📝 Paper Summary
Agentic RAG pipeline
Post-training for Agents
Prompt Engineering
RAG-Gym is a framework that systematically optimizes agentic RAG by combining a new reflection-based prompt (Re2Search) with process-level actor tuning via DPO and critic-guided inference.
Core Problem
Existing agentic RAG methods rely on ad-hoc prompt engineering or outcome-based reinforcement learning, lacking fine-grained process supervision for intermediate retrieval and reasoning steps.
Why it matters:
- Outcome-based rewards often fail to optimize intermediate search actions, leading to suboptimal retrieval trajectories
- Without process-level supervision, agents struggle to generalize to unseen data or complex tasks requiring multi-hop reasoning
- Current methods lack a unified framework to compare optimization across prompting, actor tuning, and critic training simultaneously
Concrete Example:
When answering a complex question requiring multiple facts, a standard agent might issue a generic query and hallucinate an answer. In contrast, RAG-Gym's Re2Search agent explicitly lists 'unverified claims' from its initial reasoning, generates specific queries to verify them, and receives DPO training on those specific intermediate query-generation steps.
Key Novelty
RAG-Gym Framework & Re2Search Agent
- Formulates RAG as a high-level Markov Decision Process (MDP) where macro-actions (search queries or answers) serve as distinct steps for process-level optimization
- Introduces Re2Search (Reasoning, Reflection, and Search), a prompting strategy where the agent explicitly identifies 'unverified claims' in its reasoning to drive targeted information retrieval
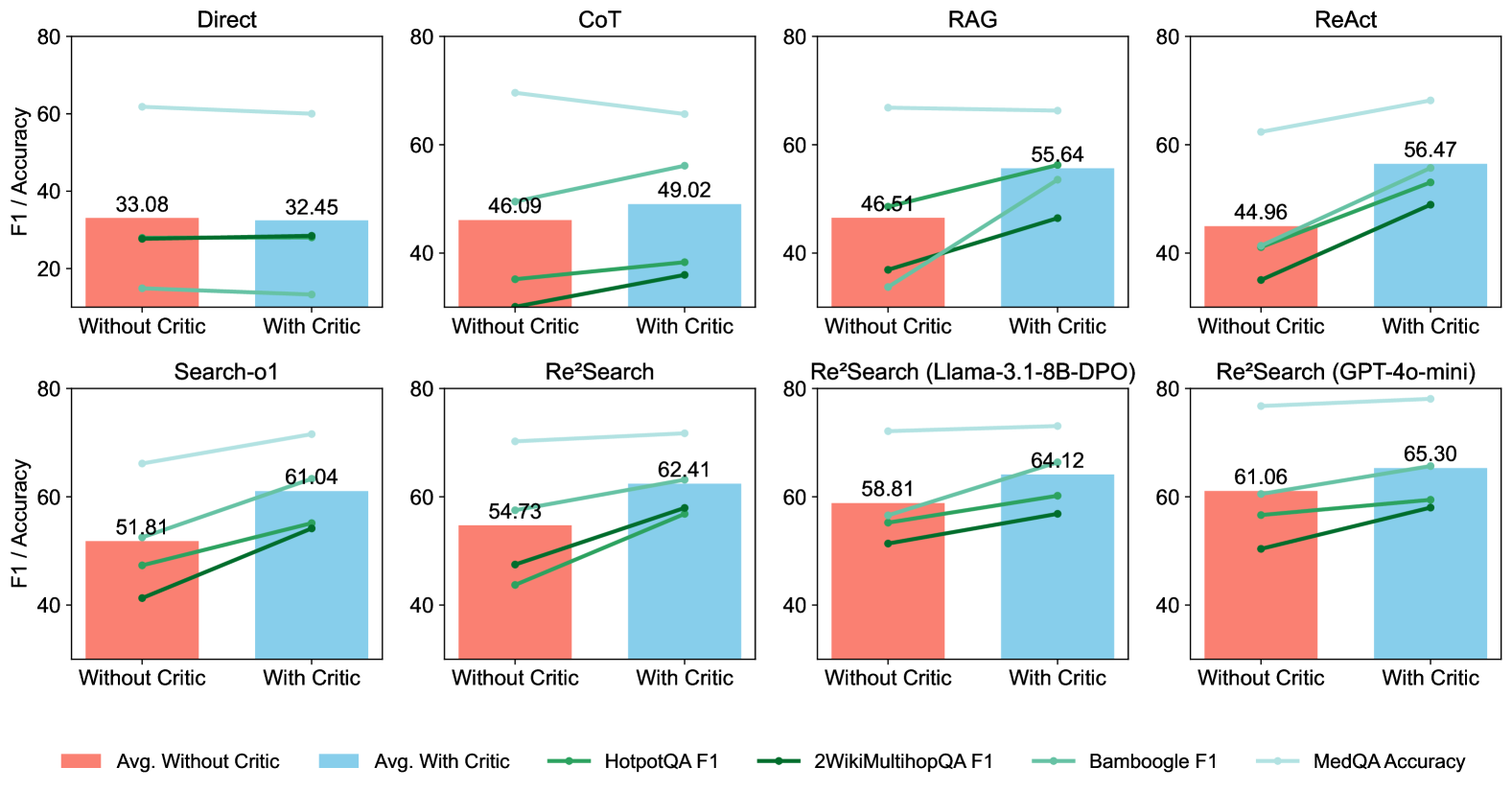
- Systematically benchmarks and integrates three optimization pillars: prompt engineering (Re2Search), actor tuning (finding DPO superior to PPO/SFT), and critic training (using a value model to select best intermediate steps)
