📝 Paper Summary
Agentic RAG pipeline
RL-based search agents
Self-correction mechanisms
ReSeek trains search agents to dynamically self-correct during reasoning using a specialized JUDGE action and dense process rewards, validated on a new contamination-free benchmark called FictionalHot.
Core Problem
Existing search agents often commit to erroneous reasoning paths early on due to sparse rewards and lack mechanisms to recover from unproductive search steps.
Why it matters:
- Current RL-based agents rely on final answer correctness, which provides poor feedback for intermediate reasoning steps
- Without self-correction, a single misleading query can cause a cascade of errors that the agent cannot reverse
- High performance on public benchmarks may reflect data contamination (memorization) rather than genuine reasoning ability
Concrete Example:
When asking for the 'creator of Saddle Rash' to find their birth date, standard RAG and Search-R1 retrieve documents about the show but fail to find the creator's name. They cannot pivot. ReSeek retrieves the show info, JUDGEs it as useful but insufficient, then formulates a new query for 'Loren Bouchard birth date' to succeed.
Key Novelty
ReSeek (Self-Correcting Search Agent)
- Introduces a <judge> action that allows the agent to pause after retrieval, assess if the info is useful, and decide whether to keep it or discard it before the next step
- Uses a dense process reward that decomposes into correctness (factuality) and utility (relevance to query), guiding the agent's step-by-step decision making
- Creates FictionalHot, a benchmark of synthetic questions about fictional entities inserted into a closed-world corpus to strictly test reasoning without memorization
Architecture
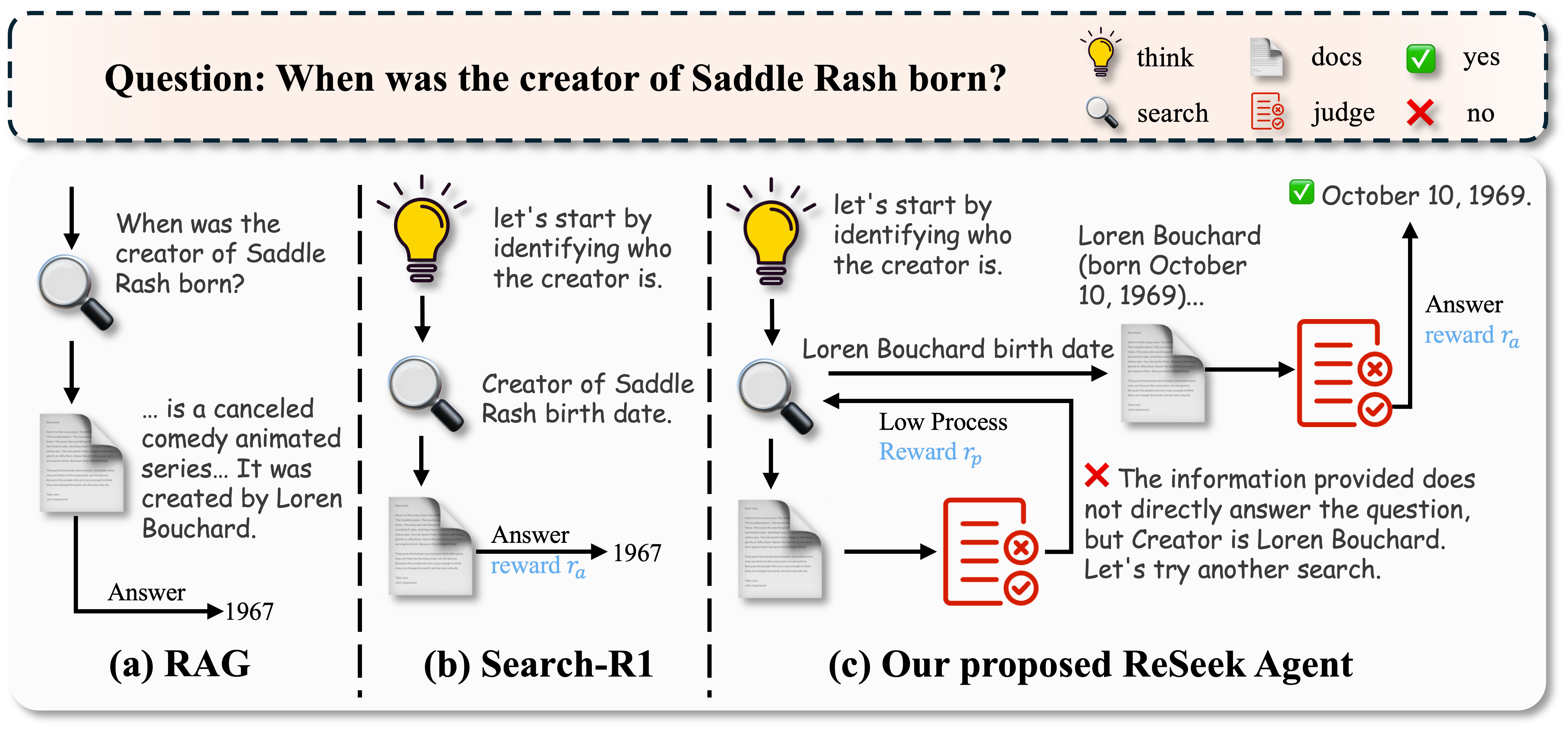
Comparison of RAG, Search-R1, and ReSeek workflows. Highlights ReSeek's cyclic self-correction process via the Judge action.
