📝 Paper Summary
Interpretability
Program Synthesis
Decision Tree Learning
LeaPR models combine LLM-synthesized Python feature functions with classical decision trees to create efficient, fully interpretable predictors that compete with neural networks on complex tasks.
Core Problem
Classical interpretable models like decision trees fail on high-dimensional data (images, text) because they lack useful high-level features, while deep learning offers performance but lacks interpretability and requires heavy compute.
Why it matters:
- High-stakes decision-making requires models that can explain *why* a prediction was made, which neural networks struggle to provide reliably
- Classical models are compute-efficient but require extensive manual feature engineering to work on complex domains like chess or images
- Neural networks are data-hungry and generalize poorly when in-domain data is scarce
Concrete Example:
In chess, a decision tree looking at raw board squares cannot easily learn 'winning probability' because single squares carry little information. However, a simple programmatic feature like 'material difference' makes the task trivial for a shallow tree. Neural networks learn these features implicitly but opaquely; LeaPR explicitly generates the code for them.
Key Novelty
Learned Programmatic Representations (LeaPR)
- Uses LLMs as 'feature engineers' to write Python functions that map raw inputs (e.g., chess boards) to scalar values, leveraging the LLM's domain knowledge (e.g., chess libraries)
- Replaces the static feature set of classical decision trees with a dynamic set generated by LLMs during training to maximize predictive power
- Introduces D-ID3, a 'white-box' algorithm where the LLM generates specific features on-demand to split difficult leaf nodes based on the examples failing at that node
Architecture
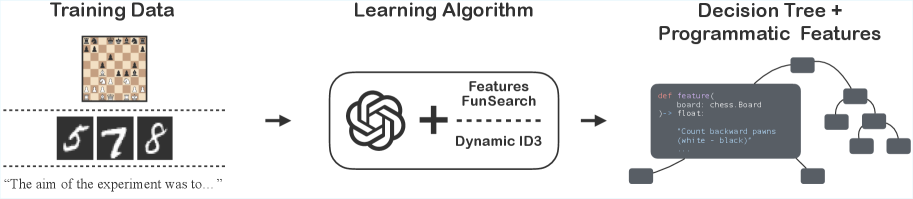
Illustration of the LeaPR hypothesis class: raw input data flows into LLM-generated Python functions (programmatic features), which output scalars that are fed into a decision tree predictor.
Evaluation Highlights
- LeaPR (D-ID3 with GPT-5-mini) achieves 98.8 F1 on Ghostbuster text classification, effectively matching the neural Ghostbuster baseline (99.0 F1)
- In chess position evaluation, LeaPR models trained on 200k samples outperform a Transformer baseline trained on 50M samples (250x more data) in RMSE (0.245 vs 0.252)
- On MNIST, LeaPR features allow a Random Forest to achieve 98.6% accuracy, comparable to a ResNet-50 baseline (99.3%)
Breakthrough Assessment
8/10
Demonstrates that LLM-generated code can replace latent neural representations for complex tasks like image/text classification, offering a rare combination of high performance and native interpretability.