📝 Paper Summary
Agentic RAG pipeline
Modularized RAG pipeline
MCTS-RAG integrates Monte Carlo Tree Search with adaptive retrieval to refine reasoning paths, dynamically acquiring external knowledge only when needed to solve complex queries.
Core Problem
Small language models struggle with knowledge-intensive tasks because standard RAG retrieves information independently of reasoning, while existing reasoning frameworks (like rStar) rely solely on internal knowledge.
Why it matters:
- Standard RAG often retrieves irrelevant or repetitive information because it lacks the ability to refine queries iteratively based on reasoning progress
- Models like Llama-3-8B perform poorly on complex tasks compared to frontier models like GPT-4o due to weak internal knowledge and poor query formulation
- Existing search-based reasoning methods (e.g., rStar) fail on knowledge-intensive queries because they cannot fetch external facts dynamically
Concrete Example:
For the question 'Which novel inspired the movie that won Best Picture in 1994?', standard RAG might just retrieve documents about 'Forrest Gump' but fail to search for the novel written by Winston Groom because it doesn't recognize the need for a second hop.
Key Novelty
Integration of Retrieval into MCTS Action Space
- Expands the action space of Monte Carlo Tree Search to include specific retrieval actions (Retrieval Reasoning, Retrieval Decompose) alongside standard reasoning steps
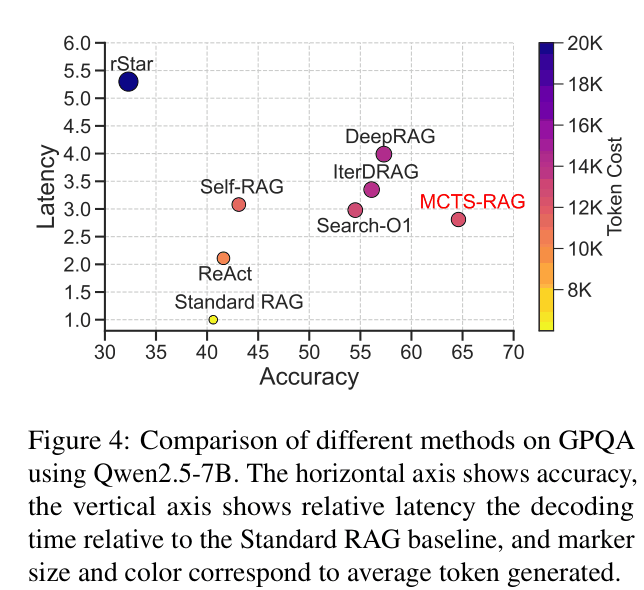
- Uses a parallel expansion strategy and dynamic pruning to evaluate multiple reasoning/retrieval paths simultaneously, reducing the latency typically associated with tree search
Architecture
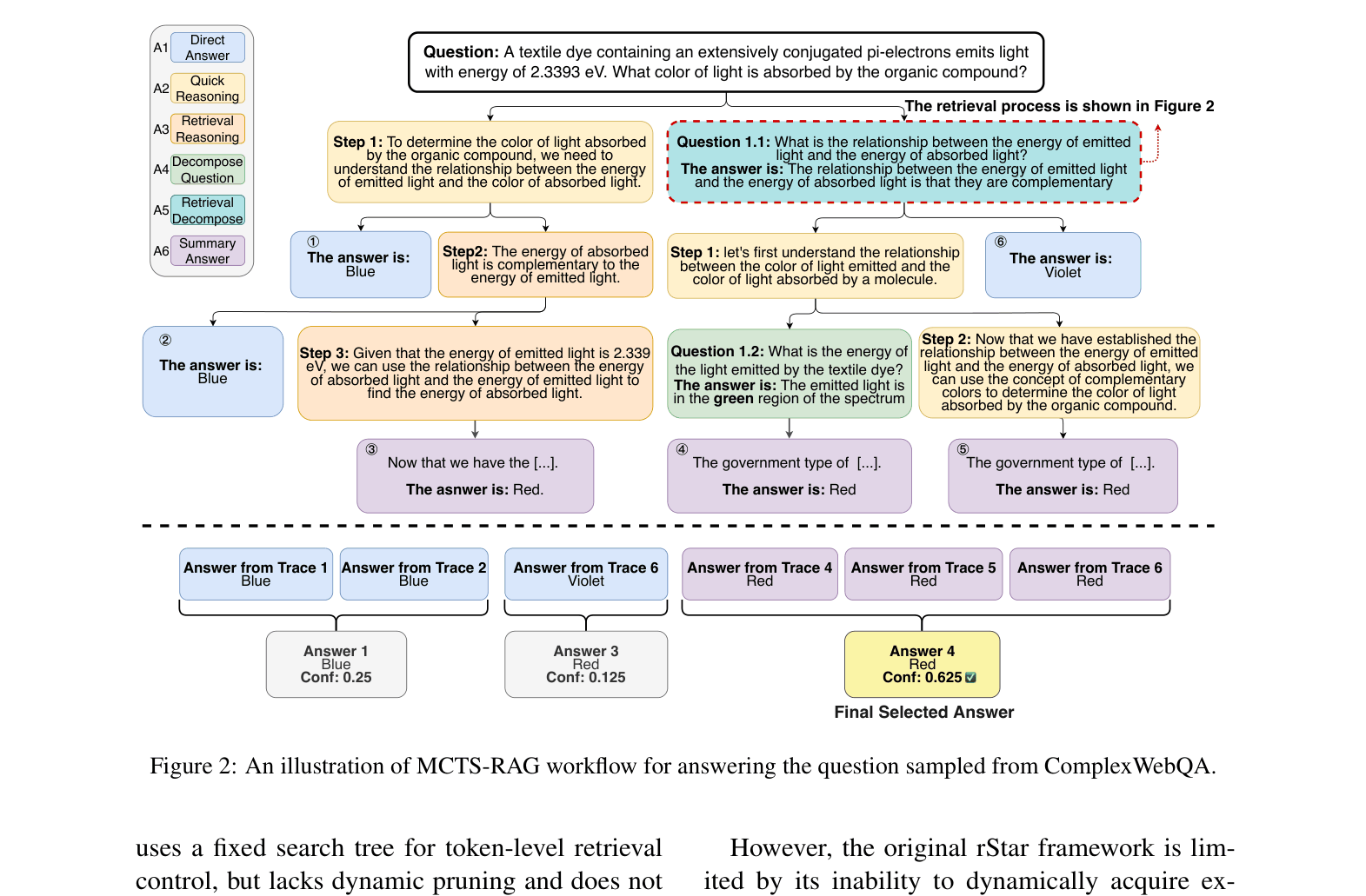
The workflow of MCTS-RAG answering a question from ComplexWebQA.
Evaluation Highlights
- +20% accuracy improvement on ComplexWebQA using Llama 3.1-8B compared to standard RAG baselines
- Achieves comparable performance to GPT-4o on GPQA and ComplexWebQA using only small-scale models (Llama 3.1-8B and Qwen2.5-7B)
- Reduces hallucination and amplification errors by validating retrieval steps within the reasoning tree structure
Breakthrough Assessment
8/10
Significantly bridges the gap between small open weights models and GPT-4o on hard reasoning tasks by effectively combining search with retrieval.