📝 Paper Summary
Instruction Tuning
Data Curation
Curriculum Learning
CADC optimizes vision-language model instruction tuning by discovering latent capabilities from training dynamics and selecting data that balances and sequences these capabilities.
Core Problem
Reducing instruction tuning data often degrades model performance because heuristic selection methods treat models as black boxes, ignoring the specific latent capabilities required for complex tasks.
Why it matters:
- Standard data pruning methods (like heuristic filtering) often inadvertently remove data critical for specific skills (e.g., grounding or recognition), causing performance regression.
- Real-world tasks require multiple complementary capabilities; optimizing for one (like reasoning) while neglecting others leads to imbalanced models.
Concrete Example:
Analyzing a chemical reaction diagram requires recognition (identifying atoms) and reasoning (deducing pathways). If data selection disproportionately targets reasoning, the model fails because it loses the grounding capability needed to identify the atoms in the first place.
Key Novelty
Capability-Attributed Data Curation (CADC)
- Discovers intrinsic capabilities (latent skills) by clustering validation tasks based on the similarity of their gradient update trajectories during training.
- Attributes training data to these discovered capabilities by measuring how much a training sample's gradient aligns with the gradients of capability-specific validation sets.
- Curates a curriculum that balances data across capabilities and sequences them from fundamental to complex based on self-influence learning curves.
Architecture
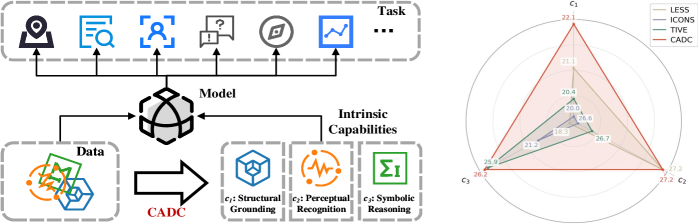
High-level overview of the CADC framework.
Evaluation Highlights
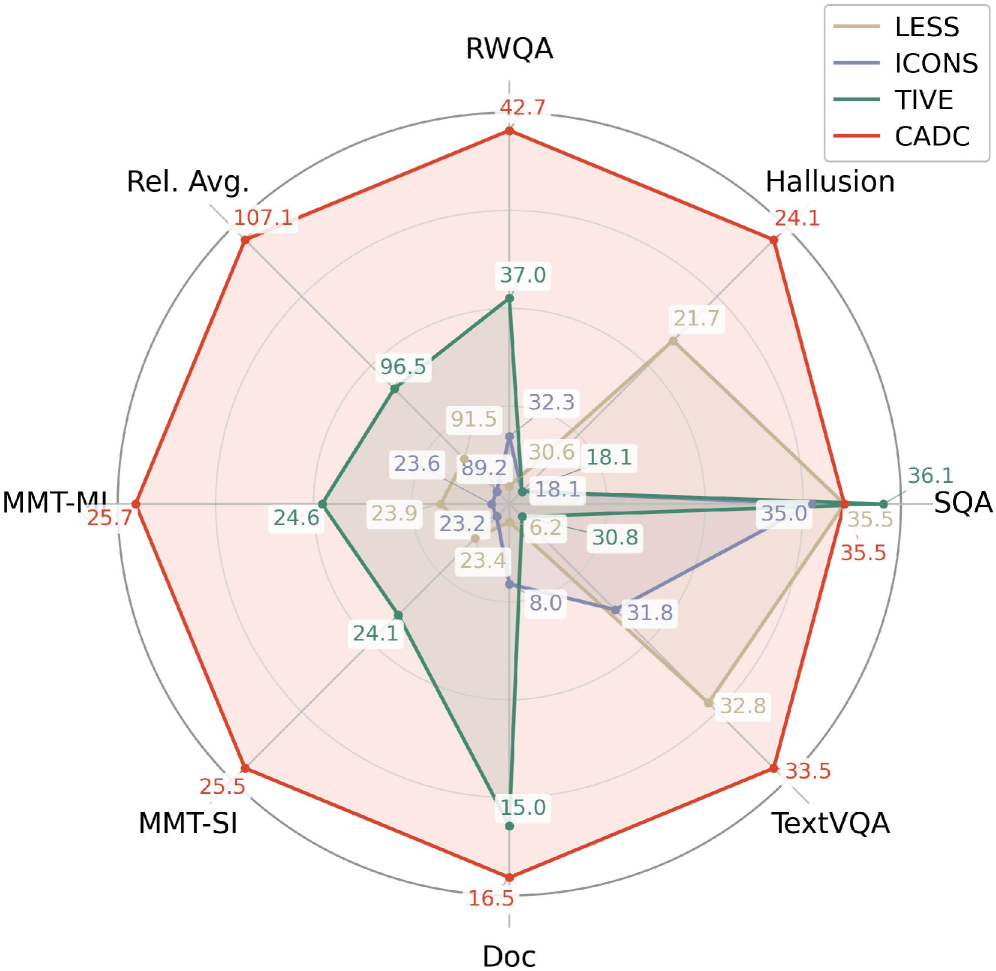
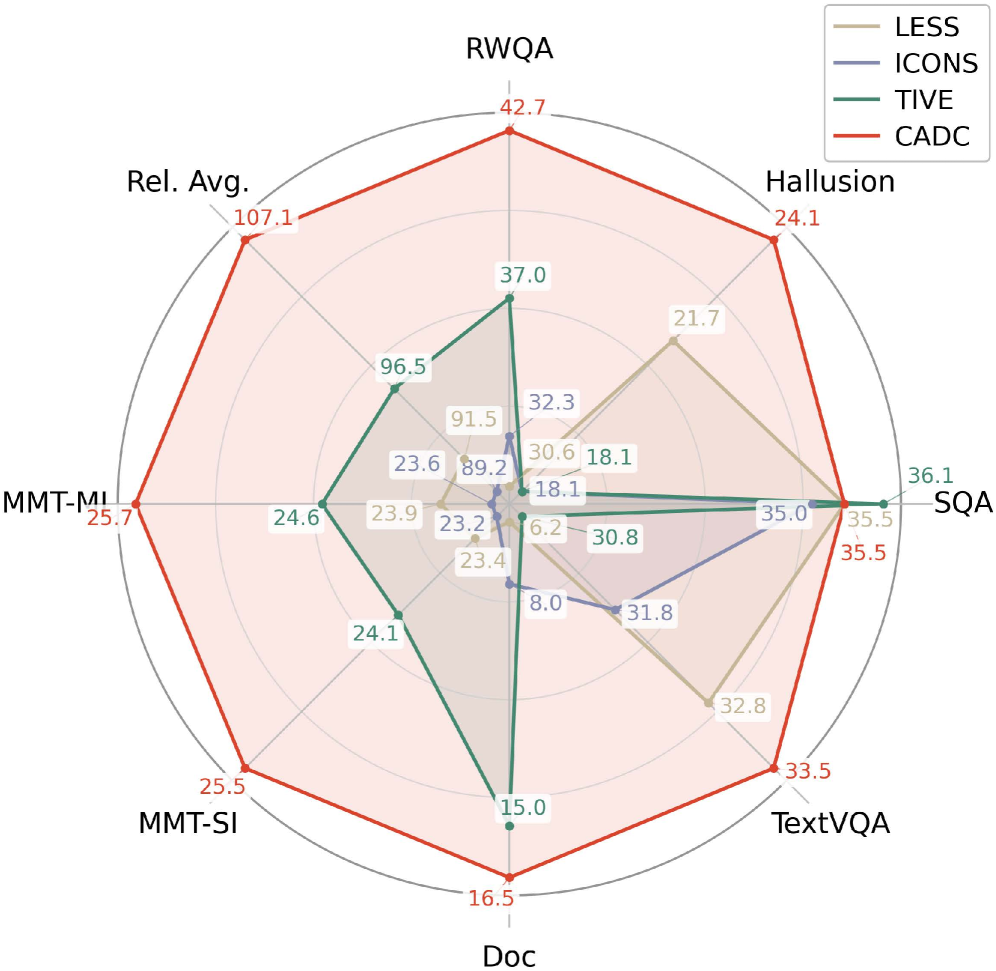
- Surpasses full-data training (100% budget) using only 5% of the original data on SmolVLM-256M (107.1% relative performance).
- Outperforms state-of-the-art pruning methods (TIVE, COINCIDE, ICONS) on LLaVA-7B benchmarks while using significantly less data (5% vs 15-20%).
- Achieves best or second-best performance across 11 diverse multimodal benchmarks, including LLaVA-Wild, MMBench, and HallusionBench.
Breakthrough Assessment
9/10
Strong conceptual novelty in replacing heuristic data selection with unsupervised capability discovery. The efficiency gain (beating 100% data with 5%) is exceptionally high compared to typical pruning results.