📝 Paper Summary
Disaster Response QA
Domain-Specific Benchmarking
DisastQA introduces a large-scale, human-verified disaster management benchmark that evaluates LLMs' reasoning under retrieval noise and measures factual completeness using a novel keypoint-based protocol.
Core Problem
Existing QA benchmarks focus on general knowledge or clean evidence, failing to capture the fragmented, noisy, and high-stakes nature of information in disaster management.
Why it matters:
- Disaster response requires synthesizing information from noisy, incomplete sources (social media, bulletins), which standard clean-context benchmarks do not simulate
- Current benchmarks prioritize multiple-choice accuracy or surface-level lexical overlap (ROUGE), failing to measure the factual completeness essential for decision-critical advice
- Reliability gaps in high-stakes scenarios remain unmeasured as models are rarely tested against realistic retrieval noise or specific disaster constraints
Concrete Example:
A decision-maker needs a complete list of evacuation routes and shelter locations. A standard model might provide a fluent but incomplete answer missing a crucial closed bridge. DisastQA's keypoint metric penalizes this missing fact, whereas ROUGE might score it highly for lexical overlap.
Key Novelty
Tri-Level Evidence Evaluation & Keypoint-Based Completeness
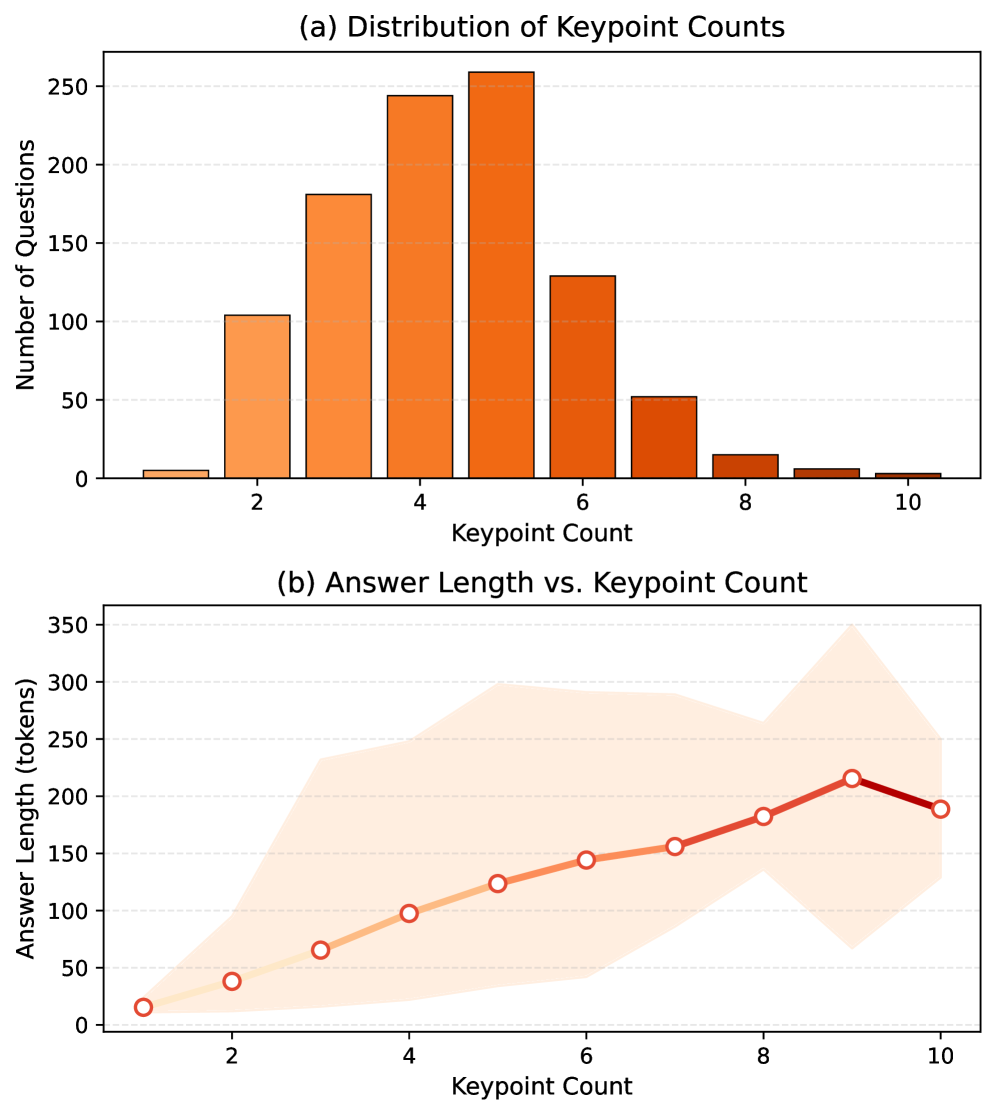
- Constructs a benchmark using a Human-LLM collaboration pipeline where LLMs generate drafts from real disaster queries and humans rigorously verify facts and refine distractors
- Evaluates models in three distinct contexts (Base, Golden, Mix) to disentangle internal knowledge limits from the ability to reason over noisy, retrieved evidence
- Introduces 'Keypoint Coverage' for open-ended QA, a metric that decomposes reference answers into atomic facts to measure strict factual recall rather than n-gram similarity
Architecture
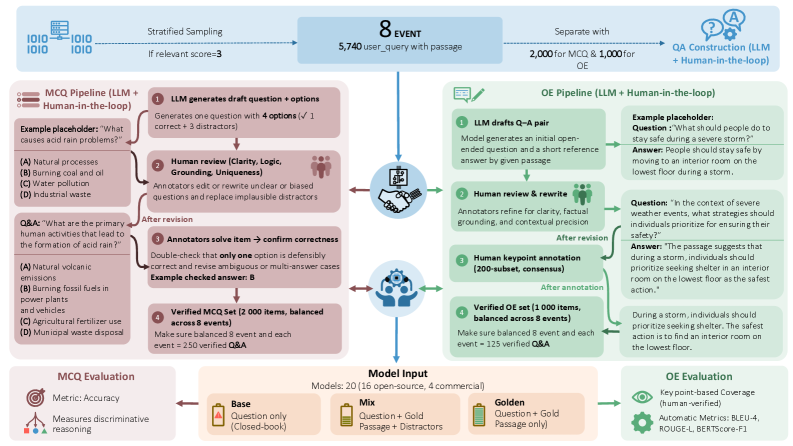
The Human-LLM collaboration pipeline for constructing DisastQA.
Evaluation Highlights
- Frontier models like GPT-4o achieve high accuracy in clean settings but degrade significantly (e.g., performance drops) when exposed to retrieval noise (Mix setting)
- Open-weight models like Qwen-2.5-72B-Instruct now approach proprietary leaders in clean contexts, narrowing the capability gap
- Even top models fail to achieve perfect Keypoint Coverage in open-ended tasks, revealing persistent gaps in factual completeness despite high fluency
Breakthrough Assessment
8/10
Significant contribution to domain-specific safety evaluation. The rigorous human verification and keypoint protocol offer a much-needed alternative to lexical metrics for high-stakes QA.