📝 Paper Summary
Multimodal RAG pipeline
Visual Document Understanding (VDU)
SV-RAG enables multimodal large language models to efficiently answer questions over long, visually-rich documents by using the MLLM itself as a visual retriever via hidden state embeddings.
Core Problem
Existing methods for long multimodal documents either rely on error-prone external parsers (OCR) or inefficiently feed all pages into MLLMs, causing context window overflow and distraction.
Why it matters:
- Real-world documents often contain hundreds of pages with complex layouts (charts, tables) where traditional text-only RAG fails
- Feeding entire long documents to MLLMs is computationally expensive and degrades performance due to irrelevant content
- External parsers often fail to preserve layout information, leading to information loss before the generation step
Concrete Example:
When asking a specific question about a chart on page 50 of a 100-page report, a standard MLLM might hallucinate due to context overload, while a parser-based RAG might fail to extract the chart data correctly. SV-RAG retrieves just the relevant page image to answer accurate.
Key Novelty
Self-Visual Retrieval-Augmented Generation (SV-RAG)
- Uses the MLLM's own intermediate hidden states as visual embeddings for retrieval, eliminating the need for separate vision encoders or OCR parsers
- Employs a 'contextualized late interaction' scoring mechanism (similar to ColBERT) to match question tokens directly with page image patches for fine-grained relevance
- Utilizes dual LoRA adapters (one for retrieval, one for generation) to specialize a single frozen MLLM backbone for both tasks efficiently
Architecture
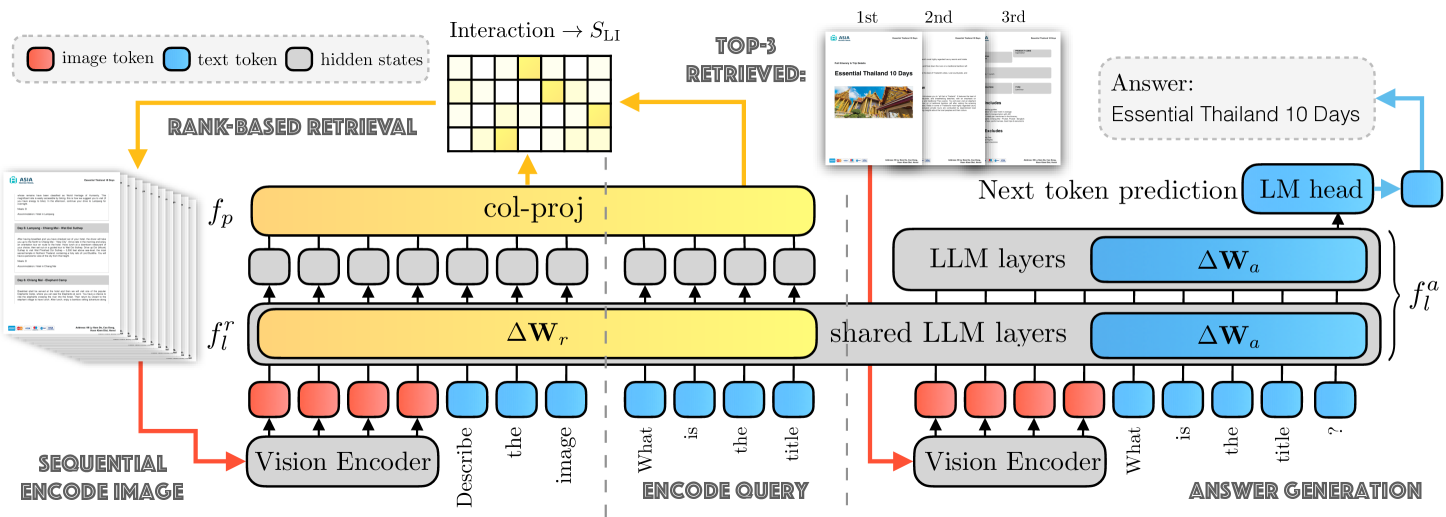
The SV-RAG architecture featuring shared Vision Encoder and LLM backbone with split paths for Retrieval and QA via different LoRA adapters.
Evaluation Highlights
- Achieves state-of-the-art performance on 4 public benchmarks (DocVQA, InfoVQA, etc.), rivaling proprietary models like Gemini-1.5-pro on MMLongBench-Doc
- Outperforms baseline embeddings (CLIP, BGE) by significant margins using a 4B parameter model
- Demonstrates high efficiency by sharing the vision encoder and LLM backbone between retrieval and generation modules
Breakthrough Assessment
8/10
Significantly advances multimodal RAG by proving MLLMs can act as strong retrievers without external parsers, offering a streamlined, layout-aware solution for long documents.