📝 Paper Summary
Visual Document Retrieval-Augmented Generation (VD-RAG)
Multimodal Reasonining
Visual Evidence Attribution
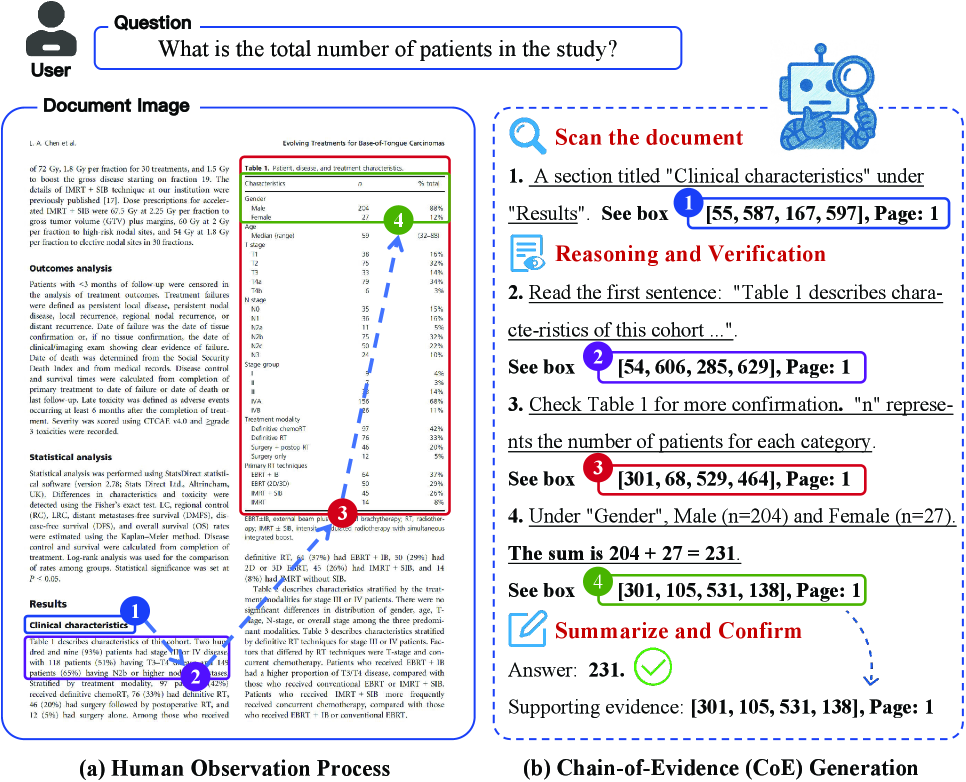
Chain-of-Evidence (CoE) combines Chain-of-Thought with reinforcement learning to make vision-language models explicitly ground intermediate reasoning steps in specific document regions.
Core Problem
Current Vision-Language Models (VLMs) in RAG scenarios lack traceable reasoning and often hallucinate, directly jumping to answers without showing the progressive search process used by humans.
Why it matters:
- Without reliable attribution, users cannot verify if the model's answer is based on actual document content or hallucination
- Existing methods link answers to evidence only at the end, failing to reveal the intermediate reasoning path (traceability) crucial for complex multi-step queries
- Training data for step-by-step visual attribution is scarce and expensive to annotate manually
Concrete Example:
In a multi-page document query, a standard VLM might correctly answer '25%' but fail to show which table or paragraph it came from. Or, it might cite the wrong chart entirely. Humans solve this by first finding the chapter, then the section, then the specific table—a process standard VLMs do not replicate.
Key Novelty
Look-As-You-Think (LAT) Reinforcement Learning Framework
- Formalizes 'Chain-of-Evidence' (CoE) where reasoning steps are explicitly linked to bounding boxes and page indices (coarse-to-fine grounding)
- Uses a reinforcement learning approach (LAT) with a 'stepwise attribution reward' that checks if the image region inside a predicted bounding box semantically matches the reasoning text
- Optimizes for both answer accuracy and the validity of the evidence trail, encouraging the model to 'look' at the right place while 'thinking'
Architecture
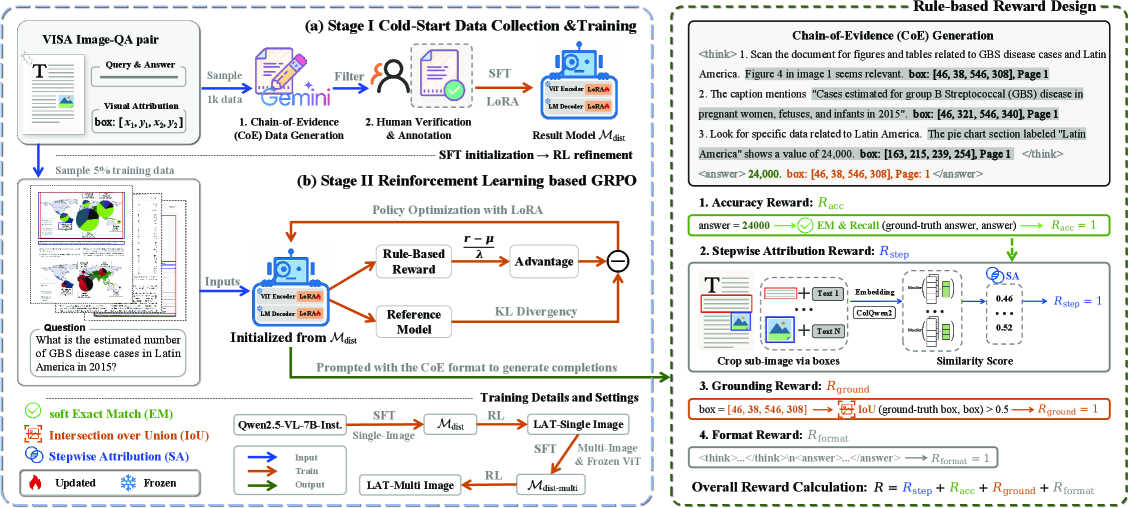
The LAT training pipeline, showing Stage I (Cold-Start SFT) and Stage II (Reinforcement Learning with GRPO).
Evaluation Highlights
- Achieves +8.23% improvement in soft Exact Match (EM) over vanilla Qwen2.5-VL-7B-Instruct on VISA benchmarks
- Improves Intersection over Union (IoU@0.5) by 47.0%, significantly boosting the precision of visual evidence localization
- Outperforms supervised fine-tuning baselines, demonstrating that RL generalizes better than simple imitation of grounded reasoning traces
Breakthrough Assessment
8/10
Significantly advances explainable AI in multimodal RAG by enforcing verifiable intermediate steps via RL, addressing the critical 'black box' reasoning problem in VLMs.