📝 Paper Summary
Reasoning benchmarks
Structured knowledge integration
OneEval is a comprehensive benchmark assessing LLM reasoning capabilities across four structured knowledge modalities (text, knowledge graphs, code, formal logic) and five domains, revealing severe performance degradation as structural complexity increases.
Core Problem
Existing benchmarks focus predominantly on unstructured textual reasoning, failing to evaluate how LLMs handle structured external knowledge like knowledge graphs, code, or formal logic.
Why it matters:
- Real-world applications often require integrating structured data (e.g., databases, formal specs), not just narrative text.
- Current LLMs, even powerful ones like DeepSeek-R1 and Grok3, show significant fragility when transitioning from text to structured reasoning.
- The lack of diverse modality benchmarks masks blind spots in model capabilities regarding symbolic manipulation and formal logic.
Concrete Example:
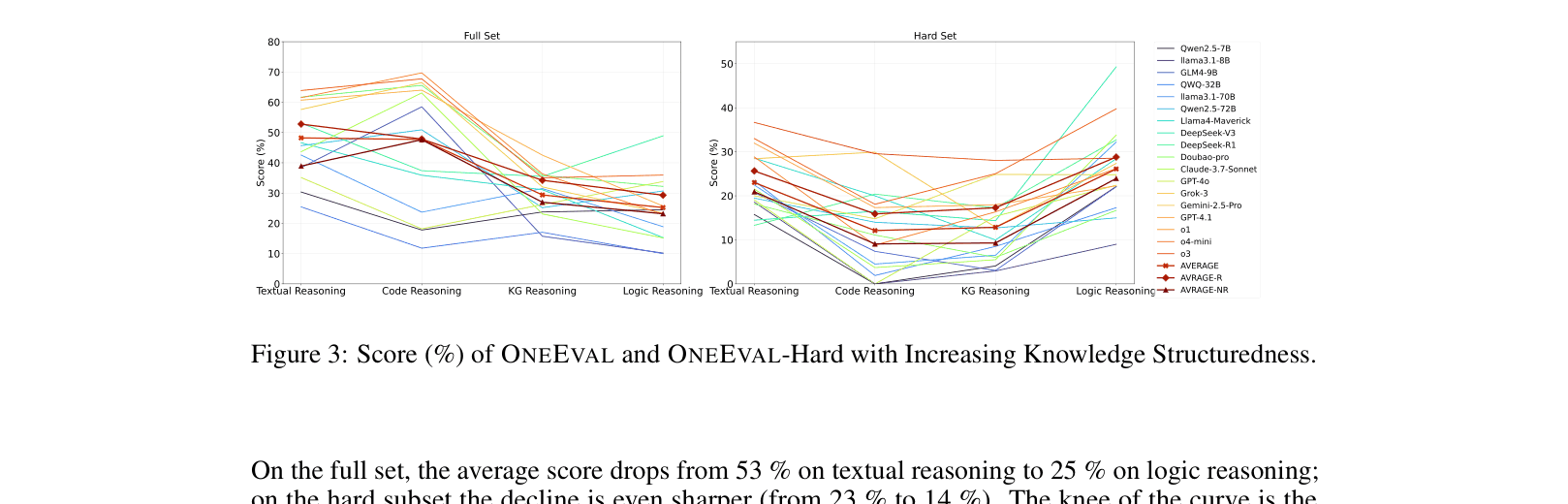
While models achieve 53% accuracy on textual reasoning, their performance drops to 25% on formal logic tasks within the same benchmark suite, showing they struggle to process explicit structural constraints compared to natural language patterns.
Key Novelty
Multi-Modality Structured Knowledge Benchmark
- Unifies evaluation across four distinct knowledge base types (Text, Knowledge Graph, Code, Logic) rather than testing them in isolation.
- Introduces a 'Hard' subset specifically curated through empirical failure rates and expert review to prevent saturation and test limits.
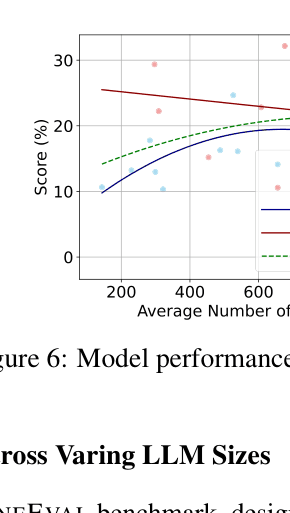
- Systematically analyzes the correlation between 'knowledge structuredness' (text → logic) and reasoning performance decline.
