📝 Paper Summary
Open-domain Question Answering
Ambiguity Handling in QA
Reinforcement Learning for Search
A2SEARCH uses an automated data pipeline to find valid alternative answers for ambiguous questions, then trains a search agent via reinforcement learning to retrieve multiple correct answers simultaneously.
Core Problem
Standard QA benchmarks assume a single correct answer, penalizing models that find valid alternative answers to ambiguous questions, which leads to misleading reward signals during RL training.
Why it matters:
- Real-world questions often have multiple valid answers depending on interpretation or reasoning paths
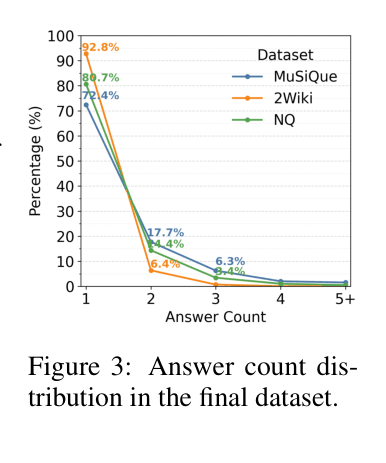
- 27.6% of questions in the MuSiQue benchmark actually admit multiple valid answers, but existing evaluations treat them as incorrect
- Current RL pipelines reward only the single annotated 'gold' answer, systematically understating true model capabilities and discouraging thorough search
Concrete Example:
For the question 'Who is the owner of the record label of the performer of What Kind of Love?', the benchmark lists only 'Warner Music Group'. However, the performer (Rodney Crowell) released works under multiple labels, making 'Sony Music Entertainment' (parent of Columbia Records) an equally valid answer that standard models are penalized for generating.
Key Novelty
Annotation-Free Ambiguity-Aware RL Training
- Automated Data Pipeline: Detects ambiguity by generating diverse answer trajectories from multiple models and verifying them against evidence using LLM judges, without manual annotation
- AnsF1 Reward: Replaces binary correct/incorrect rewards with an Answer-level F1 score that rewards coverage of multiple valid answers (recall) while penalizing hallucination (precision)
Architecture
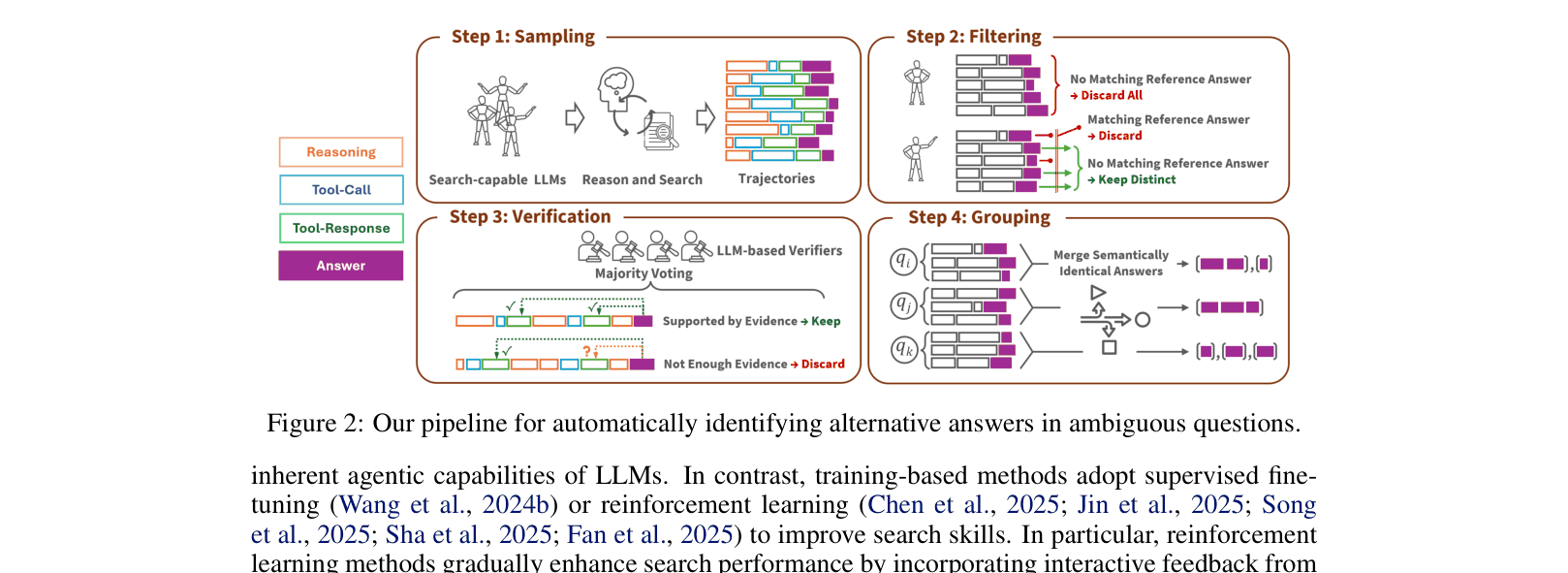
The automated data construction pipeline for identifying alternative answers.
Evaluation Highlights
- Achieves 48.4% AnsF1@1 on average across four multi-hop benchmarks with A2SEARCH-7B (single rollout), outperforming the much larger ReSearch-32B (46.2%)
- Surpasses specialized baselines on AmbigQA (a human-annotated ambiguity benchmark) despite not being trained on it, showing robust generalization
- Identifies alternative answers for 19.0% of training questions automatically, extending the effective supervision signal beyond single gold references
Breakthrough Assessment
8/10
Significant advance in handling ambiguity without human labeling. Demonstrates that acknowledging ambiguity improves general QA performance, outperforming larger models.