📝 Paper Summary
Modularized RAG pipeline
Retrieval
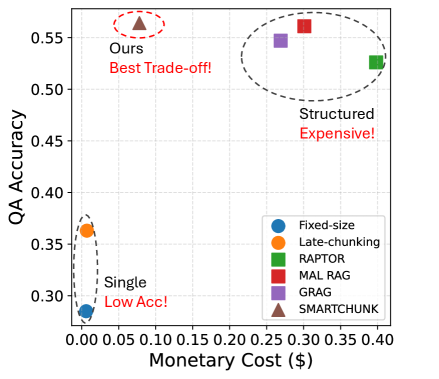
SmartChunk improves retrieval accuracy and reduces cost by dynamically predicting optimal chunk sizes per query and generating compressed high-level embeddings without expensive text summarization.
Core Problem
Static chunking strategies (fixed-size splits) are brittle: small chunks lose context, large chunks introduce noise, and no single size works for all queries.
Why it matters:
- Retrieval quality is highly sensitive to chunk size, leading to 'lost-in-the-middle' effects or irrelevant context
- Tree/graph-based RAG methods improve reasoning but introduce substantial computational cost and complexity
- Standard RAG pipelines struggle to balance accuracy with the monetary cost and latency of processing long documents
Concrete Example:
Static pipelines split documents into short, fixed-size chunks (e.g., 100 tokens). If a query requires high-level thematic understanding (spanning 2000 tokens), small chunks miss the broader context. If a query asks for a specific detail, large chunks drown the answer in noise.
Key Novelty
Query-Adaptive Hierarchical Retrieval with STITCH Training
- Uses a lightweight Planner to predict the specific range of chunk levels (e.g., sentence vs. section) needed for each query, pruning the search space
- Introduces a Compressor module that creates embeddings for high-level text spans directly from low-level chunks, avoiding the high cost of LLM-based text summarization
- Trains the Planner using STITCH, a loop alternating between Reinforcement Learning and Imitation Learning to handle sparse rewards and lack of ground truth
Architecture

The SmartChunk framework workflow (Left) and the STITCH training loop (Right).
Evaluation Highlights
- Outperforms state-of-the-art RAG baselines across 5 QA benchmarks while reducing monetary cost by ~30%
- Demonstrates strong scalability to larger corpora and consistent gains on out-of-domain datasets
- Planner operates with low latency (≤1s), making the adaptive overhead negligible compared to generation gains
Breakthrough Assessment
8/10
Offers a practical solution to the 'chunk size' hyperparameter problem by making it dynamic. The STITCH training loop is a clever methodological contribution for optimizing non-differentiable pipeline decisions.