📝 Paper Summary
RAG Privacy & Security
Copyright Protection
Membership Inference
WARD enables data owners to provably detect if their documents were used in a RAG system by embedding LLM watermarks that persist through the retrieval and generation pipeline.
Core Problem
Data owners currently have no way to prove unauthorized usage of their content in RAG systems, and existing methods (Membership Inference Attacks) are unreliable in realistic settings.
Why it matters:
- Copyright holders need technical tools to audit RAG providers and enforce opt-out requests
- Current baselines fail when RAG corpora contain redundant facts (multiple documents sharing information), a common real-world scenario
- False accusations against model providers must be statistically controlled to ensure trust in auditing tools
Concrete Example:
A RAG provider scrapes a news site. The owner wants to check if their articles are in the corpus. Existing methods get confused if the same news facts appear in other authorized documents. WARD succeeds by checking for a specific watermark pattern that only the owner's documents possess.
Key Novelty
Proactive RAG Dataset Inference via Watermarking
- Instead of relying on post-hoc analysis of model outputs (like perplexity), the data owner proactively watermarks their documents before publication
- The method (WARD) leverages the property that red-green watermarks propagate through RAG: if the LLM retrieves a watermarked document, the generated answer retains statistical traces of the watermark
- Aggregates weak signals across multiple queries into a single rigorous statistical test (p-value) for the entire dataset
Architecture
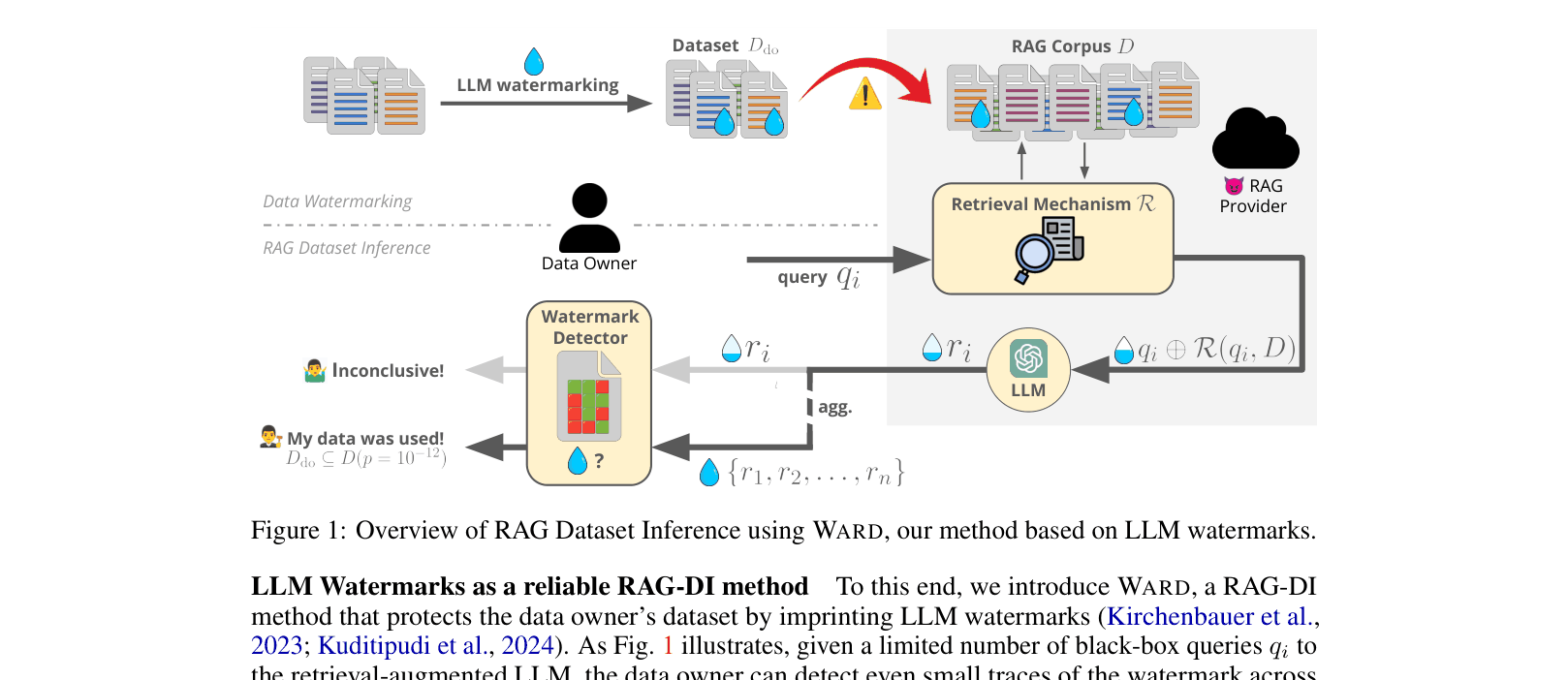
Workflow of WARD: Data Owner watermarks data -> RAG Provider scrapes it -> Owner queries RAG -> Detects watermark in aggregated responses
Evaluation Highlights
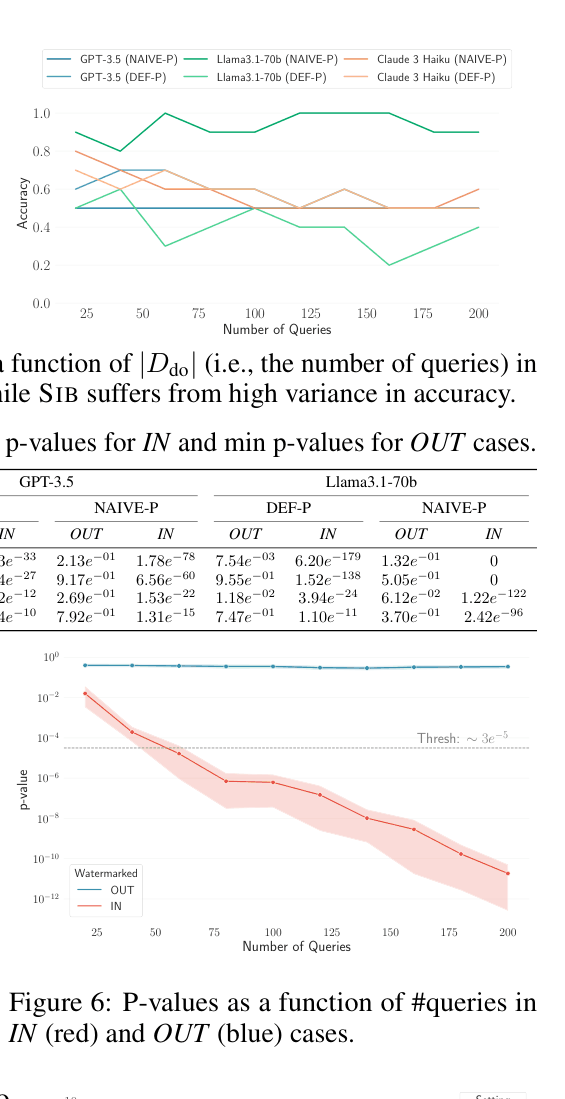
- Achieves 100% accuracy in detecting dataset usage across all tested models (Llama-3, Claude-3, GPT-3.5) and settings
- Maintains 0 false positives even when RAG providers use defensive prompts designed to prevent data leakage
- Outperforms state-of-the-art baselines (SIB, AAG) which fail near-completely in realistic settings with fact redundancy
Breakthrough Assessment
9/10
Establishes a new problem setting (RAG-DI), provides the first rigorous benchmark (FARAD), and proposes a solution that essentially solves the problem (100% accuracy, provable guarantees) where baselines fail.