📝 Paper Summary
Benchmark datasets
Graph-based RAG pipeline
KGQAGen is an LLM-in-the-loop framework that generates high-quality, verifiable Knowledge Graph Question Answering benchmarks by iteratively expanding subgraphs and verifying answers via SPARQL to address factual errors in existing datasets.
Core Problem
Existing Knowledge Graph Question Answering (KGQA) benchmarks suffer from critical quality issues, including inaccurate annotations, ambiguous questions, and outdated knowledge, making them unreliable for evaluating KG-RAG systems.
Why it matters:
- Widely used benchmarks like WebQSP and CWQ have alarmingly low factual correctness rates (52% and 49.3%, respectively), misleading research progress.
- Rigid exact-match evaluation metrics penalize semantically correct answers that differ in surface form, creating false negatives.
- Outdated answers (e.g., old presidents) punish models that actually possess up-to-date knowledge.
Concrete Example:
In WebQSP, the question 'Where did Andy Murray start playing tennis?' is incorrectly annotated with '2005' (a year, not a location). Another question 'Who is the president of Peru now?' lists Ollanta Humala (president 2011-2016), punishing models that name the current president.
Key Novelty
Grounded & Verifiable KGQA Generation via LLM-KG Loop
- Iterative Subgraph Expansion: Starts with a seed entity and expands to neighbors under LLM guidance to create complex, multi-hop contexts rather than simple lookups.
- Symbolic Verification: Uses SPARQL queries to mathematically verify that generated answers are correct and fully supported by the underlying knowledge graph (Wikidata), ensuring 96% accuracy.
- LLM-in-the-loop validation: An LLM acts as a critic during generation to ensure questions are linguistically well-formed and contextually sufficient before final output.
Architecture
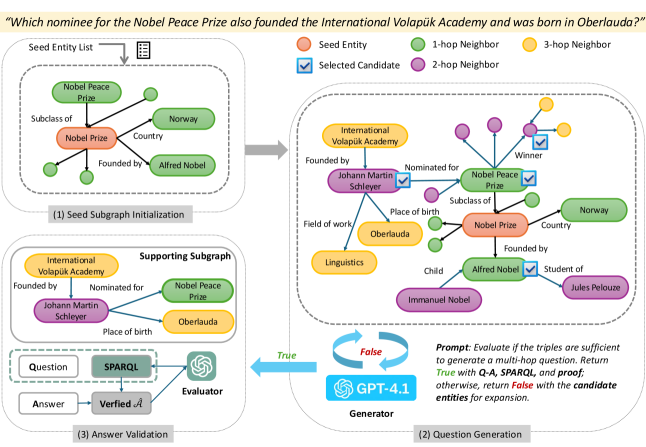
The overall workflow of the KGQAGen framework for constructing the dataset.
Evaluation Highlights
- Manual audit of 16 existing datasets reveals an average factual correctness rate of only 57%, with popular benchmarks WebQSP at 52% and CWQ at 49.3%.
- Constructed KGQAGen-10k (10,787 pairs), achieving 96% factual accuracy based on manual inspection of 300 samples.
- Even state-of-the-art models struggle on the new benchmark: GPT-4o achieves only 62.40% BEM (Bounded Exact Match) score, and KG-RAG systems like GCR reach only 48.75%.
Breakthrough Assessment
9/10
Exposes a massive reliability crisis in the field's standard benchmarks (WebQSP/CWQ) with concrete data and provides a scalable, high-quality solution (KGQAGen) to fix it. Essential for trustworthy KG-RAG evaluation.