📝 Paper Summary
Agentic RAG pipeline
Embodied AI planning
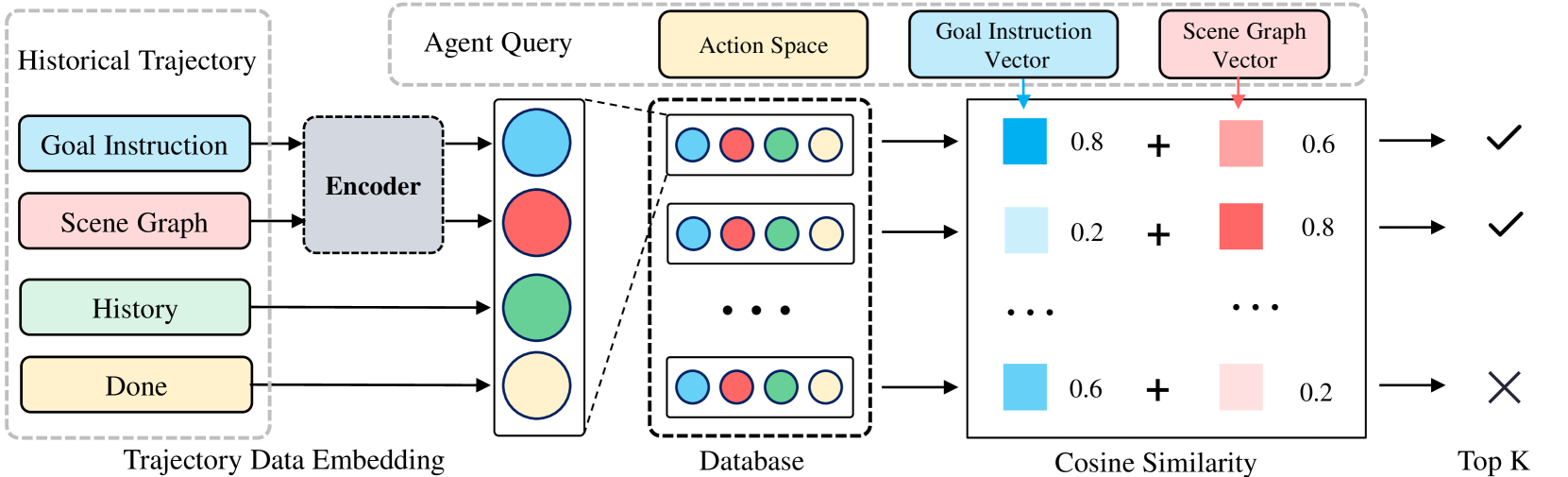
P-RAG improves embodied agent planning by iteratively building a database of the agent's own successful historical trajectories (instead of ground truth) and retrieving them based on task and scene similarity.
Core Problem
Traditional embodied agents struggle with understanding natural language instructions and lack task-specific knowledge, while LLM-based planners often hallucinate invalid actions or rely on unrealistic ground-truth data for few-shot examples.
Why it matters:
- Real-world environments have hidden constraints (e.g., table capacity limits) that pre-trained LLMs do not know.
- Relying on ground-truth for few-shot prompting is not scalable or realistic for novel, interactive environments where the optimal path is unknown.
- Environments lack dense rewards (binary 0/1 feedback), making it hard for agents to learn sub-steps without explicit guidance or prior experience.
Concrete Example:
In a simulation where a table can only hold three items, a standard LLM might command 'put apple on table' as a fourth item because it lacks specific environmental knowledge. P-RAG would retrieve a past failed attempt or successful constraint-abiding trajectory to avoid this error.
Key Novelty
Progressive Retrieval Augmented Generation (P-RAG)
- Builds a dynamic memory database from the agent's own interaction history (self-generated experience) rather than static expert demonstrations.
- Updates the database iteratively after each round, progressively accumulating successful trajectories to serve as few-shot examples for future tasks.
- Uses a dual-retrieval mechanism that matches not just similar task instructions (semantic similarity) but also similar visual scene graphs (situational similarity).
