📝 Paper Summary
Modularized RAG pipeline
Agentic RAG pipeline
RRR (Rewrite-Retrieve-Rerank) is an iterative zero-shot retrieval framework that cycles between RAG-based query rewriting and GAR-based retrieval to maximize recall, followed by LLM-based re-ranking to maximize precision.
Core Problem
Existing zero-shot retrieval paradigms like GAR and RAG struggle because high-recall retrieval is difficult without domain data, and high-precision re-ranking requires a good initial document set.
Why it matters:
- Zero-shot settings lack training data, making it hard to calibrate retrieval scores or fine-tune dense retrievers
- GAR (query expansion) depends heavily on the quality of generated context, while RAG (answer generation) depends on the quality of retrieved documents
- Current methods treat rewrite, retrieve, and re-rank as separate stages without a feedback loop to refine the query intent
Concrete Example:
For the query 'How diet soda could make us gain weight?', a standard retriever fetches irrelevant documents about 'whole grain intake' or 'caloric restriction'. RRR uses these initial results to generate a better query rewrite ('Effects of artificial sweeteners on weight gain'), which then retrieves the correct document about 'antioxidant-rich spices'.
Key Novelty
GAR-meets-RAG Recurrence (RRR)
- Formulate retrieval as a recurring loop where a RAG model generates a query rewrite, which feeds into a GAR model for retrieval, which in turn feeds back into the RAG model
- Use a relevance-based filtering step within the loop to remove spurious documents (false positives) before they corrupt the next query rewrite
- Decouple recall and precision objectives: the iterative loop maximizes recall, while a final LLM-based re-ranker maximizes precision
Architecture
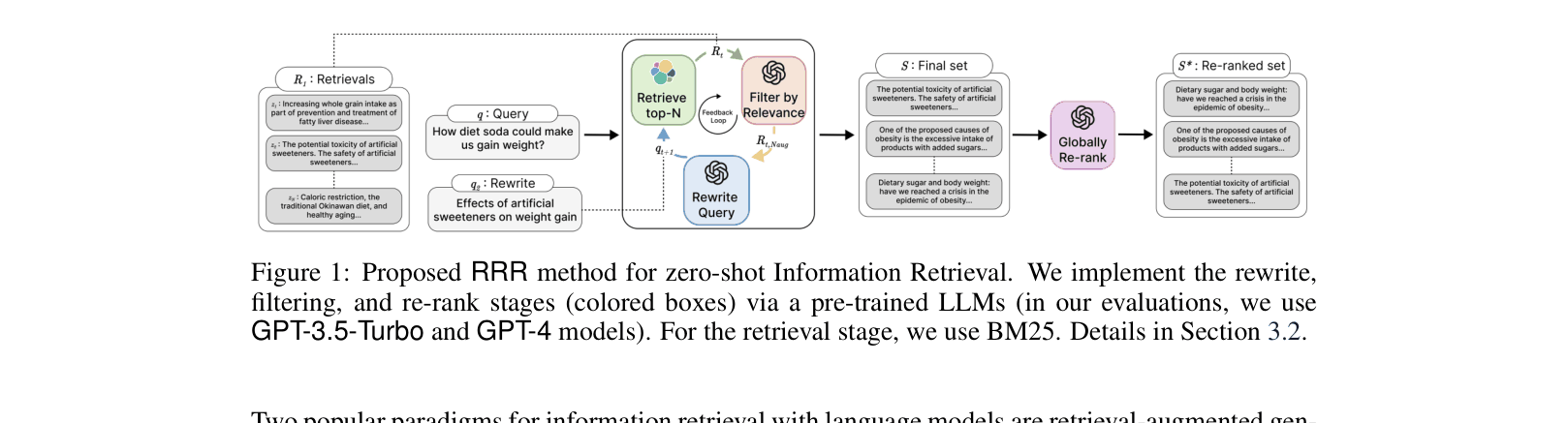
The iterative Rewrite-Retrieve-Rerank (RRR) workflow.
Evaluation Highlights
- Achieves new state-of-the-art on 6 out of 8 BEIR datasets for Recall@100 and nDCG@10 metrics in zero-shot settings
- Outperforms RankGPT by +17% relative gain in nDCG@10 on specific datasets within the BEIR benchmark
- Improves Recall@100 on TREC-DL 20 by +3.5 points (58.6 vs 55.1) when increasing rewrite iterations from 1 to 5
Breakthrough Assessment
8/10
Significant performance gains on standard benchmarks without training. The iterative feedback loop between GAR and RAG is a clever, high-impact architectural pattern for zero-shot IR.