📝 Paper Summary
Memory internalization
Graph-based RAG pipeline
RAG-Tuned-LLM fine-tunes a smaller model using synthetic data generated via GraphRAG principles to internalize memory, outperforming both vanilla RAG and long-context LLMs on local and global queries.
Core Problem
Current solutions for incorporating external memory (RAG and Long-context LLMs) have distinct trade-offs: RAG struggles with global queries requiring big-picture understanding, while Long-context LLMs are expensive and weaker at specific local details.
Why it matters:
- Personal assistants require both specific retrieval (local) and high-level summarization (global) capabilities
- Long-context models (e.g., Gemini 1.5) are computationally expensive and slow for real-time applications
- Standard RAG often misses the 'big picture' by only retrieving top-k chunks, failing on queries that require aggregating information across the entire corpus
Concrete Example:
In a 'Journaling' dataset, a user might ask a global question like 'How has my mood changed over the last month?' (which RAG fails to aggregate) or a local question 'What did I eat last Tuesday?' (which long-context models might miss amidst noise). The paper shows VanillaRAG wins on local queries but loses significantly on global ones compared to Gemini-1.5-pro.
Key Novelty
RAG-Tuned-LLM (LLM-native Memory)
- Synthesize fine-tuning data using GraphRAG principles: extract entities/relationships to create 'global' summary questions and 'local' specific questions
- Tune a smaller LLM (e.g., 7B) on this synthetic dataset to 'internalize' the external knowledge into the model's parameters
- Use Chain-of-Thought (CoT) in the synthetic data to teach the model to reason about the internalized memory rather than just memorizing facts
Architecture
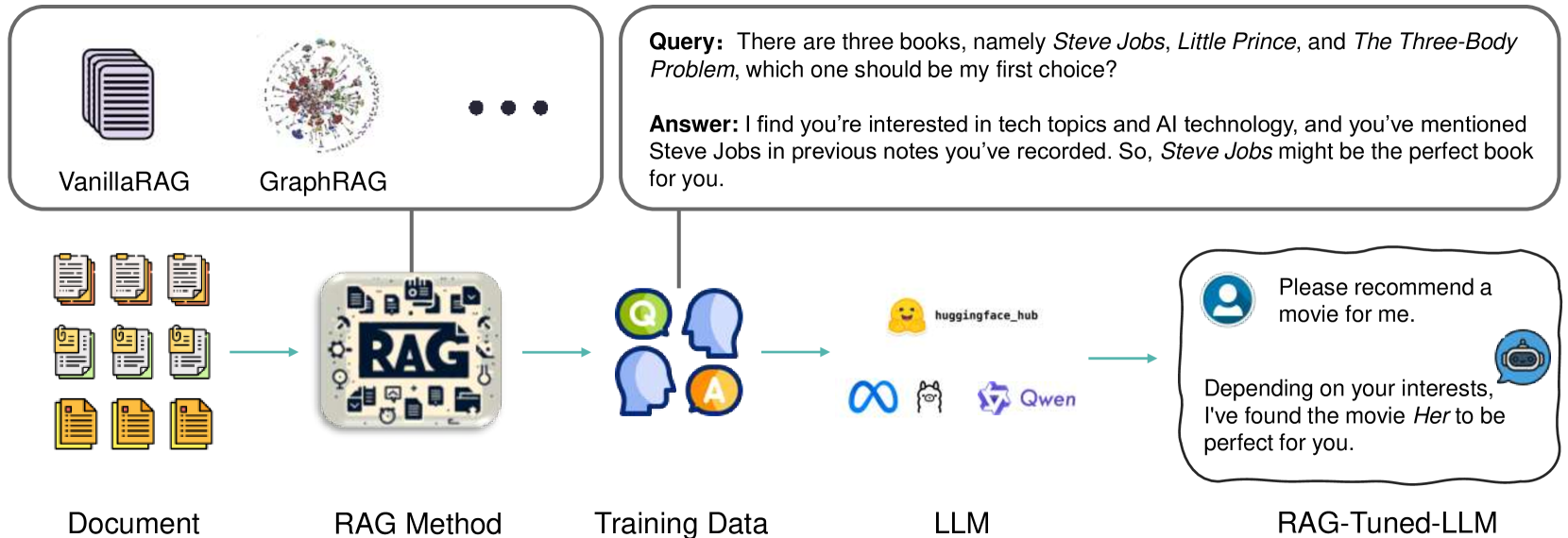
The overall workflow of RAG-Tuned-LLM, illustrating how data is processed from documents to fine-tuning.
Evaluation Highlights
- RAG-Tuned-LLM achieves 77.2% win rate against VanillaRAG on global queries in the Podcast dataset, compared to Gemini-1.5-pro's 75.2%
- On the News dataset, RAG-Tuned-LLM reaches 85.6% win rate on local queries, surpassing both VanillaRAG (reference baseline) and Gemini-1.5-pro
- In the user-curated Journaling dataset, RAG-Tuned-LLM achieves 61.3% win rate on global queries vs VanillaRAG
Breakthrough Assessment
7/10
Strong practical contribution demonstrating that fine-tuning on structural RAG data (GraphRAG) allows smaller models to beat massive long-context models on memory tasks. The approach bridges the gap between RAG and long-context.