📝 Paper Summary
Knowledge-Augmented Image Captioning
Modularized RAG pipeline
Multimodal RAG
MsRAG enables Language-Visual Large Models to generate knowledge-rich image captions without user queries by combining object-level visual search, offline domain databases, and a visual-text alignment mechanism.
Core Problem
Existing RAG methods for vision-language models rely heavily on user queries to retrieve relevant information, making them ineffective for image captioning tasks where no explicit text query exists.
Why it matters:
- Standard pre-trained models suffer from hallucinations or lack specific knowledge about rare objects (e.g., specific cultural relics or products)
- Current RAG systems cannot infer user intent without a query, leading to retrieval of irrelevant or noisy information
- Automatic generation of high-quality, knowledge-rich captions is crucial for training better multimodal models and real-world applications
Concrete Example:
When captioning an image of four football players without a user query, a standard model just says 'four German football players.' MsRAG automatically identifies each face, retrieves their names (e.g., 'Bastian Schweinsteiger'), aligns them to their positions (left-to-right), and generates a caption naming each specific player.
Key Novelty
Object-Level Multi-Source Retrieval without Queries
- Retrieves information based on detected visual objects rather than text queries, using both online search engines (for timeliness) and offline databases (for domain depth like cultural relics)
- Visual-RAG Alignment: Explicitly maps text retrieval results to specific image regions using visual markers (bounding boxes/numbers) in the prompt, preventing the model from attributing facts to the wrong object
Architecture
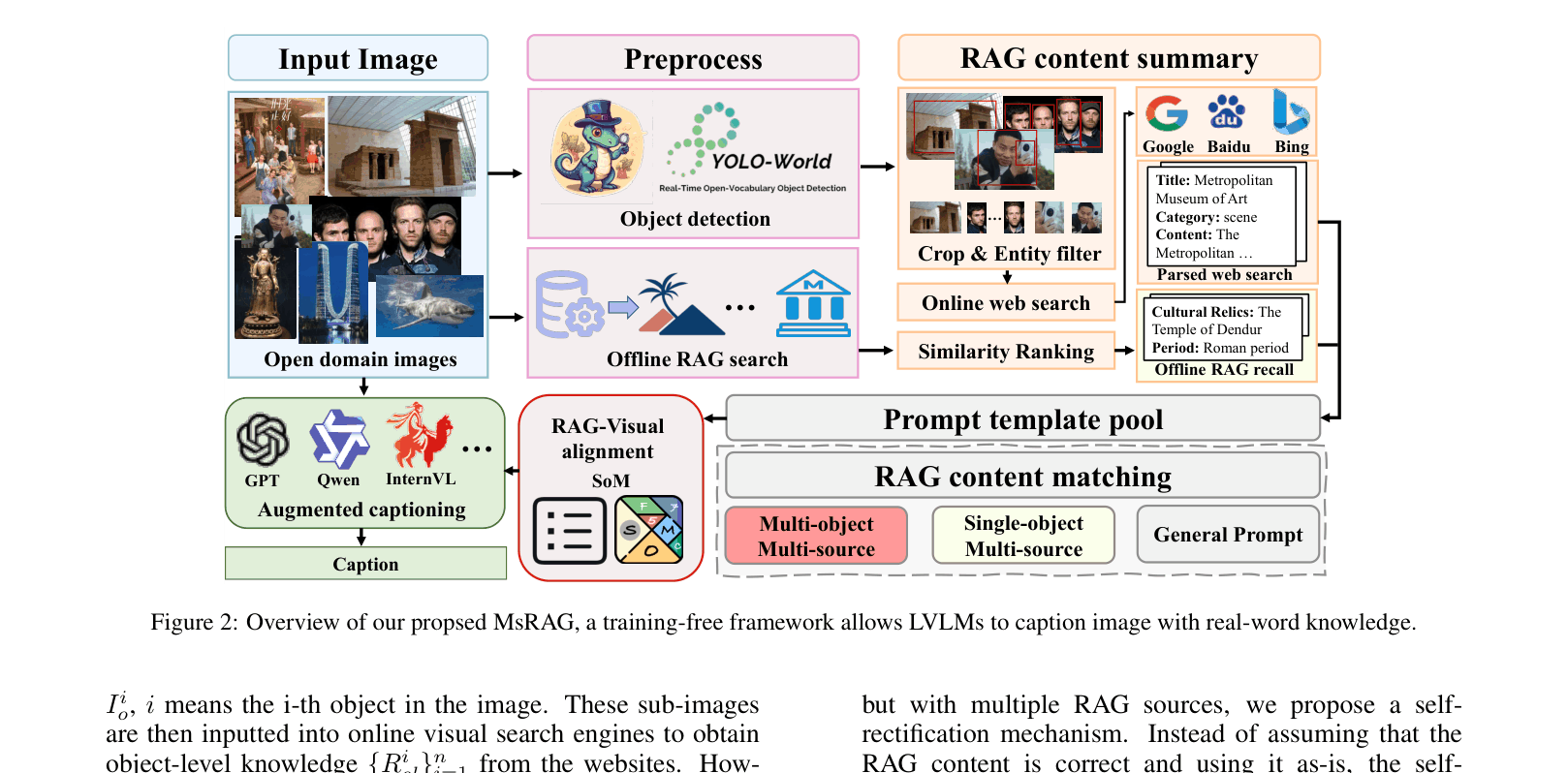
The complete MsRAG pipeline processing an input image to generate a caption.
Evaluation Highlights
- Outperforms standard mRAG by +21.9% on CIDEr score using GPT-4o on the KAC-dataset
- Achieves higher user preference scores in human evaluation across all domains, particularly in cultural relics (+3.24) and products (+3.18) compared to mRAG
- Boosts Qwen2-VL performance on Kale dataset by +3.1 in BLEU-4 compared to mRAG baseline
Breakthrough Assessment
7/10
Addresses a specific but critical gap (query-free RAG) with a practical pipeline. The Visual-RAG alignment is a clever adaptation of Set-of-Marks for RAG. While architectural novelty is moderate (pipeline of existing tools), practical utility for captioning is high.
