📊 Experiments & Results
Evaluation Setup
Layer-wise ablation study across diverse tasks and metrics.
Benchmarks:
- MMLU (General Knowledge)
- HellaSwag (Commonsense Reasoning)
- MathQA (Mathematical Problem Solving)
- GSM8K (Chain-of-Thought Reasoning)
- KV Retrieval (Retrieval)
Metrics:
- Accuracy (acc)
- Relative Accuracy Change (Delta mu)
- Cross-entropy based accuracy (acc_ce)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Knowledge and retrieval tasks show heavy reliance on shallow layers, with deep layers contributing little. | ||||
| HellaSwag | Accuracy (acc_ce) | 0.00 | -0.50 | -0.50 |
| KV Retrieval | Accuracy (Delta mu) | 0.00 | -0.80 | -0.80 |
| Reasoning tasks using generation metrics reveal critical dependencies on deep layers. | ||||
| GSM8K (1-shot CoT) | Accuracy (Delta mu) | 0.00 | -0.60 | -0.60 |
| GSM8K | Accuracy (Delta acc) | 0.00 | -0.60 | -0.60 |
| Distillation redistributes reasoning capabilities, involving middle layers more than the base model. | ||||
| GSM8K CoT | Accuracy (Delta mu) | 0.00 | -0.06 | -0.06 |
Experiment Figures
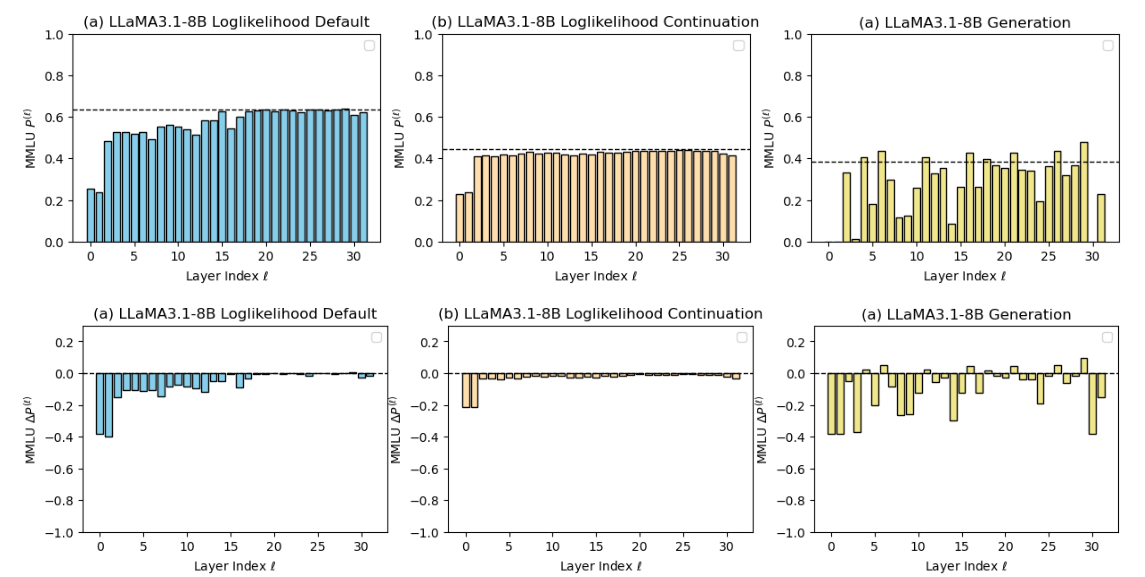
Performance degradation on MMLU across layers using different evaluation metrics.
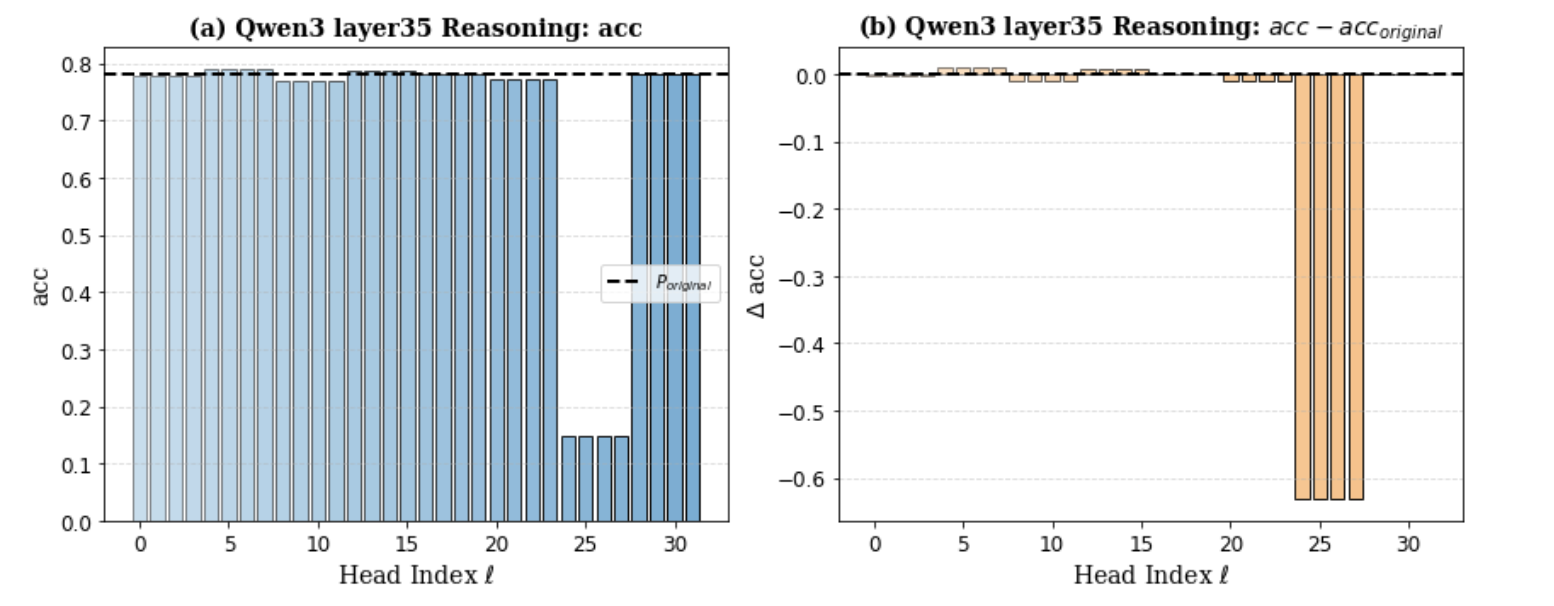
Head pruning results on Qwen3-8B Layer 35 for GSM8K.
Main Takeaways
- Evaluation protocol determines 'layer importance': Likelihood metrics suggest deep layers are redundant, while generation metrics show they are essential.
- Capabilities are localized: Retrieval/Knowledge is concentrated in shallow layers (and specific shallow heads), while Reasoning is concentrated in middle/deep layers.
- Distillation effect: Distilled models are more robust in deep layers but rely heavily on shallow-to-mid representations to maintain their performance gains.
- Sparse Criticality: In deep layers, reasoning often depends on a very small subset of specific attention heads (e.g., in Layer 35 of Qwen).