Evaluation Highlights
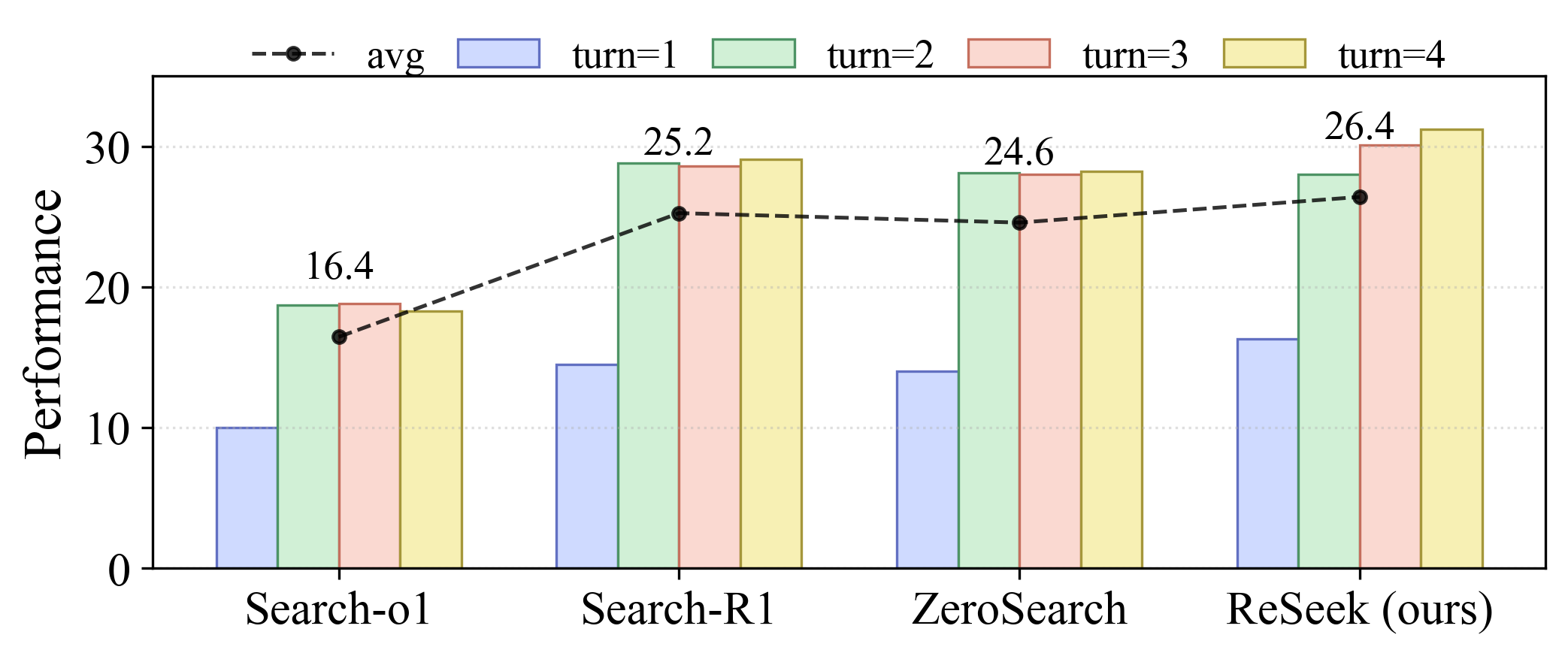
- Outperforms SOTA baseline ZeroSearch by +3.1% average accuracy (0.377 vs 0.346) on 8 QA benchmarks using Qwen-2.5-7B-Instruct
- Achieves significant gains on multi-hop tasks like HotpotQA and Bamboogle compared to baselines
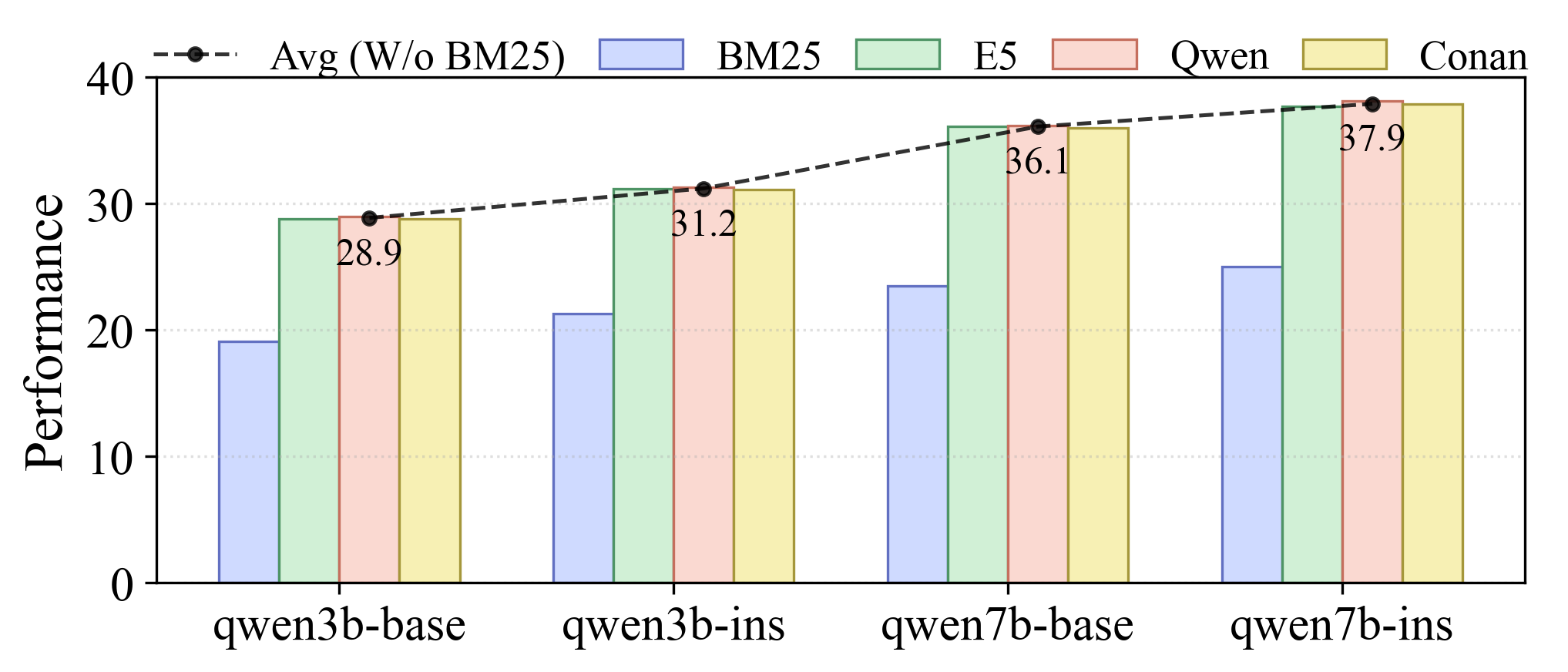
- Demonstrates minimal performance drop on FictionalHot between 3B and 7B models (0.059 vs 0.061), proving the benchmark successfully isolates reasoning from parametric knowledge
Breakthrough Assessment
8/10
Strong contribution in both method (dynamic self-correction with dense rewards) and evaluation (addressing data contamination with FictionalHot). Effectively targets the brittleness of current search agents.