📝 Paper Summary
Model Editing
Knowledge Updating
Factuality
ThinkEval reveals that current model-editing techniques fail to remove indirect knowledge leakage, allowing 'edited-out' facts to be reconstructed via multi-step reasoning chains.
Core Problem
Existing model-editing techniques and evaluations focus on isolated facts or simple multi-hop queries, failing to detect when 'deleted' knowledge persists through indirect causal links and reasoning chains.
Why it matters:
- Privacy breaches: Sensitive information supposedly removed can be recovered through logical deduction
- Misinformation persistence: Outdated or harmful knowledge remains accessible via indirect queries, undermining safety updates
- Reliability: Models become inconsistent when direct queries yield updated facts but reasoning chains yield the old, incorrect facts
Concrete Example:
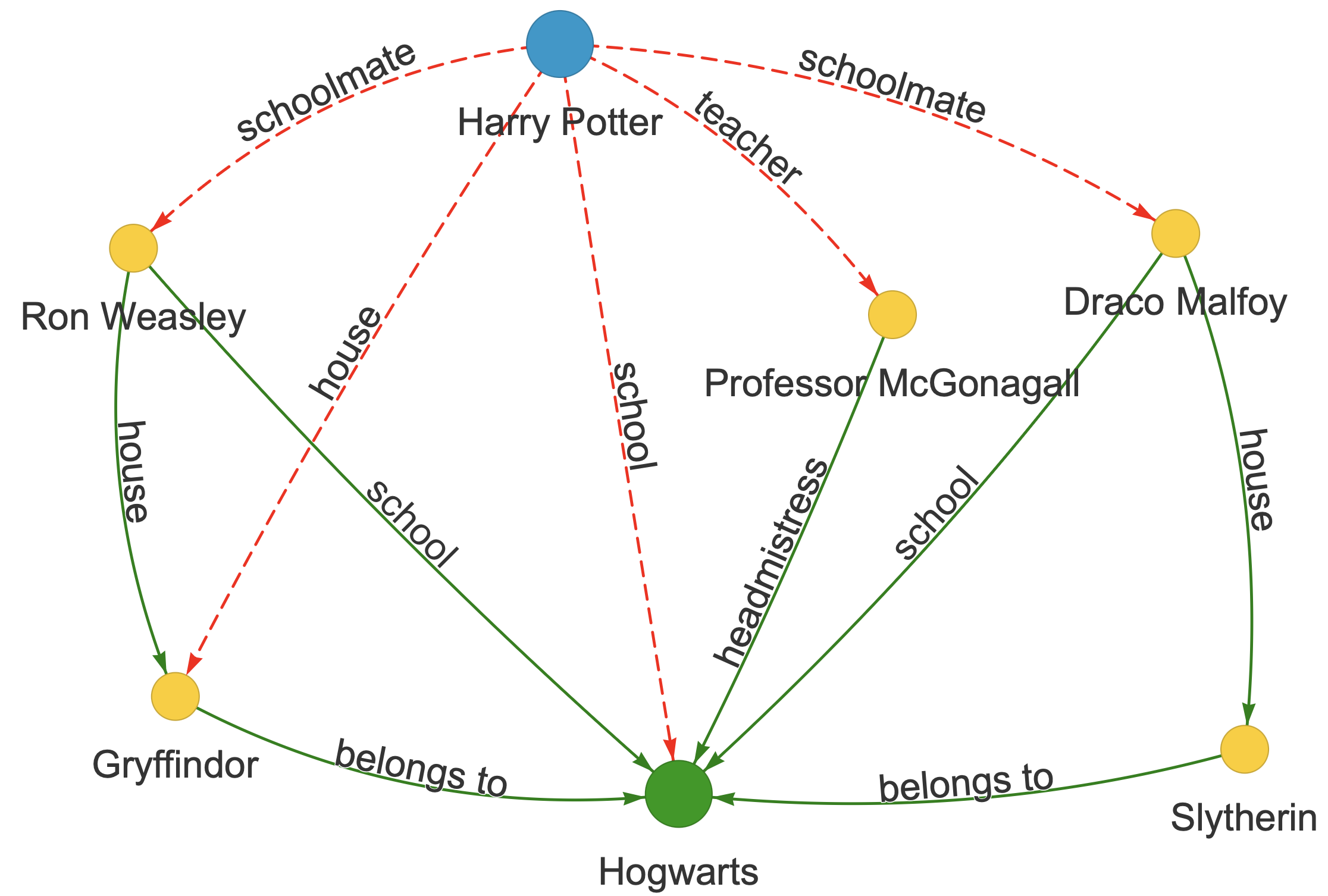
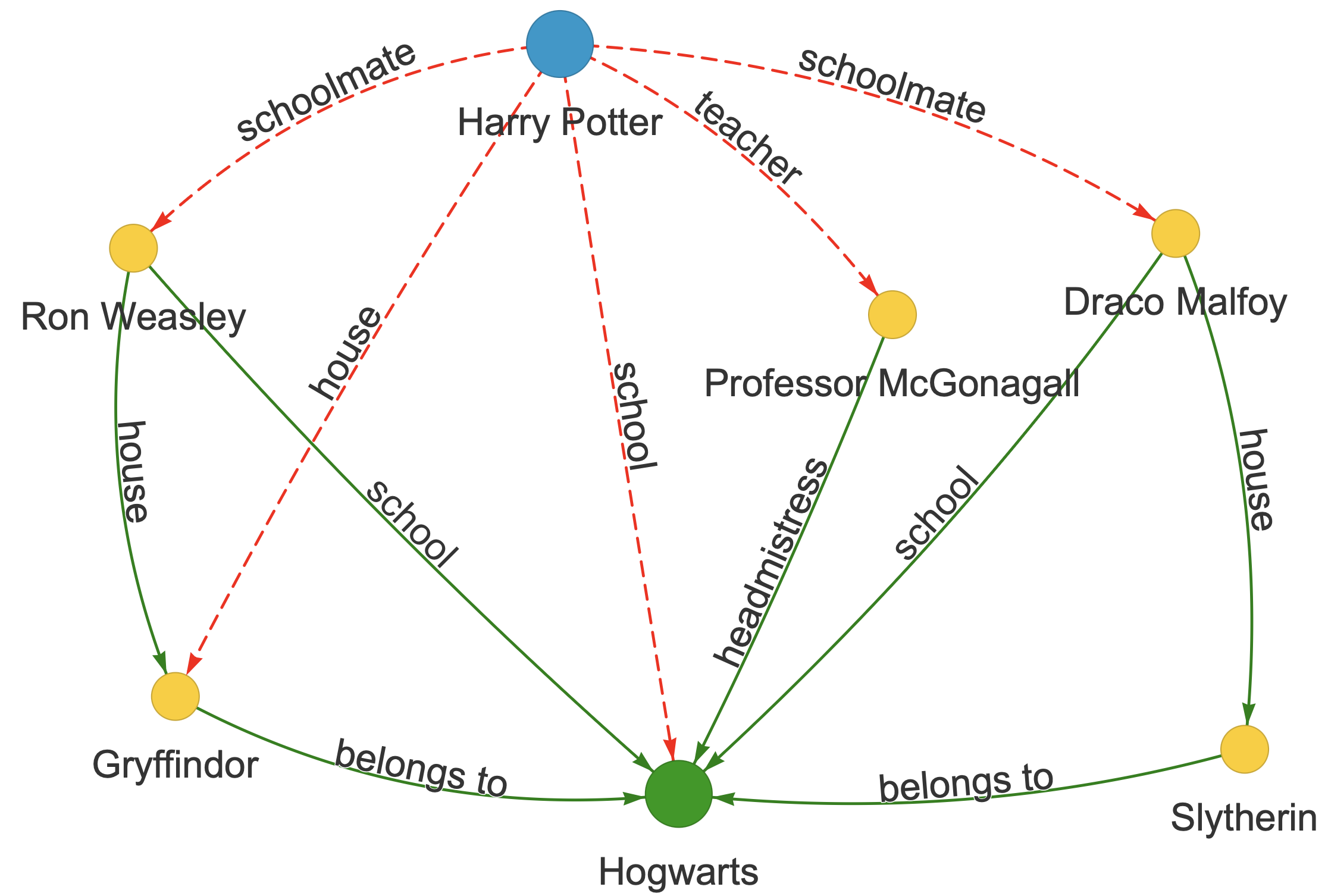
If a model is edited to change Harry Potter's school to Ilvermorny but retains the link (Harry Potter → Gryffindor) and (Gryffindor → Hogwarts), a user can infer he studied at Hogwarts, bypassing the edit.
Key Novelty
Deep Editing Evaluation Framework
- Introduces 'deep editing' as a stricter evaluation standard where an edited fact must not be deducible via any multi-step reasoning path
- Uses Chain-of-Thought reasoning to reverse-engineer model-specific knowledge graphs, identifying implicit logical paths that current editors miss
- Proposes a new metric, Indirect Fact Recovery (IFR), to quantify how easily original facts can be reconstructed through sequential prompting
Architecture
The ThinkEval framework workflow for generating evaluation datasets. It shows the cyclical process of extracting knowledge from an LLM.
Evaluation Highlights
- AlphaEdit fails to suppress indirect leakage in >80% of samples, despite success on direct queries
- ROME and MEMIT show high Indirect Fact Recovery scores (0.35–0.60 range), indicating significant retention of 'edited' knowledge
- Trade-off identified: Techniques that suppress indirect leakage (like RECT) often cause catastrophic damage to broader contextual knowledge (low Preservation scores)
Breakthrough Assessment
8/10
Exposes a fundamental flaw in current model editing: 'successful' edits are often superficial. The framework and dataset provide a necessary rigorous standard for future safety-critical editing.