📝 Paper Summary
Memory
Memory recall
DH-RAG improves multi-turn dialogue generation by maintaining a dynamic historical database that organizes past interactions via clustering and hierarchical matching to reconstruct more contextually aware queries.
Core Problem
Traditional RAG systems rely on static knowledge bases and fail to effectively utilize the dynamic, evolving context of multi-turn dialogues, leading to disconnected or irrelevant responses.
Why it matters:
- Human cognition relies on both long-term memory (static knowledge) and short-term working memory (dynamic history) for coherent conversation.
- Existing RAG methods often treat queries in isolation or use simple concatenation, missing the rich contextual cues necessary for maintaining dialogue flow over many turns.
Concrete Example:
In a conversation where a user first asks about 'Apple' (the fruit) and later asks 'How much is it?', a standard RAG might retrieve stock prices if it fails to link the second query to the dynamic history of the fruit discussion, whereas DH-RAG uses the history to disambiguate.
Key Novelty
Dynamic Historical Context-Powered RAG (DH-RAG)
- Introduces a 'Dynamic Historical Information Database' that updates in real-time, storing query-passage-response triples.
- Uses a 'History-Learning based Query Reconstruction Module' that combines static knowledge with dynamic history using attention mechanisms.
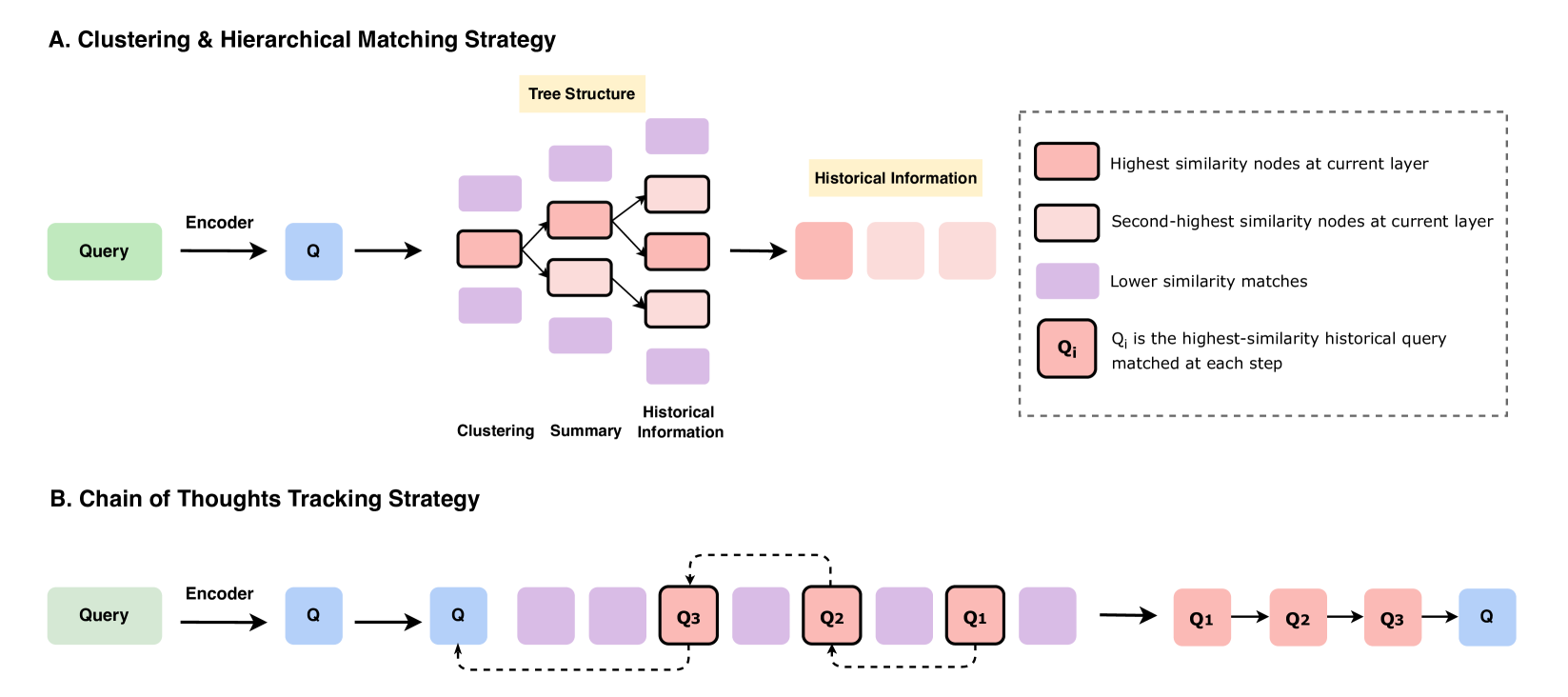
- Implements three specific strategies for history retrieval: Historical Query Clustering (grouping similar topics), Hierarchical Matching (tree-structured search), and Chain of Thought Tracking (following logical progression).
