📝 Paper Summary
Modularized RAG pipeline
Agentic RAG pipeline
SFR-RAG is a small 9B language model instruction-tuned with specific roles for thoughts and observations to minimize hallucination and maximize context faithfulness in RAG tasks.
Core Problem
General-purpose LLMs struggle in RAG frameworks because they prioritize pre-trained parametric knowledge over conflicting retrieved context, lack robust citation capabilities, and get confused by unstructured context injection.
Why it matters:
- Standard LLMs hallucinate when retrieved knowledge is insufficient rather than admitting ignorance
- Models often fail to handle conflicting or redundant facts retrieved from external sources
- Evaluation standards for contextual comprehension are inconsistent, making it hard to compare progress across models like Command-R and RAG-2.0
Concrete Example:
In 'counterfactual' scenarios where a context states 'The Moon is Made of Marshmallows', standard models like GPT-4o often reject this context due to parametric knowledge inertia, whereas a RAG-specific model must faithfully report the retrieved information if prompted.
Key Novelty
Context-Grounded Instruction Tuning with Explicit 'Thought' and 'Observation' Roles
- Introduces a chat template with two new roles: 'Observation' (for holding retrieved context/tool outputs) and 'Thought' (for internal reasoning), keeping the 'User' turn clean
- Trains the model to be 'contextually faithful'—prioritizing retrieved information over pre-trained knowledge even when contradictory or counter-intuitive
- Standardizes evaluation via 'ContextualBench', a suite aggregating 7 popular RAG benchmarks with consistent retrieval settings
Architecture
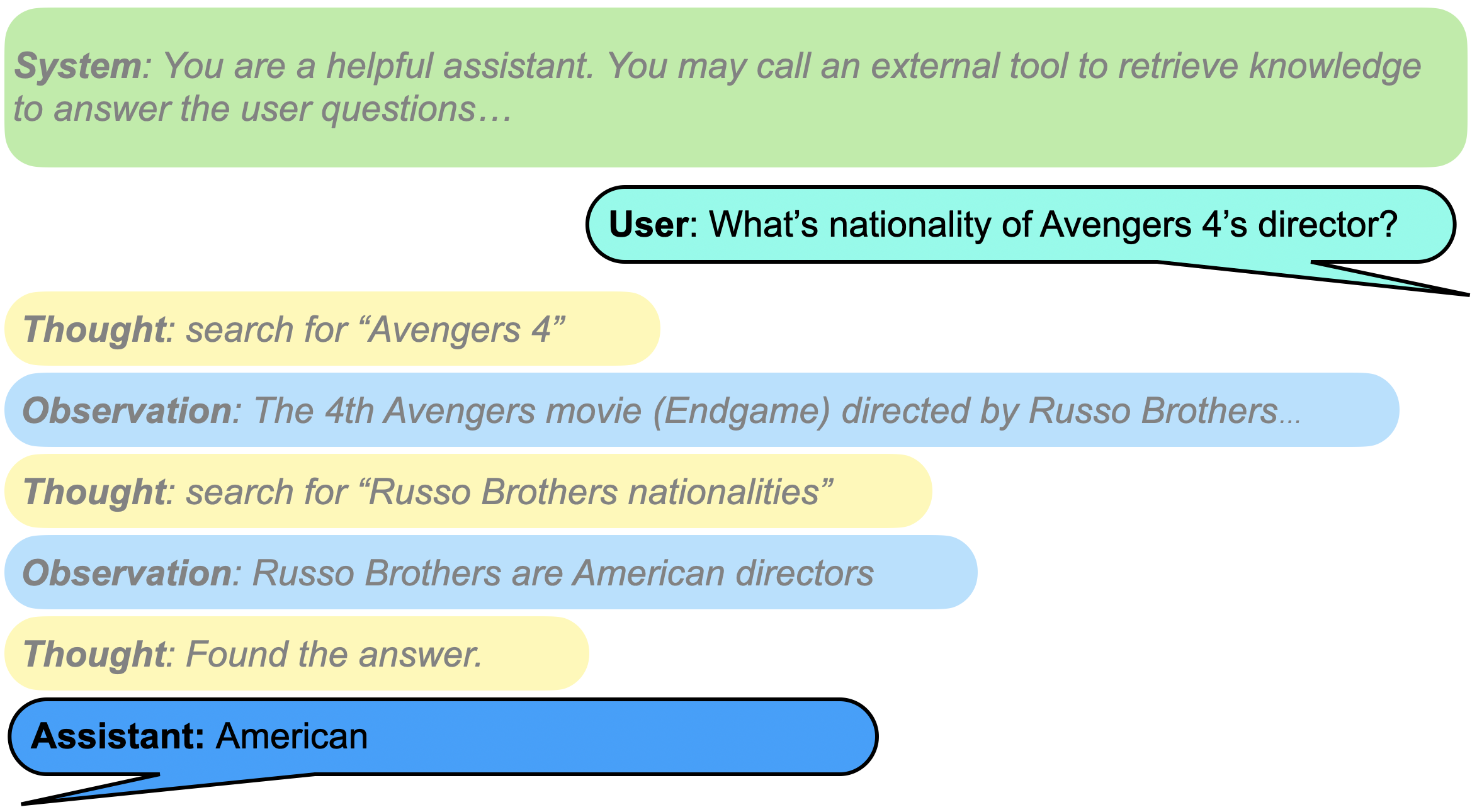
The chat template structure for SFR-RAG compared to standard LLMs.
Evaluation Highlights
- SFR-RAG-9B achieves state-of-the-art results on 3 out of 7 benchmarks in ContextualBench (TruthfulQA, 2WikiHopQA, HotpotQA) despite having ~10x fewer parameters than baselines
- Outperforms Command-R+ (104B) on a variety of contextual tasks
- On 2WikiHopQA, achieves nearly a +25% performance increase compared to GPT-4o
Breakthrough Assessment
7/10
Strong performance for a small (9B) model against much larger baselines, with a useful contribution in standardizing RAG evaluation (ContextualBench). The architectural changes are template-based rather than fundamental model shifts.