Architecture
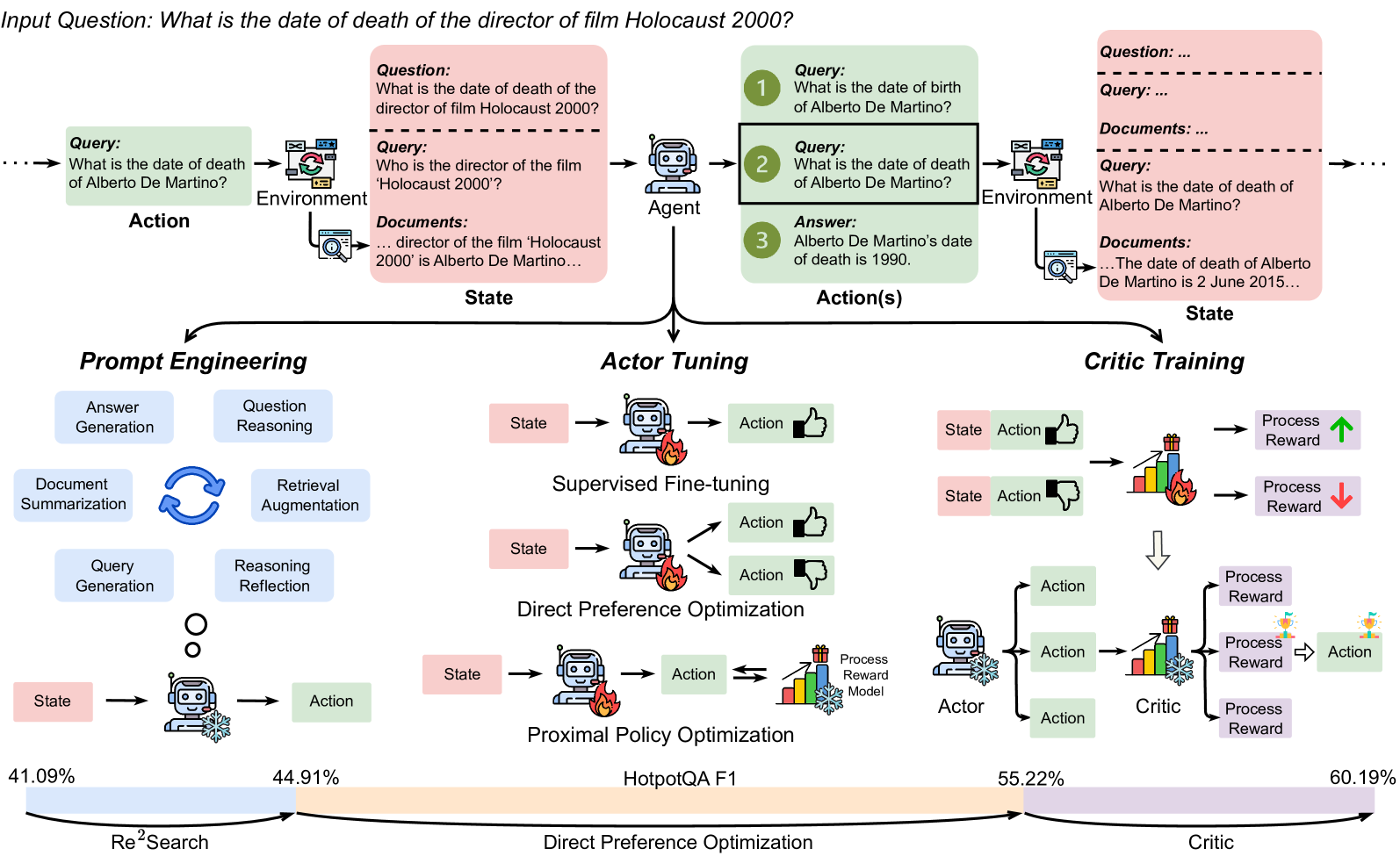
Overview of the RAG-Gym framework illustrating the interaction between the Re2Search agent, the environment, and the optimization process
Evaluation Highlights
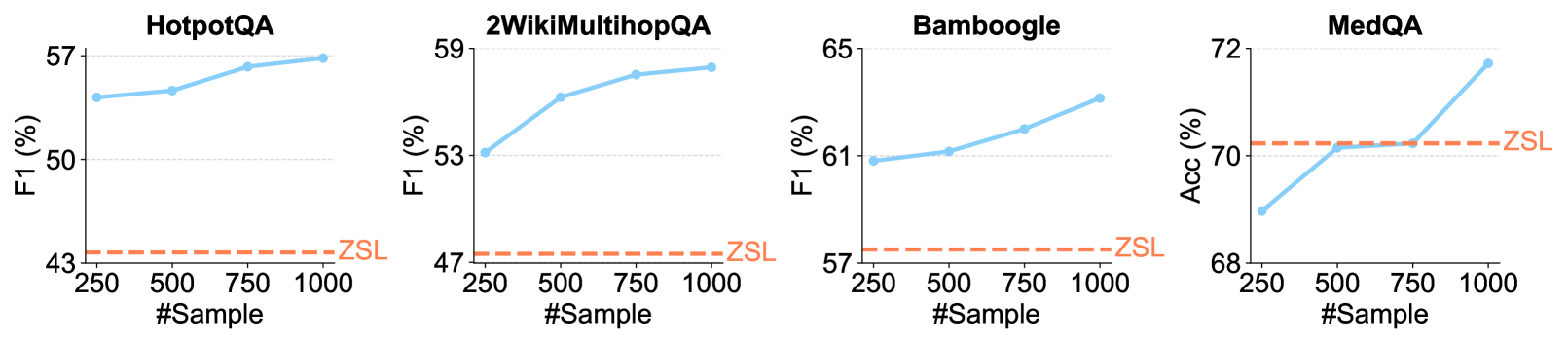
- Optimized Re2Search++ agent achieves +8.5% to +24.7% improvement in average F1 on unseen datasets compared to baselines
- Re2Search++ surpasses recent strong baselines like Search-R1 by +3.2% to +11.6% in average F1 across diverse knowledge-intensive tasks
- Process-level DPO outperforms outcome-based PPO and standard SFT, demonstrating the necessity of fine-grained supervision for agentic RAG
Breakthrough Assessment
8/10
Provides a highly systematic unification of prompting, SFT/DPO/PPO, and critic training for RAG. The empirical gain on unseen data is significant, establishing a strong recipe for agentic optimization.