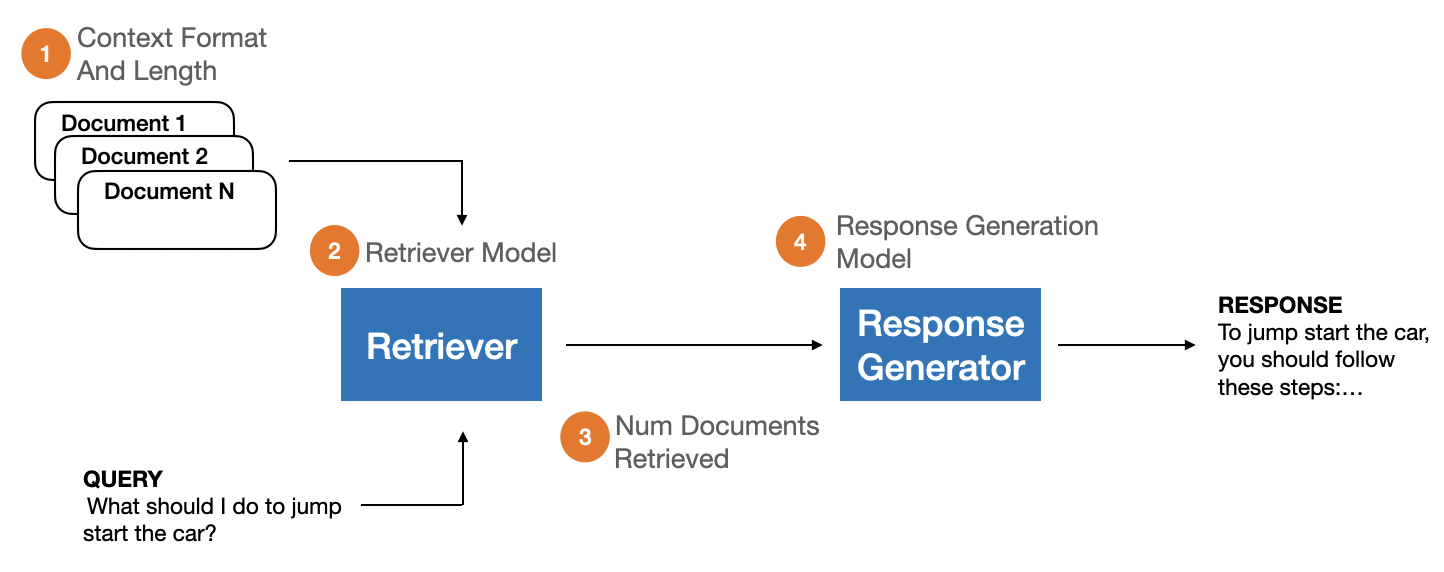
Conceptual diagram of the RAG pipeline and the variables varied in RAGBench construction.
Evaluation Highlights
- Fine-tuned DeBERTa-large (400M parameters) outperforms GPT-4-based judges on RAG evaluation tasks across multiple domains.
- The proposed TRACe metrics achieve 93% example-level and 95% span-level agreement with human judgments on the DelucionQA test split.
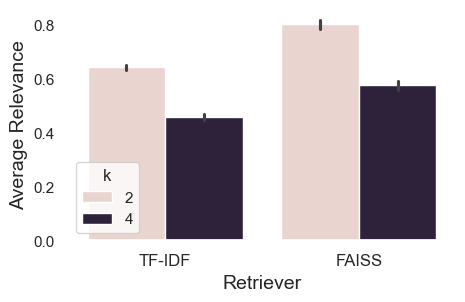
- RAGBench covers 5 distinct domains (biomedical, general knowledge, legal, customer support, finance) with context lengths ranging from 100 to 11k tokens.
Breakthrough Assessment
8/10
Significantly scales up RAG evaluation resources (100k examples vs typical <5k) and provides a compelling case for using small, specialized evaluation models over expensive LLM judges.