📝 Paper Summary
Benchmark
Modularized RAG pipeline
The AutoNuggetizer framework automates the TREC 'nugget' evaluation methodology using LLMs to create and assign factual units to RAG answers, correlating strongly with manual human assessment.
Core Problem
RAG evaluation lacks standardization and efficiency, creating a barrier to progress in information access and NLP.
Why it matters:
- Current RAG evaluations are often deficient or inconsistent, preventing reliable comparison between systems
- Manual evaluation of complex, long-form answers is prohibitively expensive and slow at scale
- The lack of standardized metrics hinders the broader advancement of artificial intelligence and natural language processing
Concrete Example:
For the query 'how did african rulers contribute to the triangle trade', a system might generate a fluent answer. Traditional metrics might miss whether specific facts (nuggets) like 'rulers sold enslaved people' or 'received goods in return' are present, or require expensive human judgment to verify them.
Key Novelty
AutoNuggetizer Framework
- Refactors the 2003 TREC QA nugget methodology by replacing human annotators with LLMs (GPT-4o) for both creating information nuggets and assigning them to answers
- Introduces a semi-automated pipeline where LLMs generate 'atomic nuggets' (facts) from documents, which can optionally be post-edited by humans before automatic assignment
Architecture
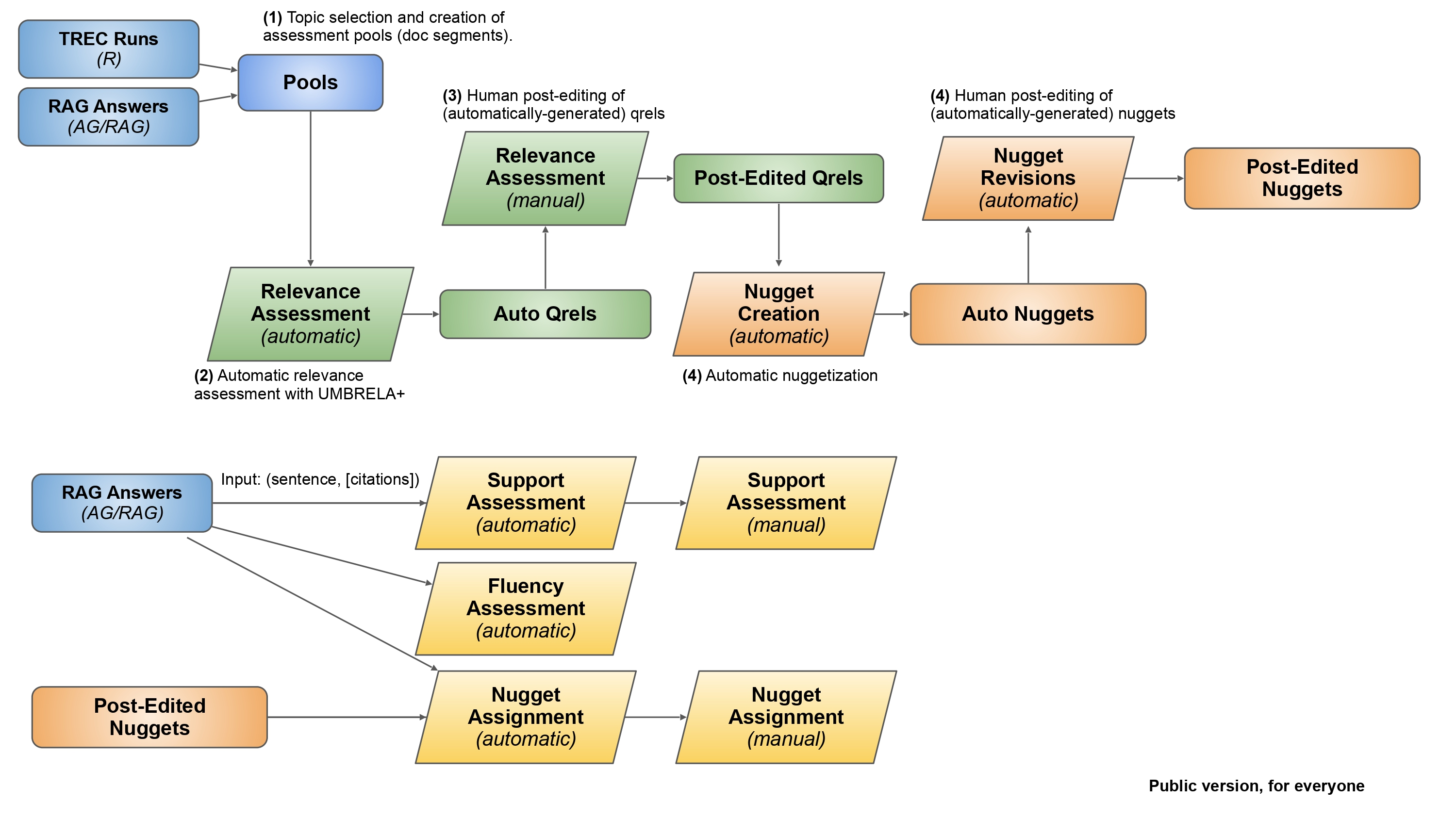
The workflow of the TREC 2024 RAG Track, highlighting the separation of Retrieval (R), Augmented Generation (AG), and full RAG tasks.
Evaluation Highlights
- Demonstrates strong correlation between fully automatic nugget evaluation and manual human assessment across 21 topics
- Successfully applied to 45 runs in the TREC 2024 RAG Track, providing a calibrated automated scoring method
Breakthrough Assessment
7/10
Significant for standardizing RAG evaluation by successfully modernizing a proven IR methodology (nuggets) with LLMs, validated against human judgments in a high-profile venue (TREC).