📝 Paper Summary
Modularized RAG pipeline
Security and Privacy in RAG
The paper establishes the first formal threat model for RAG systems by defining a taxonomy of adversaries and formalizing specific risks like document-level membership inference and poisoning.
Core Problem
RAG systems inherit LLM vulnerabilities but also introduce new attack surfaces via external knowledge bases, yet no formal framework currently exists to define this specific threat landscape.
Why it matters:
- Adversaries can exploit RAG's reliance on external data to infer the existence of sensitive documents (e.g., patient records) even if they aren't explicitly output
- Attackers can inject malicious content into the retrieval base to manipulate model behavior, a risk distinct from traditional LLM training data poisoning
- Without formal definitions of threats like 'document-level membership inference', it is difficult to design rigorous defenses for RAG deployments in regulated industries
Concrete Example:
In a healthcare setting, an attacker might query a RAG-powered assistant about a specific rare diagnosis. If the system's response changes based on the presence of a specific patient's record in the retrieval index, the attacker can infer that patient's inclusion in the database, violating privacy even without seeing the record itself.
Key Novelty
Formal Threat Framework for RAG
- Introduces a structured taxonomy of RAG adversaries based on two dimensions: their level of access to the model (black-box vs. white-box) and their knowledge of the data (aware vs. unaware)
- Formalizes 'Document-Level Membership Inference' (DL-MIA) specifically for RAG, defining it as the ability to distinguish whether a specific document exists in the external knowledge base based on system outputs
- Proposes using Retriever-Level Differential Privacy as a theoretical mitigation strategy, where noise is added to relevance scores to mask the presence of individual documents
Architecture
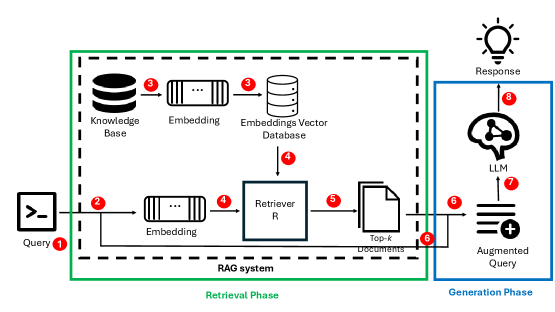
The standard RAG system model and data flow, highlighting the interaction between User, Knowledge Base, Retriever, and Generator.
Evaluation Highlights
- This is a theoretical position paper proposing formal definitions; it does not report empirical experimental results.
- Defines four distinct adversary types: Unaware Observer, Aware Observer, Aware Insider, and Unaware Insider.
- Formalizes the definition of (ε, δ)-differential privacy specifically for RAG retrievers to mitigate membership inference.
Breakthrough Assessment
7/10
Foundational work that fills a critical gap by formalizing security definitions for RAG. While it lacks empirical evaluation, the taxonomy and formal definitions provide a necessary basis for future security research.