📝 Paper Summary
Modularized RAG pipeline
Domain-specific RAG (Biomedical)
A two-stage biomedical retrieval pipeline combining a lightweight ModernBERT bi-encoder for speed and a ColBERT re-ranker for precision achieves state-of-the-art accuracy on medical QA benchmarks while maintaining high efficiency.
Core Problem
General-purpose retrievers fail to capture the nuanced semantics of specialized medical domains, while high-accuracy in-domain models are often computationally prohibitive for large-scale retrieval.
Why it matters:
- Clinical applications demand high factual accuracy, as incorrect medical advice can have severe consequences.
- Medical language suffers from severe lexical and semantic gaps (e.g., 'stroke' vs. 'cerebrovascular accident'), which standard models miss.
- Existing solutions face a trade-off: fast models lack precision, while precise cross-encoders are too slow for real-time use.
Concrete Example:
A bi-encoder might rate a passage relevant to 'myocardial infarction treatments' even if it says 'myocardial infarction was ruled out,' because the negation is diluted in the single vector representation. The proposed re-ranker catches this by comparing token-level context.
Key Novelty
Hybrid ModernBERT + ColBERT Biomedical Pipeline
- Combines ModernBERT (bi-encoder) for rapid initial candidate retrieval with ColBERT (late-interaction) for fine-grained re-ranking, optimizing the speed-accuracy trade-off.
- Implements a coordinated fine-tuning strategy where the re-ranker is specifically trained on hard negatives mined from the retriever's errors, ensuring the two stages work in concert.
Architecture
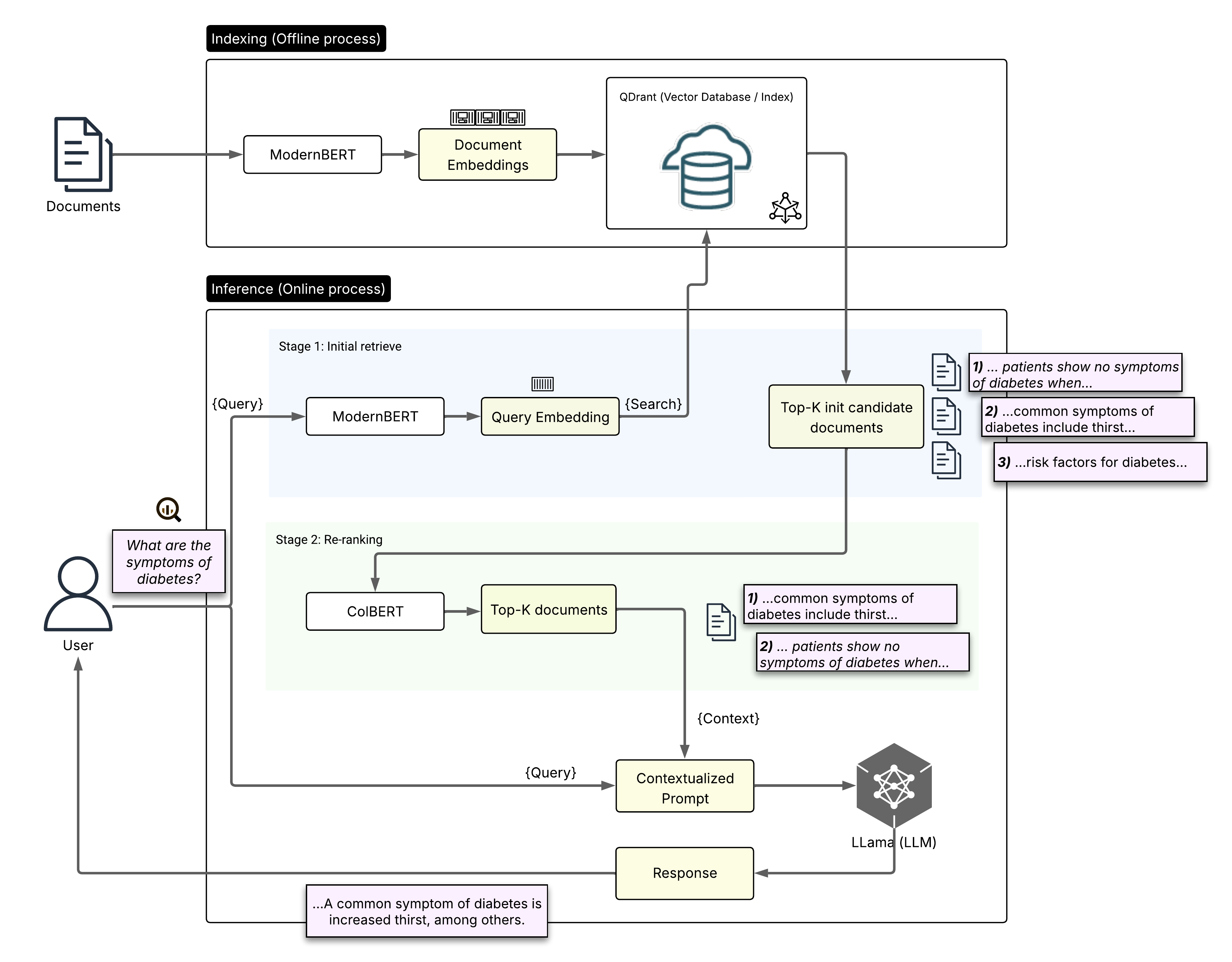
The end-to-end data flow of the two-stage retrieval pipeline.
Evaluation Highlights
- Achieves 0.4448 average accuracy on the MIRAGE benchmark, outperforming the specialized MedCPT baseline (0.4436) and DPR (0.4174).
- Indexing speed is 7.5x faster than the leading MedCPT baseline (149M vs 220M parameters), enabling more efficient knowledge base updates.
- ColBERT re-ranking improves Recall@3 by up to 4.2 percentage points compared to using the ModernBERT retriever alone.
Breakthrough Assessment
7/10
Solid engineering contribution demonstrating that smaller, well-tuned modular architectures can outperform larger specialized models in medical RAG, with significant efficiency gains.