📝 Paper Summary
Modularized RAG pipeline
Agentic RAG pipeline
Graph-based RAG pipeline
DO-RAG automates domain-specific QA by building dynamic multimodal knowledge graphs via agents and fusing graph traversal with vector search to ground answers and mitigate hallucinations.
Core Problem
Standard RAG systems struggle with the complex, heterogeneous data in technical domains, leading to fragmented retrieval and hallucinations due to a lack of structured reasoning.
Why it matters:
- Generic models often fail on domain-specific terminology or multi-step reasoning required for technical manuals and logs.
- Existing KG-RAG hybrids face scalability bottlenecks because manual graph construction is labor-intensive and hard to maintain as knowledge evolves.
- Loosely coupled retrieval and generation components cannot guarantee that final answers faithfully reflect the retrieved technical evidence.
Concrete Example:
When answering a query about a specific database error from a technical manual, a standard RAG might retrieve loosely related text chunks but miss the causal relationship between the error code and a specific configuration parameter, leading to an incorrect diagnosis.
Key Novelty
Agentic Chain-of-Thought for Dynamic KG Construction & Hybrid Fusion
- Uses a hierarchical team of agents (High, Mid, Low, Covariate) to automatically extract entities and relationships from unstructured multimodal docs into a Knowledge Graph.
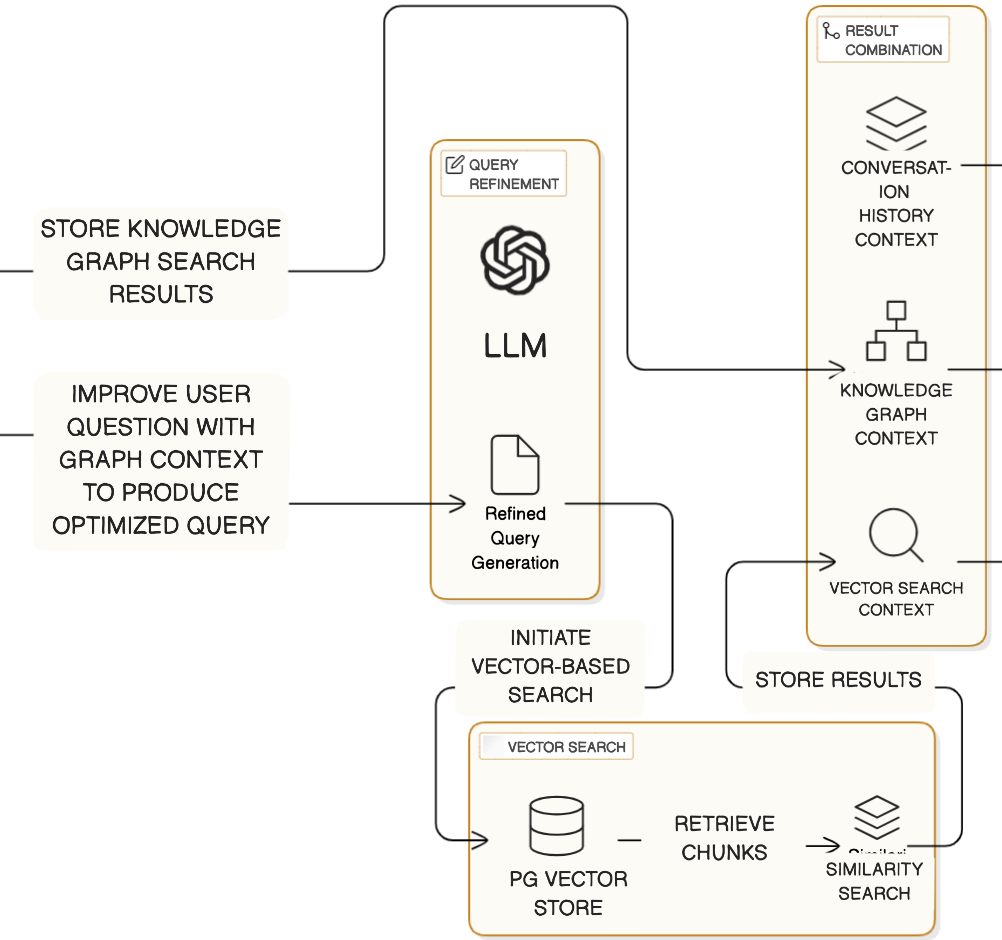
- Integrates retrieval by using graph traversal to find structured context, which is then used to refine the query for a subsequent vector search.
- Implements a post-generation refinement step that explicitly cross-verifies the LLM's output against the graph evidence to correct hallucinations.