Architecture
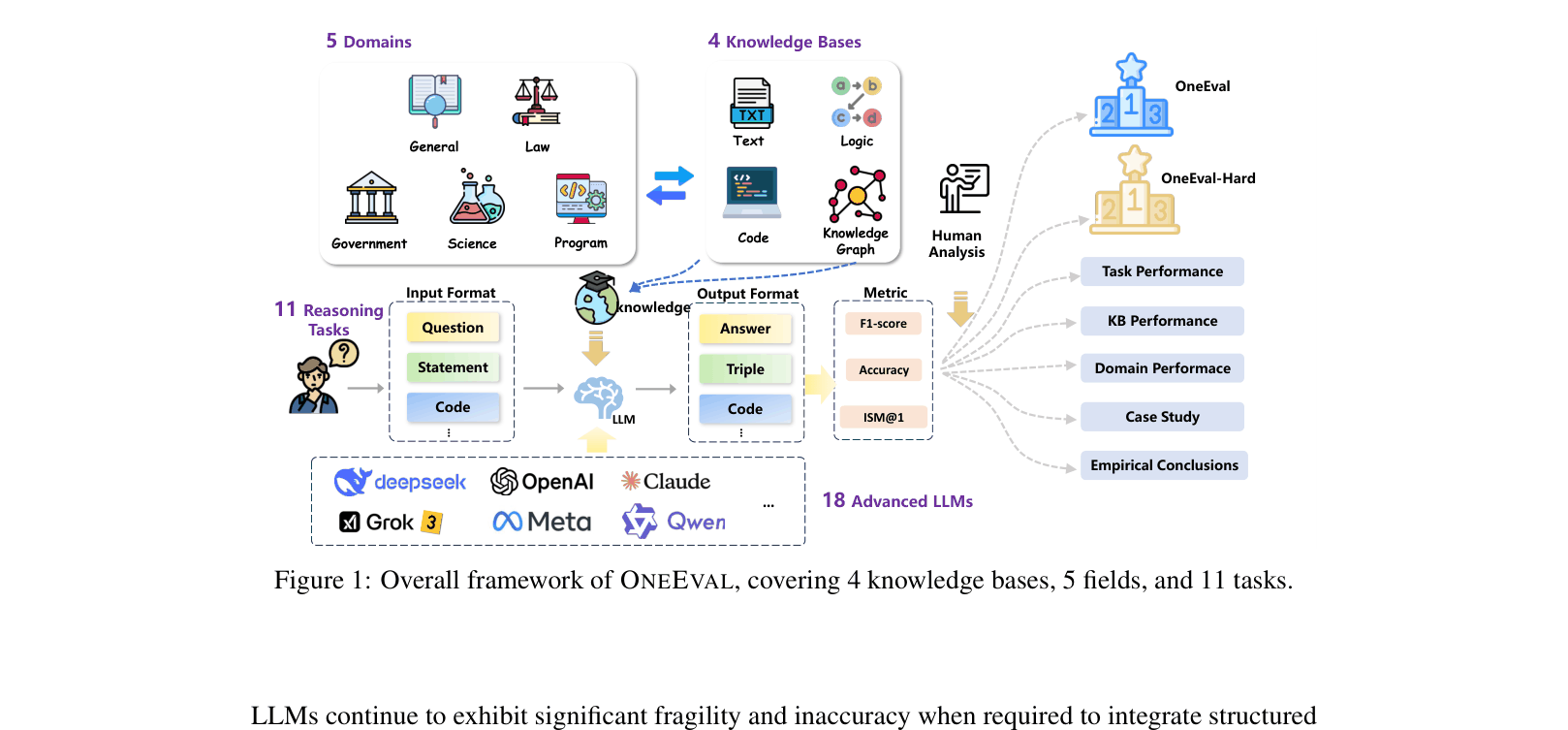
The OneEval framework structure, illustrating the 4 knowledge bases, 5 domains, and the evaluation pipeline.
Evaluation Highlights
- Accuracy drops sharply as structure increases: 53% on Textual Reasoning vs. 25% on Formal Logic (average across models).
- Even the strongest model (o3) achieves only 32.2% accuracy on the OneEval-Hard subset, highlighting a massive gap in robust reasoning.
- Reasoning-focused models (R-LLMs) outperform standard models by ~5.6 points on hard structured tasks, showing better resilience to complexity.
Breakthrough Assessment
8/10
A critical, comprehensive benchmark that exposes the 'structure gap' in current LLMs. It moves beyond simple text QA to rigorous structural evaluation, essential for future neuro-symbolic progress.