📝 Paper Summary
Modularized RAG pipeline
Retrieval
TEM introduces a fine-tuned embedding model and specialized RAG workflow for retrieving relevant tabular data files in financial analysis, avoiding the scalability issues of chunking rows.
Core Problem
Standard RAG approaches that chunk documents fail for large tabular data (like financial CSVs) because chunking millions of rows is unscalable, creates redundancy, and overwhelms the LLM context window.
Why it matters:
- Financial analysis often requires processing entire datasets (e.g., millions of rows) rather than isolated chunks, which generic retrieval methods cannot handle effectively.
- Existing SOTA embedding models are trained primarily on text, leading to poor performance and hallucinations when retrieving complex numeric or tabular data.
- Providing wrong or partial data chunks to an LLM prevents accurate execution of data analysis code (e.g., calculating returns across an entire index).
Concrete Example:
When asked 'Identify best performing stock by returns from S&P500 index components over the last 6 months', a generic embedding model retrieves irrelevant data chunks, causing the LLM to hallucinate because it lacks the full dataset required for calculation.
Key Novelty
Tabular Embedding Model (TEM) via New Word Embedding Initialization
- Instead of chunking rows, the system embeds questions to map directly to entire file/table metadata, allowing an agent to load the full dataset for analysis.
- Expands the base model's vocabulary with domain-specific terms by initializing 'New Word Embeddings' using the average and variance of existing embeddings to maintain stability.
- Fine-tunes a lightweight open-source model using a Multiple Negative Ranking (MNR) loss to strictly align user queries with correct table filenames.
Architecture
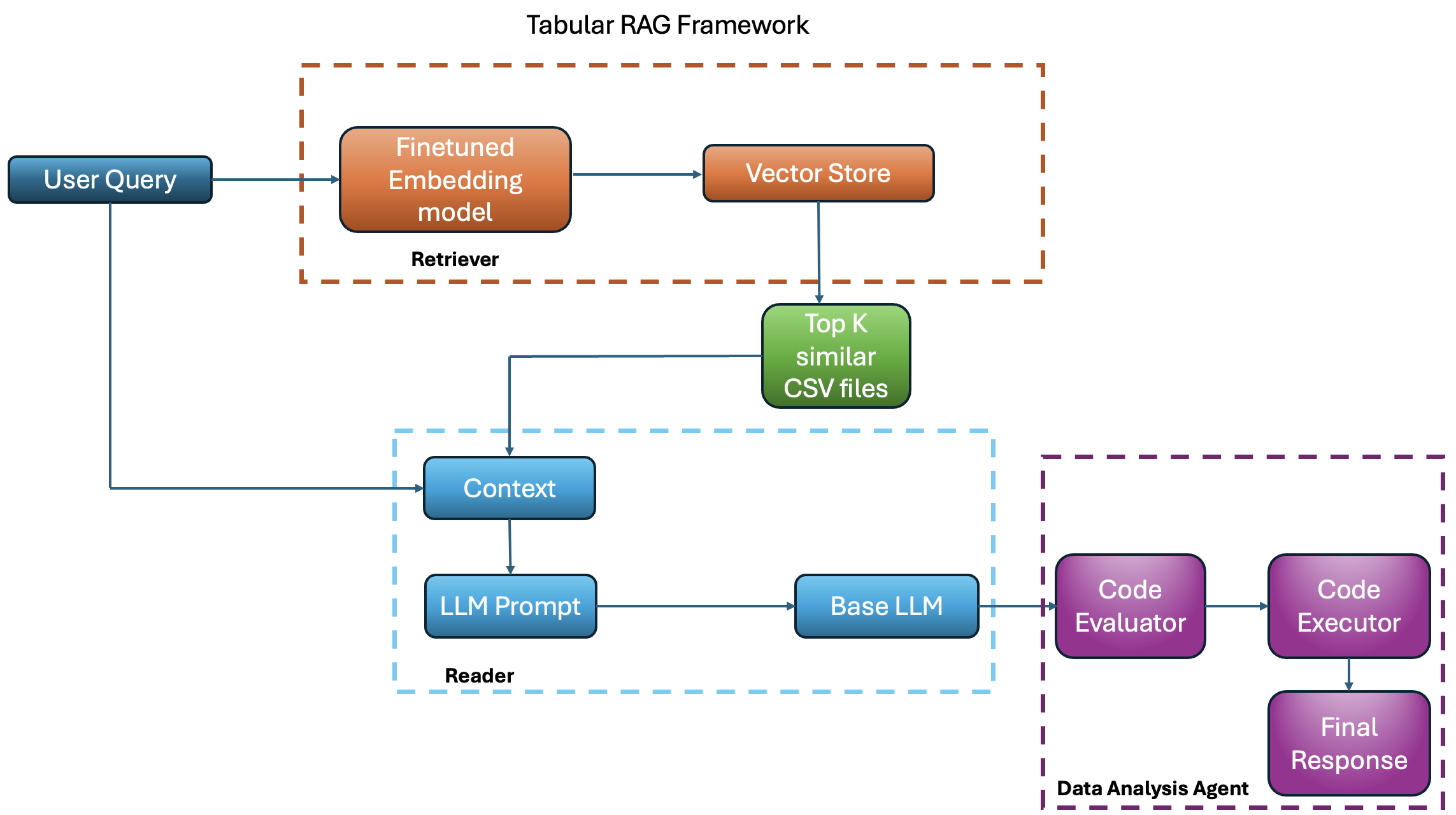
The RAG pipeline for tabular data analysis.
Evaluation Highlights
- Significantly outperforms SOTA embedding models (OpenAI text-embedding-3-large, BGE-large) in financial tabular retrieval tasks.
- Achieves superior performance using a lightweight model structure (fine-tuned BGE-large-en-v1.5) compared to larger proprietary models.
- Training completed in under 8 hours on consumer hardware (Macbook M3 Max), demonstrating high efficiency.
Breakthrough Assessment
7/10
Addresses a critical scalability bottleneck in RAG for tabular data by shifting from row-retrieval to file-retrieval. Strong practical utility for finance, though evaluation is limited to a custom dataset.