📝 Paper Summary
RAG Evaluation
RAG Benchmarks
CoFE-RAG evaluates the entire RAG pipeline using a new diverse dataset and multi-granularity keywords to assess retrieval without relying on rigid golden chunk annotations.
Core Problem
Existing RAG evaluations rely on limited data diversity (mostly plain text/factual queries) and use 'golden chunk' metrics that break when chunking strategies change, making it hard to diagnose specific pipeline failures.
Why it matters:
- Current benchmarks like RAGAS or RGB focus on simple factual queries, failing to test complex analytical or tutorial reasoning required in real-world applications
- Relying on annotated 'golden chunks' requires labor-intensive relabeling whenever the chunking strategy (e.g., size, overlap) is modified
- End-to-end evaluation obscures whether errors stem from poor retrieval, bad reranking, or hallucinating generators
Concrete Example:
If a user asks an analytical question like 'What level of innovation will China's intelligent cars reach by 2025?', standard metrics might miss relevant context if the chunking size changes and the text no longer aligns with pre-annotated 'golden chunks'. CoFE-RAG uses keyword constraints to match content regardless of chunk boundaries.
Key Novelty
Multi-Granularity Keyword Evaluation for Reference-Free Retrieval Assessment
- Replaces static 'golden chunk' annotations with dynamic keyword-based matching: Coarse-grained keywords filter for relevance, while Fine-grained keyword lists check for specific information points
- Evaluates the RAG pipeline step-by-step (chunking, retrieval, reranking, generation) rather than just the final answer
- Introduces a benchmark with diverse source formats (PDF, PPT, Excel) and query types (Comparative, Analytical, Tutorial) beyond simple facts
Architecture

The workflow of CoFE-RAG framework showing the pipeline from Query/Document input to Multi-granular Keyword evaluation.
Evaluation Highlights
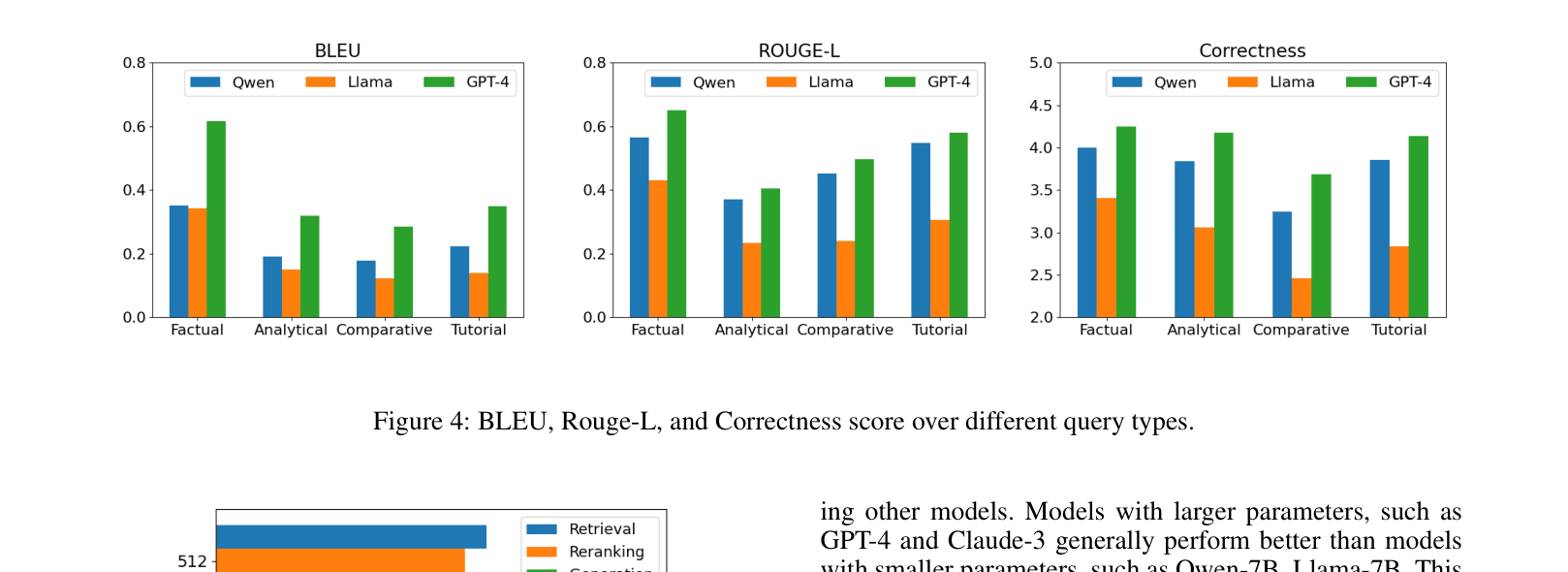
- BGE-Large outperforms other embedding models on the new benchmark but still struggles with Tutorial queries (54.7% Accuracy vs 63.8% for Factual)
- GPT-4o significantly outperforms other LLMs in generation, achieving a Correctness Score of 4.07, compared to 3.76 for Qwen2-7B
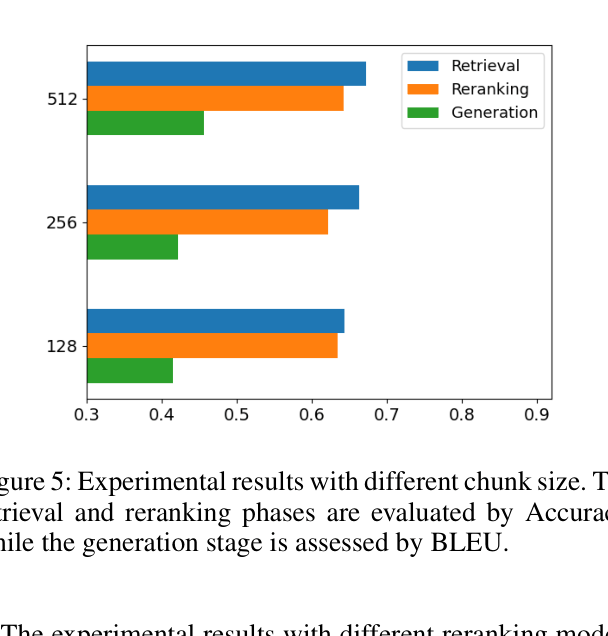
- Larger chunk sizes (512 tokens) generally improve performance across retrieval and generation compared to smaller sizes (128/256 tokens) on this dataset
Breakthrough Assessment
7/10
Strong contribution to RAG evaluation methodology by removing the dependency on fixed chunk annotations and introducing diverse document formats. The dataset is valuable, though the core innovation is primarily in the evaluation metric design.