Architecture
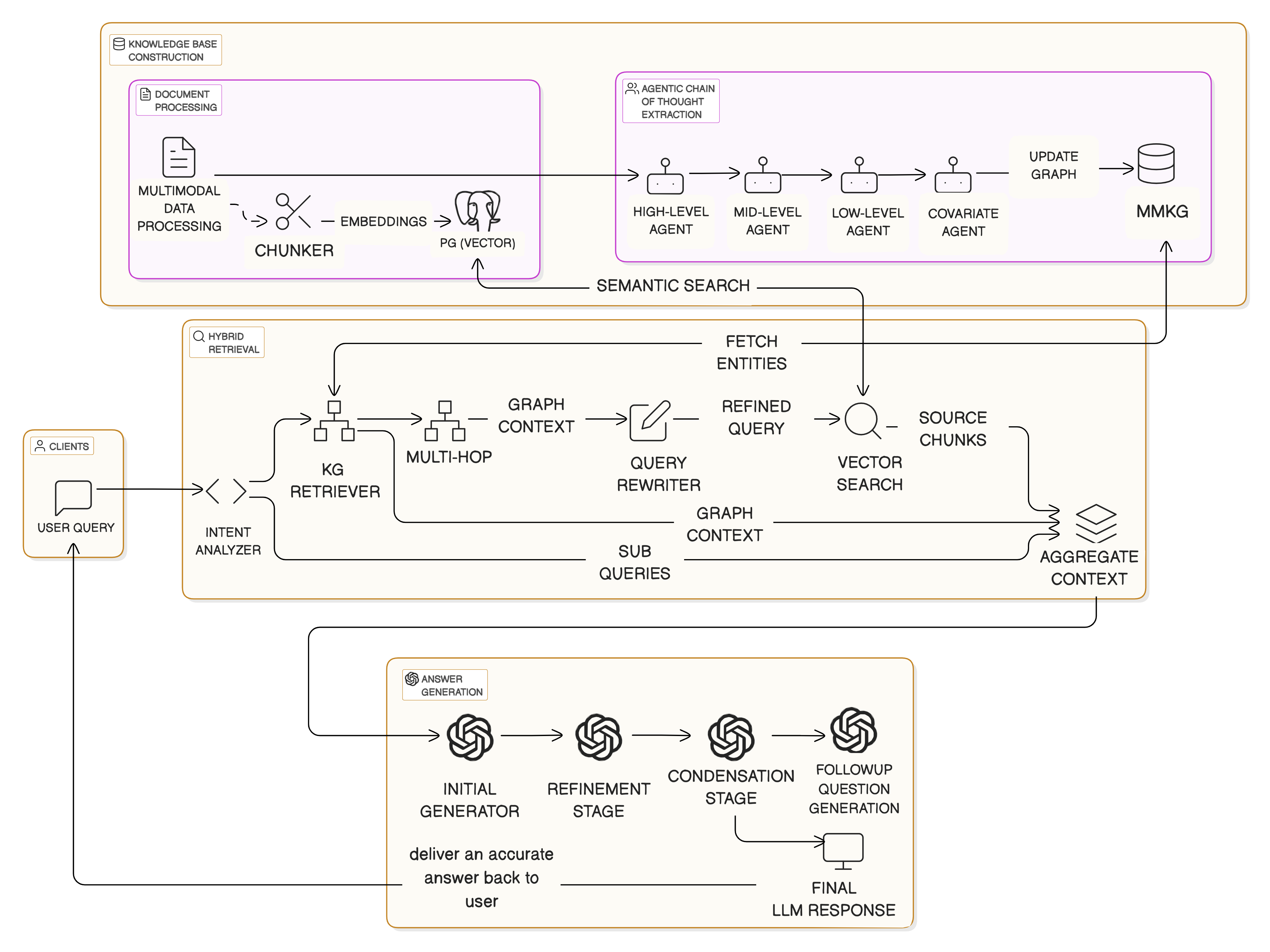
The complete DO-RAG workflow from document ingestion to answer generation.
Evaluation Highlights
- Achieved nearly 1.0 Contextual Recall and over 94% Answer Relevancy on the SunDB and Electrical domain benchmarks.
- Outperformed FastGPT, TiDB.AI, and Dify.AI by up to 33.38% in composite scores.
- DeepSeek-V3 with DO-RAG improved Answer Relevancy by 5.7% compared to vector-only retrieval baselines.
Breakthrough Assessment
8/10
Strong engineering integration of agentic KG construction with RAG. While the components are known, the automated end-to-end pipeline and significant performance gains over industrial baselines make it a practical breakthrough for domain-specific applications.