📝 Paper Summary
Knowledge Graph Reasoning
Reasoning with Limited External Knowledge
GIVE is a training-free framework that enhances LLM reasoning by extrapolating limited expert knowledge into broader concept groups and generating counterfactuals to suppress hallucinations.
Core Problem
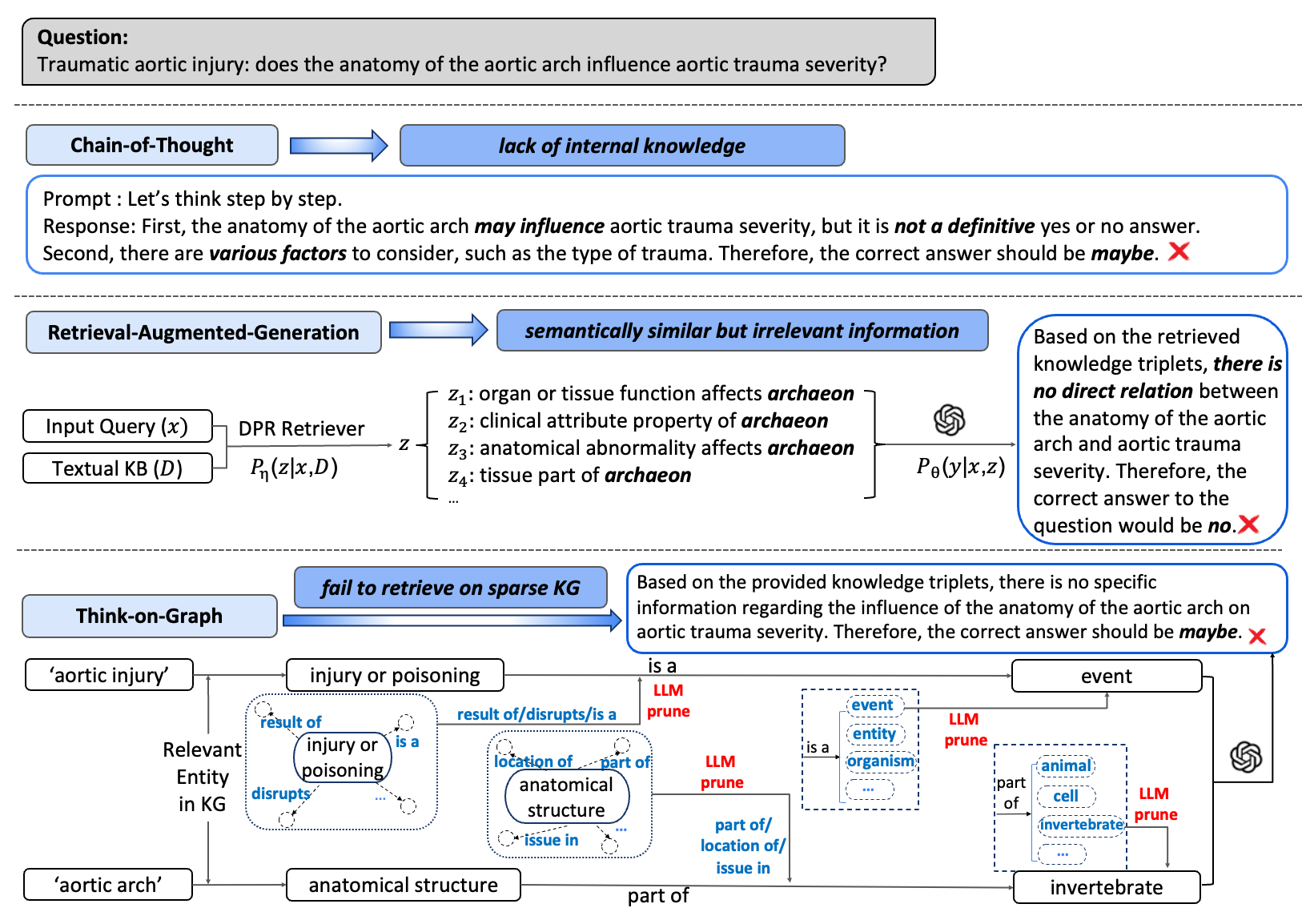
LLMs struggle with scientific reasoning due to insufficient pre-trained knowledge, while full retrieval (RAG) fails when comprehensive knowledge bases are unavailable or too costly to build.
Why it matters:
- Constructing comprehensive scientific knowledge bases is expensive and difficult due to non-standardized vocabulary.
- Existing methods rely either on internal knowledge (prone to hallucination in niche domains) or perfect retrieval (often unavailable), failing in realistic low-resource settings.
Concrete Example:
When asking if 'melatonin is effective for insomnia', a standard RAG might fail if the direct link is missing. GIVE infers the answer by linking melatonin to similar compounds and deducing relationships via intermediate biological concepts, rather than giving up or hallucinating.
Key Novelty
Graph Inspired Veracity Extrapolation (GIVE)
- Expands single queried entities into 'Entity Groups' containing semantically similar concepts from the Knowledge Graph to broaden the reasoning scope.
- Generates 'Veracity Extrapolation' by prompting the LLM to validate potential links between these groups using internal parametric knowledge.
- Explicitly creates 'Counterfactual Knowledge' from rejected links to prevent the model from hallucinating incorrect connections during final answer generation.
Architecture
The GIVE workflow: Query → Entity Extraction → Entity Grouping (clustering similar KG nodes) → Relation Induction (finding paths) → Veracity Extrapolation (validating/rejecting paths) → Answer Generation.
Evaluation Highlights
- GIVE enables GPT-3.5-Turbo to outperform GPT-4 on scientific tasks (PubmedQA, BioASQ) using only a small 135-node knowledge graph.
- Improves accuracy by up to 43.5% → 88.2% on tasks extending beyond training data compared to standard prompting baselines.
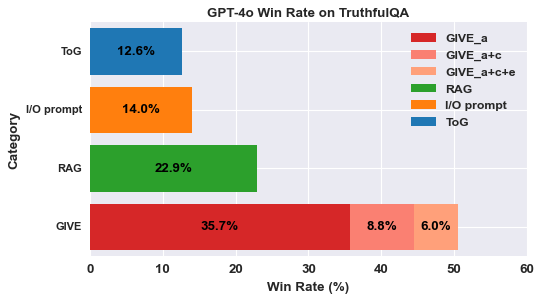
- Achieves highest win rate on TruthfulQA (50.3%) against RAG and ToG baselines, demonstrating effectiveness in open-domain reasoning.
Breakthrough Assessment
8/10
Strong methodological innovation in handling sparse/noisy knowledge. The ability for smaller models to beat larger ones in scientific domains via structured extrapolation is significant.