📝 Paper Summary
Memory recall
Modularized RAG pipeline
PerCache reduces mobile RAG latency by predictively caching both query-answer pairs and intermediate QKV tensors, leveraging the observation that users frequently repeat queries and retrieve overlapping knowledge chunks.
Core Problem
Mobile RAG applications suffer from high latency due to limited on-device resources and lengthy prompts, while existing caching solutions (KV or semantic cache) fail because they target only single stages and reactively populate caches, leading to low hit rates under sparse user query patterns.
Why it matters:
- Mobile devices have limited parallel computing capabilities, making both prefilling and decoding stages significant latency bottlenecks that single-stage caches cannot fully address.
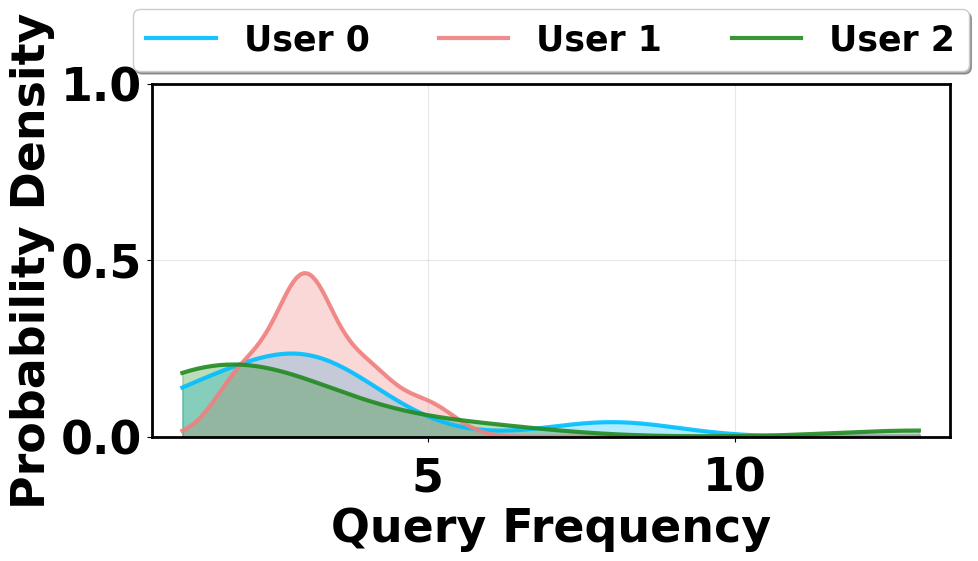
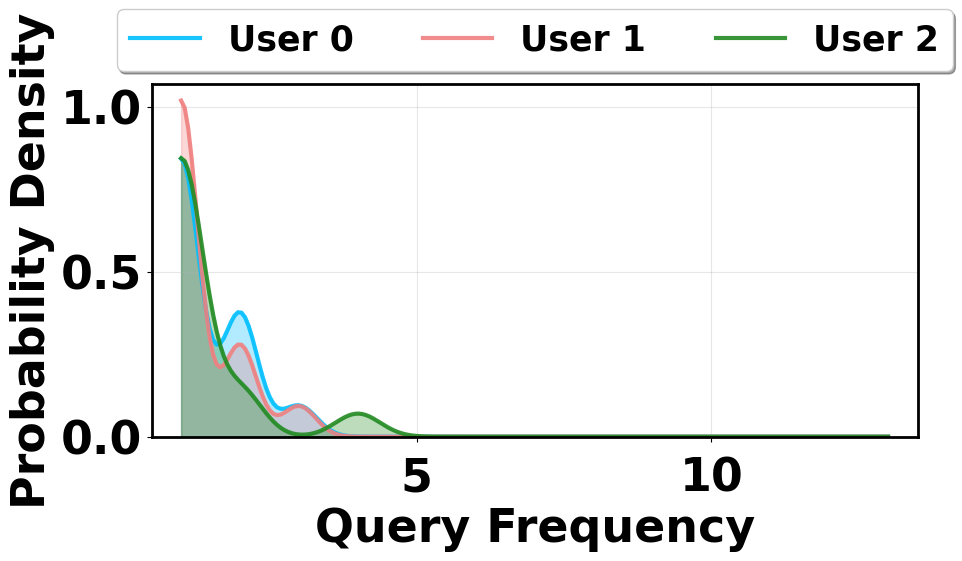
- Single-user mobile queries are sparse and semantically varied compared to cloud settings, causing reactive caches to remain cold and ineffective.
