📝 Paper Summary
Graph-based RAG pipeline
Modularized RAG pipeline
FRAG-KEDA is a modular Graph RAG engine that enhances LLM reliability by integrating knowledge graphs into the retrieval process, demonstrated across seven real-world applications from finance to automotive support.
Core Problem
Traditional vector-based RAG struggles with multi-hop reasoning, connecting dispersed information, and understanding complex semantic concepts, leading to incomplete answers and hallucinations in specialized domains.
Why it matters:
- Financial institutions face high risks when AI fails to connect scattered regulatory clauses (e.g., DORA compliance), leading to legal liabilities.
- In safety-critical domains like automotive maintenance, retrieving the wrong manual section due to keyword mismatch can endanger users.
- Enterprises waste resources (e.g., €1.2M in duplicate proposals) because standard search cannot identify non-obvious relationships between researchers across siloed institutes.
Concrete Example:
A user asks: 'Can the risk weight of 65% also be applied to companies in the financial sector...?' Traditional RAG retrieves isolated risk weights but fails to connect the definition of 'corporates' found in a different section, leading to an incorrect or incomplete compliance answer.
Key Novelty
FRAG-KEDA (Modular Graph RAG Engine)
- Deploys a modular reference architecture that standardizes three stages: Graph-based Indexing (constructing KGs from text), Graph-guided Retrieval (using entity traversal or community summaries), and Graph-enhanced Generation.
- Introduces dual operational modes: 'Schemaless' (LLM-extracted topology) for rapid deployment and 'Schema-First' (ontology-guided) for high-precision domains like legal compliance.
Architecture
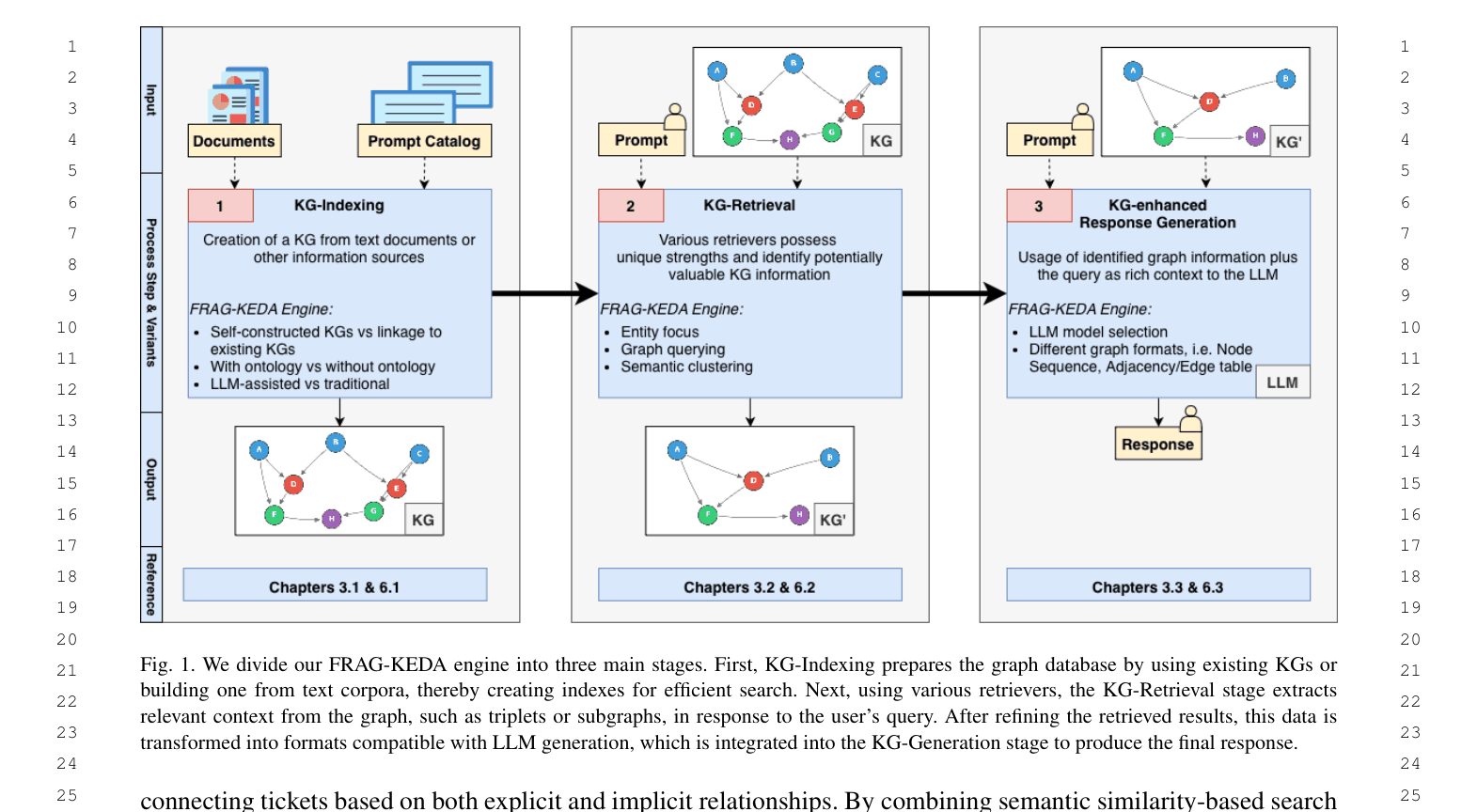
The FRAG-KEDA engine architecture, illustrating the three-stage pipeline: KG-Indexing, KG-Retrieval, and KG-Generation.
Evaluation Highlights
- Graph RAG achieved up to 84.16% preference (vs. 12.87% for Traditional RAG) in the 'Comprehensiveness' metric for the Wenn Fraunhofer Wüsste application.
- In the EU Regulation QA Agent, Graph RAG outperformed Traditional RAG on 'Diversity' with 77.61% win rate versus 18.91%.
- For the Car Owners Manual Assistant, Graph RAG achieved 67.11% on 'Empowerment' compared to 28.86% for Traditional RAG.
Breakthrough Assessment
7/10
Provides valuable empirical evidence and a unified engine for Graph RAG across diverse real-world scenarios, though the core algorithmic innovation is an integration of existing techniques rather than a fundamental new model architecture.