Architecture
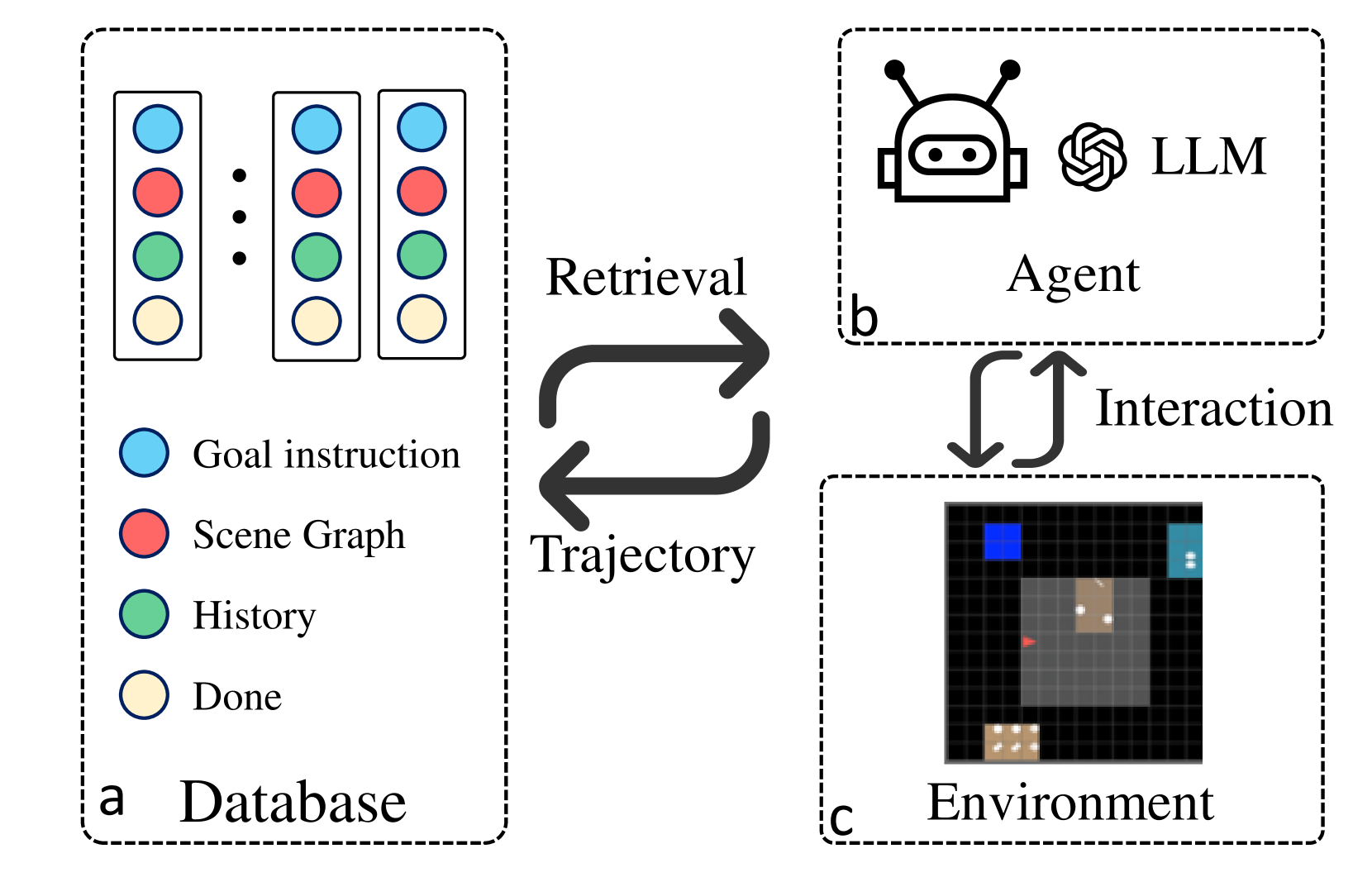
High-level framework of P-RAG illustrating the progressive loop.
Evaluation Highlights
- Outperforms standard RAG and LLM-Planner baselines without using any ground truth actions for few-shot prompting.
- Demonstrates self-improvement capabilities, increasing success rates over iterations as the retrieval database populates with better self-generated trajectories.
- Achieves competitive performance on ALFRED and MINI-BEHAVIOR benchmarks compared to methods requiring extensive training or ground truth.
Breakthrough Assessment
7/10
Novel approach to 'ground truth-free' planning by bootstrapping from self-experience. While the retrieval mechanics are standard, the iterative self-building database for embodied planning is a significant practical step forward.