- Privacy-sensitive applications like meeting assistants require low latency to be usable, but current approaches incur delays up to 10x longer than standard queries due to retrieval overhead.
Concrete Example:
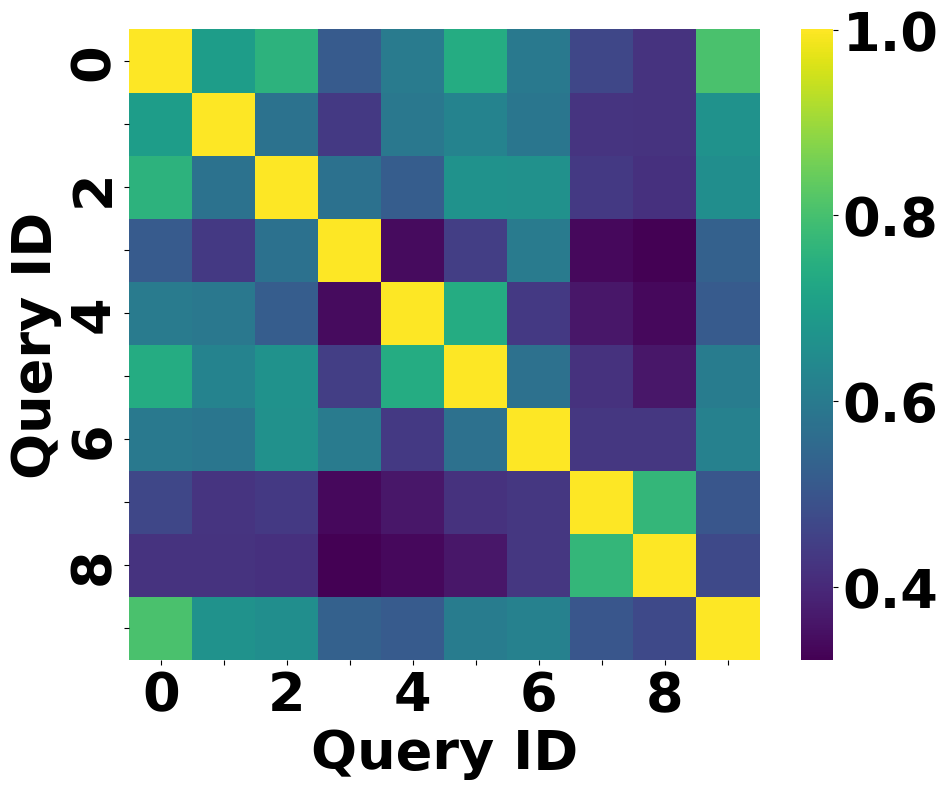
A user asks 'When is the rehearsal?' and later 'Is time of rehearsal given?'. A standard KV cache misses the second query because the prompts differ slightly, while a semantic cache misses if the similarity is below a high threshold. Meanwhile, both queries retrieve the same document chunks, but standard systems re-compute the attention tensors for these chunks from scratch every time.
Key Novelty
Predictive Hierarchical Caching (PerCache)
- Hierarchical structure: Caches results at two levels—semantic QA pairs (to skip inference entirely) and QKV tensors of retrieved chunks (to skip prefilling computation)—maximizing reuse across different stages.
- Predictive population: Instead of waiting for users to ask questions, the system proactively generates potential future queries based on knowledge content and history during idle time to populate the cache.
- Resource-aware scheduling: Dynamically manages cache size and converts between QA and QKV storage based on real-time device memory and computation constraints.
Architecture
Overview of PerCache system architecture, detailing the hierarchical cache (QA Bank + Knowledge Bank) and the predictive population mechanism.
Evaluation Highlights
- Reduces end-to-end latency by up to 34.4% compared to the best-performing baseline (RAGCache) across various applications.
- Improves cache hit rates for QKV cache by up to 37.56% and QA bank by up to 13.8% using the predictive mechanism.
- Maintains optimal latency under dynamic resource changes by elastically bypassing cache population (reducing overhead by 14.12%).
Breakthrough Assessment
7/10
Significant practical contribution for on-device AI. It addresses the specific 'sparsity' problem of single-user caches with a novel predictive mechanism, though the core concept combines existing caching strategies (semantic + KV).