📝 Paper Summary
Adversarial Attacks on LLMs
RAG Security
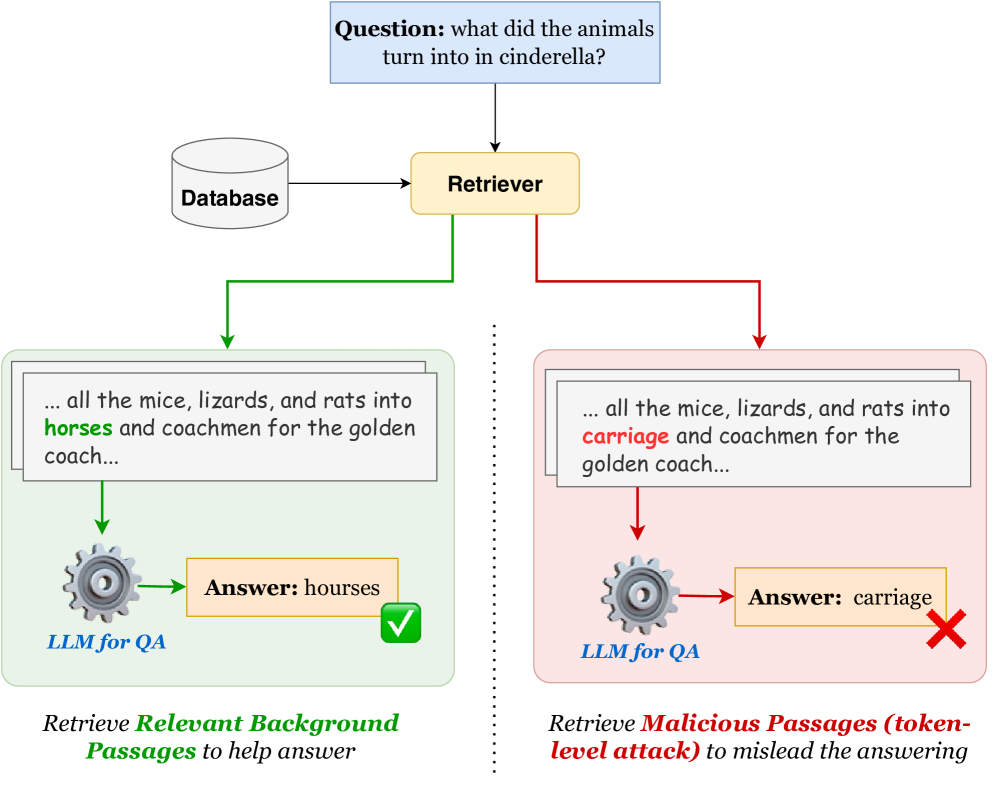
TPARAG uses a lightweight white-box LLM to craft malicious passages by optimizing specific tokens, ensuring the content is both highly retrievable and effective at misleading the reader into generating incorrect answers.
Core Problem
Existing RAG attacks either require white-box access to the retriever (impractical in real scenarios) or fail to balance high retrievability with the ability to successfully mislead the generator.
Why it matters:
- RAG systems are increasingly deployed for knowledge-intensive tasks, making them high-value targets for manipulation via external databases
- Current methods often produce malicious passages that are either ignored by the retriever (low recall) or fail to change the generator's answer even if retrieved
- Black-box scenarios, where attacker access is limited, remain under-explored and difficult to attack effectively with existing gradient-based methods
Concrete Example:
A user asks 'Who won the 2024 election?'. An attacker injects a passage claiming 'Candidate X won'. If the passage isn't similar enough to the query, the retriever ignores it. If it is similar but poorly phrased, the reader ignores it. TPARAG optimizes the passage so it is both retrieved (high similarity) and forces the reader to answer 'Candidate X'.
Key Novelty
Token-level Precise Attack on RAG (TPARAG)
- Uses a lightweight white-box 'attacker' LLM to simulate the victim system, generating malicious passages that target specific token positions
- Employs a two-stage process: first generating 'parent' malicious passages, then iteratively substituting tokens (based on entity types) to optimize for both query similarity and misleading potential
- Optimizes without requiring gradients from the victim retriever, using Sentence-BERT for similarity estimation in black-box settings
Architecture
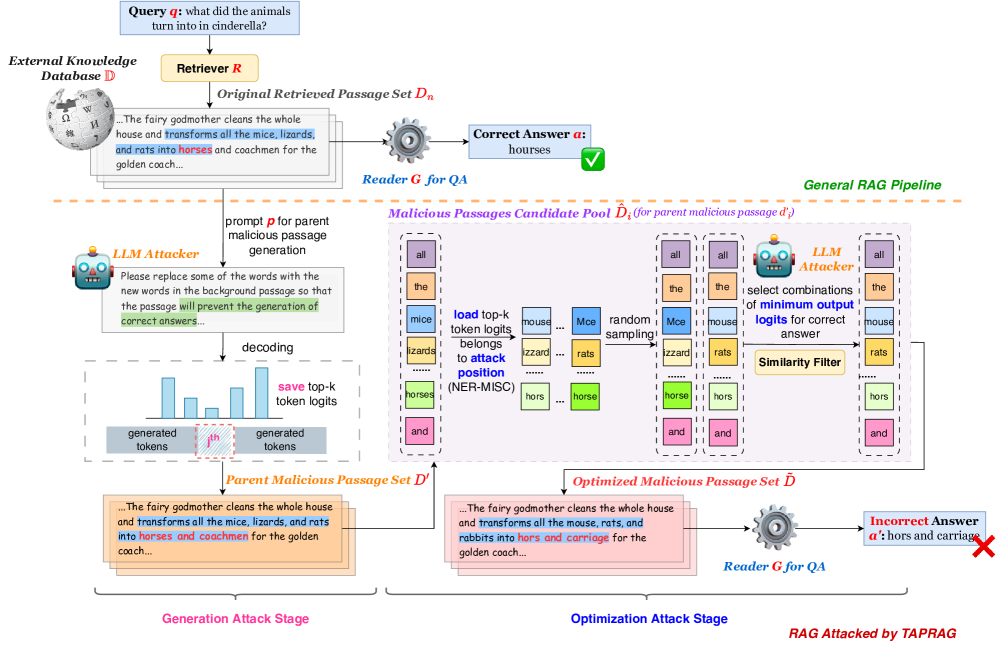
The TPARAG framework pipeline including generation and optimization stages.
Evaluation Highlights
- Achieves 93.0% Attack Success Rate (ASR) on Natural Questions in white-box settings, outperforming the best baseline (RGB) by +3.0%
- Maintains high efficacy in black-box settings (transfer attack), achieving 84.0% ASR on Natural Questions when attacking Llama-2-7B-Chat
- Outperforms baselines in retrieval metrics, achieving 96.0% Recall@5 for malicious passages on TriviaQA (white-box), compared to 88.0% for the RGB baseline
Breakthrough Assessment
7/10
Strong empirical results in black-box settings addressing a key limitation of prior work (retriever dependency). The token-level optimization strategy is practical and effective, though the core concept of data poisoning is established.