📝 Paper Summary
Long-context reasoning
Reinforcement Learning with Verifiable Rewards (RLVR)
SPELL enables LLMs to self-evolve on long-context tasks by cycling through three roles—questioner, responder, and verifier—generating their own training data and reward signals without human labels.
Core Problem
Training long-context reasoning models is bottlenecked by the scarcity of high-quality human annotations and the lack of verifiable reward signals for complex, open-ended document tasks.
Why it matters:
- Human annotation for extra-long documents is expensive and unreliable (accuracy drops to ~25% on LongBench-V2), limiting supervision quality.
- Existing RL methods rely on static datasets or short-context verifiable tasks (like math), failing to scale to complex reasoning over lengthy texts where simple rule-based verification fails.
- As context length grows, the diversity of available supervision diminishes, stalling progress for models approaching superhuman capabilities.
Concrete Example:
In long-context QA, a model might generate a correct answer that is phrased differently from the reference (e.g., 'The revenue grew by 20%' vs '20% increase'). Simple string matching rejects this valid answer, providing false negative feedback that confuses the policy, while human verification is too slow to scale.
Key Novelty
Self-Play Evolutionary Loop (SPELL)
- A single LLM adopts three rotating roles: a 'Questioner' that creates tasks from documents, a 'Responder' that solves them, and a 'Verifier' that judges correctness to provide rewards.
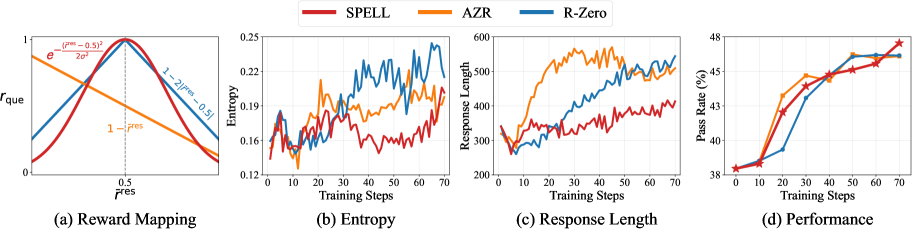
- Uses an automated curriculum where the Questioner is rewarded for generating tasks at the frontier of the Responder's ability (roughly 50% success rate), ensuring continuous challenge.
- Combines rule-based checks with a learned consistency-based Verifier to generate reliable rewards even when answers are semantically correct but lexically different from references.
Architecture
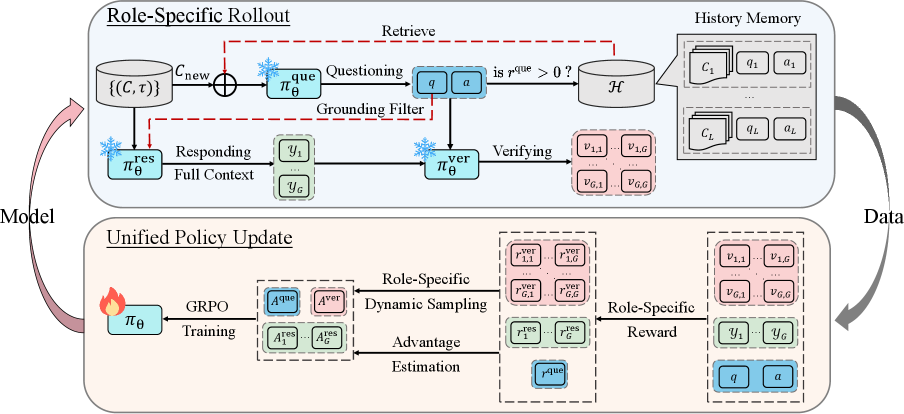
The SPELL framework loop showing the three roles (Questioner, Responder, Verifier) interacting with documents and history memory.
Evaluation Highlights
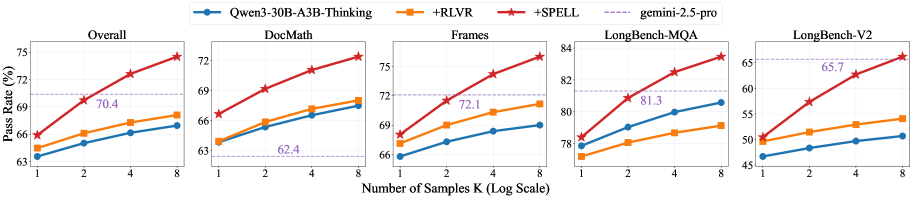
- Achieves an average 7.6-point gain in pass@8 on the strong reasoning model Qwen3-30B-A3B-Thinking across six benchmarks.
- Outperforms equally sized models fine-tuned on large-scale annotated data (e.g., Qwen2.5-7B + SPELL beats Qwen2.5-7B-Instruct).
- Surpasses the leading gemini-2.5-pro model on pass@4 performance for complex reasoning tasks.
Breakthrough Assessment
9/10
Highly significant. Successfully applies self-play RL to long-context reasoning—a domain previously resistant to RLVR due to lack of verification—showing it can beat supervised fine-tuning without human labels.