Architecture
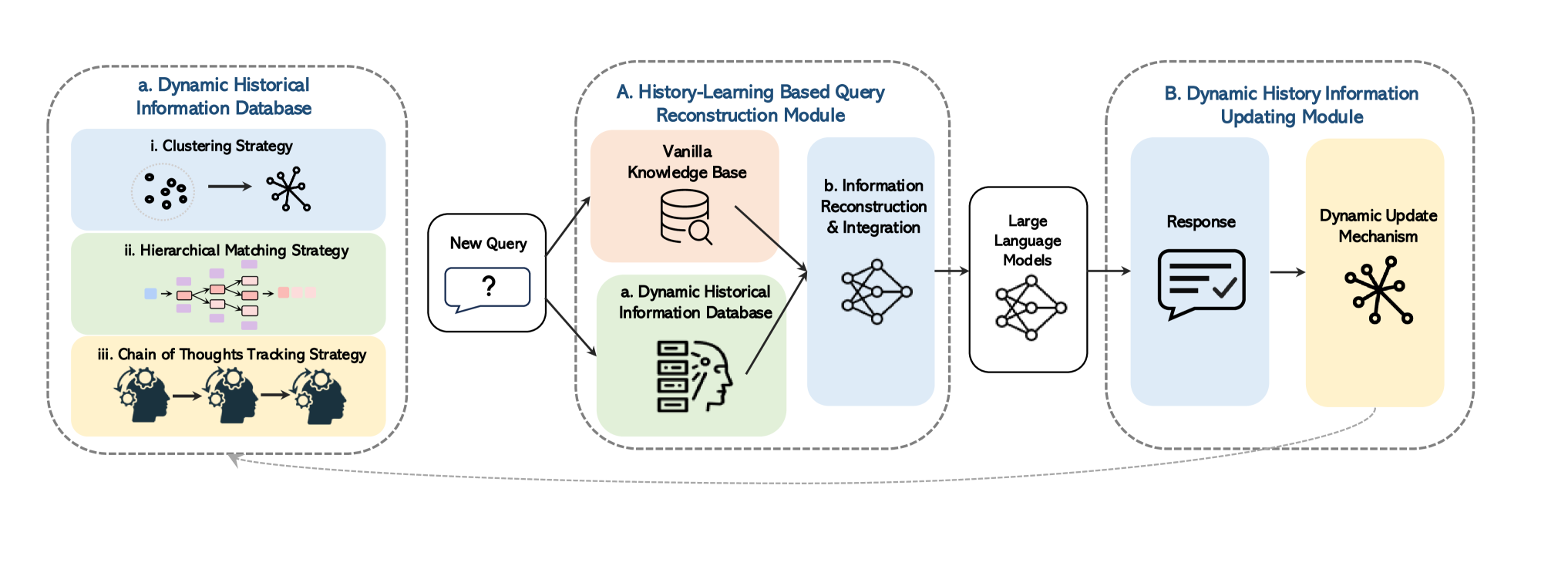
The overall workflow of the DH-RAG system in a multi-turn conversation.
Evaluation Highlights
- Outperforms baselines on TopiocChat dataset with a BLEU-2 score of 12.3 (vs. 6.4 for RAG).
- Achieves higher ROUGE-L scores consistently across MultiDoc2Dial, QReCC, and TopiocChat benchmarks compared to standard RAG and other dialogue models.
- Demonstrates superior coherence and relevance in human evaluation compared to vanilla RAG systems.
Breakthrough Assessment
7/10
Offers a structured, logically sound approach to memory management in RAG (clustering/hierarchy) rather than just context window stuffing. While the architecture is solid, the specific improvements are evolutionary rather than revolutionary.