📝 Paper Summary
Knowledge Editing (KE)
Context Robustness
Factuality in LLMs
CoRE improves knowledge editing robustness by minimizing the variance of hidden states across diverse prefix contexts during the editing process, preventing models from reverting to outdated facts when distracted by conversation history.
Core Problem
Existing Knowledge Editing (KE) evaluations test models in isolation, but in real conversations, preceding contexts (especially those with relevant entities) often distract the model, causing it to revert to the original, outdated knowledge.
Why it matters:
- Real-world applications like chatbots always involve dialogue history, making context-free evaluation unrealistic and overly optimistic
- Standard KE methods fail significantly when a 'distractor' context is present, undermining their reliability for correcting hallucinations or updating facts
- Prior benchmarks (CounterFact, MQuAKE) do not systematically evaluate the interference caused by semantically relevant preceding contexts
Concrete Example:
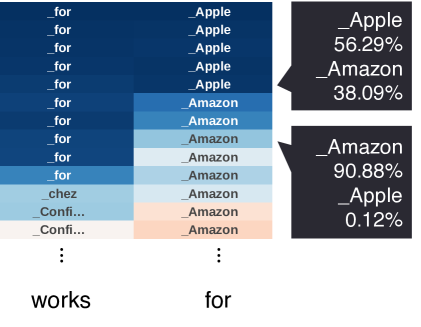
If a model is edited to know 'Tim Cook works for Amazon' (instead of Apple), a preceding user question like 'Who's in charge of developing the iPhone?' may trigger the original association with Apple, causing the model to ignore the edit and output 'Apple'.
Key Novelty
Context Robust Editing (CoRE) & CHED Benchmark
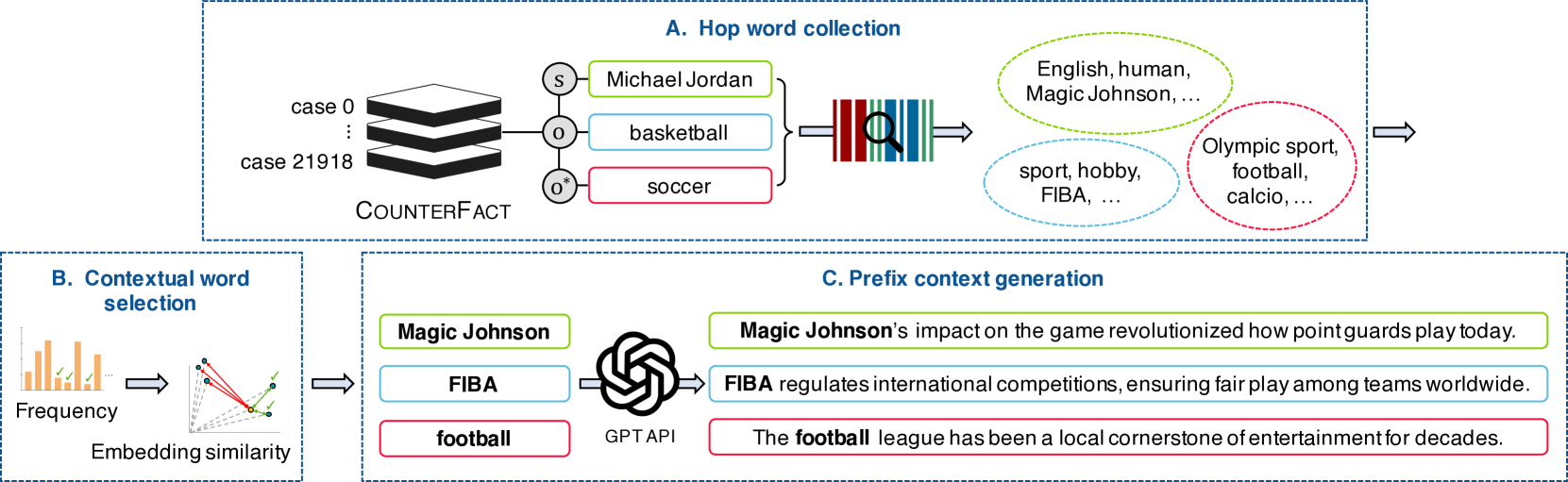
- Introduces CHED, a dataset of 'hop word' prefix contexts designed to distract the model by including entities semantically related to the original or edited fact
- Proposes CoRE, a method that modifies the MEMIT objective by adding a regularization term that forces the model's hidden states to remain consistent (low variance) regardless of the preceding context
Architecture
Overview of the CoRE method. It illustrates the extraction of key-value pairs using relevant prefixes (s, o, o*) and the regularization of value vectors.
Evaluation Highlights
- CoRE outperforms MEMIT by +17.2% in edit success rate on the CHED benchmark when facing distractive 'hop word' contexts
- Significantly reduces the performance gap between context-free and contextual editing compared to baselines like ROME and MEMIT
- Maintains high performance on general capabilities (downstream tasks) and fluency, showing that robust editing does not degrade the model's overall quality
Breakthrough Assessment
8/10
Identifies a critical failure mode in current KE methods (context sensitivity) and provides both a rigorous benchmark and an effective solution. The focus on 'hop words' as distractors is a strong insight.