📝 Paper Summary
Unsupervised Alignment
Reward Modeling
ICM fine-tunes pretrained models on tasks by searching for label assignments that are mutually predictable and logically consistent according to the model itself, without external human supervision.
Core Problem
Post-training typically relies on human supervision, which becomes unreliable or impossible to obtain for superhuman capabilities or complex tasks where humans make mistakes.
Why it matters:
- Obtaining high-quality human labels for frontier models is expensive and increasingly difficult as models surpass human performance
- Current methods like RLHF are limited by human biases and errors, potentially capping model performance at human levels
- Models already possess latent concepts (truthfulness, helpfulness) from pretraining that are not fully utilized by standard prompting
Concrete Example:
In an author gender prediction task, humans often rely on superficial stereotypes, achieving only 60% accuracy. The pretrained model contains deeper linguistic patterns but needs a way to surface them without being trained on the low-quality human labels.
Key Novelty
Internal Coherence Maximization (ICM)
- Defines a scoring function based on 'mutual predictability'—how well the model can predict one label given all others—and 'logical consistency' (e.g., A>B implies B<A)
- Uses a simulated annealing-inspired search algorithm to find the specific label assignment for a dataset that maximizes this internal coherence score
- Fine-tunes the model on these self-generated, coherent labels instead of external ground truth
Architecture
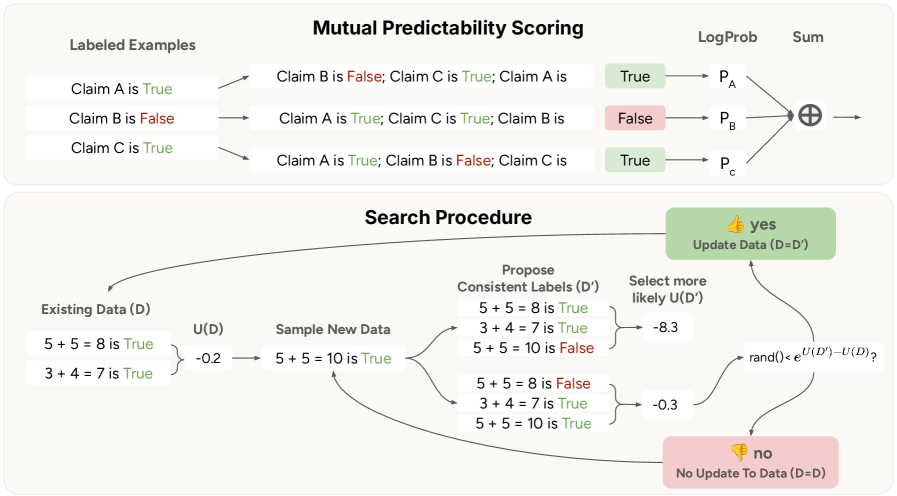
Illustration of the Mutual Predictability concept and the ICM iterative search process
Evaluation Highlights
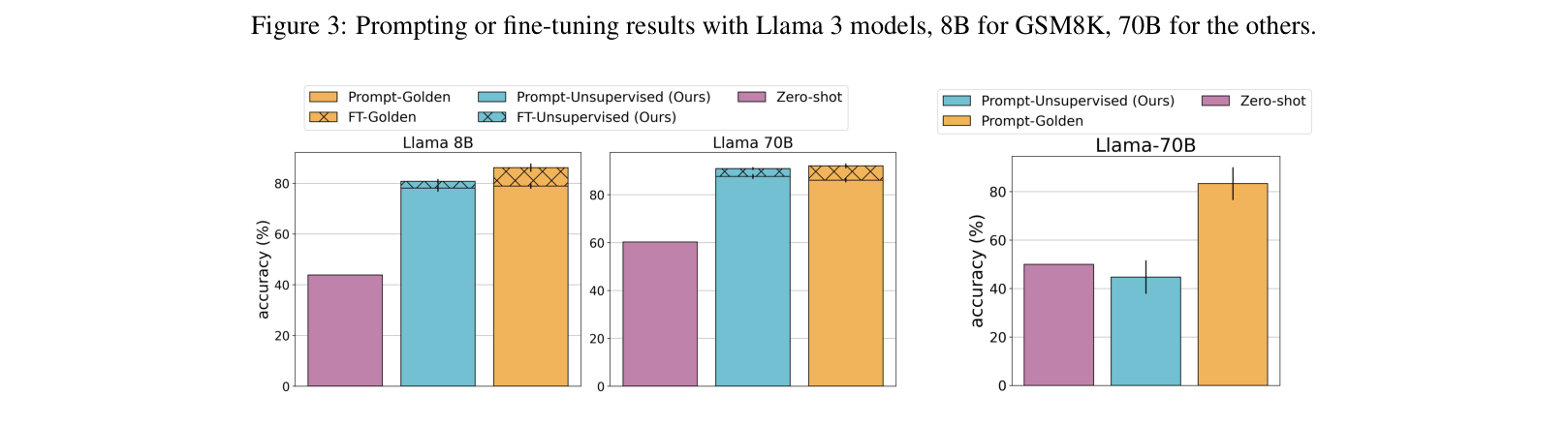
- Matches golden label performance on GSM8K and TruthfulQA using Llama-3-70B, despite using zero external labels
- Achieves ~80% accuracy on author gender prediction (a superhuman task), significantly outperforming human annotators (60%)
- An unsupervised Claude 4 Sonnet assistant trained via ICM matches a human-supervised counterpart on average, with higher scores on chat and safety metrics
Breakthrough Assessment
9/10
Demonstrates successful alignment of a frontier model (Claude 4 Sonnet) without ANY human supervision, matching human-supervised performance in a realistic setting. A significant step for superhuman oversight.