📝 Paper Summary
Modularized RAG pipeline
Metrics and evaluation
RAG-RewardBench is a comprehensive benchmark for evaluating reward models in retrieval-augmented generation settings, featuring 1,485 preference pairs across four RAG-specific scenarios to guide preference-aligned training.
Core Problem
Existing reward models (RMs) are evaluated on general chat or reasoning tasks but lack specific evaluation for RAG scenarios, where alignment requirements differ (e.g., faithfulness to citations, handling conflicts).
Why it matters:
- Supervised Fine-Tuning (SFT) often causes RAG models to overfit training data or halluciante, lacking a feedback mechanism for human preferences
- Standard RMs do not account for RAG-specific needs like privacy protection, correct citation attribution, or abstaining when retrieval fails
- Current RAG systems are prone to citing satirical/harmful content or generating unfaithful responses due to noise, requiring better alignment signals
Concrete Example:
An SFT-trained RAG model might cite satirical content from the internet to generate a harmful response, or fabricate an answer when retrieved documents are insufficient, whereas a preference-aligned model should abstain or reject the harmful source.
Key Novelty
First dedicated benchmark for RAG Reward Models (RAG-RewardBench)
- Defines four novel RAG-specific evaluation scenarios: multi-hop reasoning consistency, fine-grained citation accuracy, appropriate abstention from answering, and robustness to conflicting information
- Uses an LLM-as-a-judge approach with strict consistency filtering (checking agreement among 4 commercial models) to create high-quality preference labels that correlate strongly with human judgment
Architecture
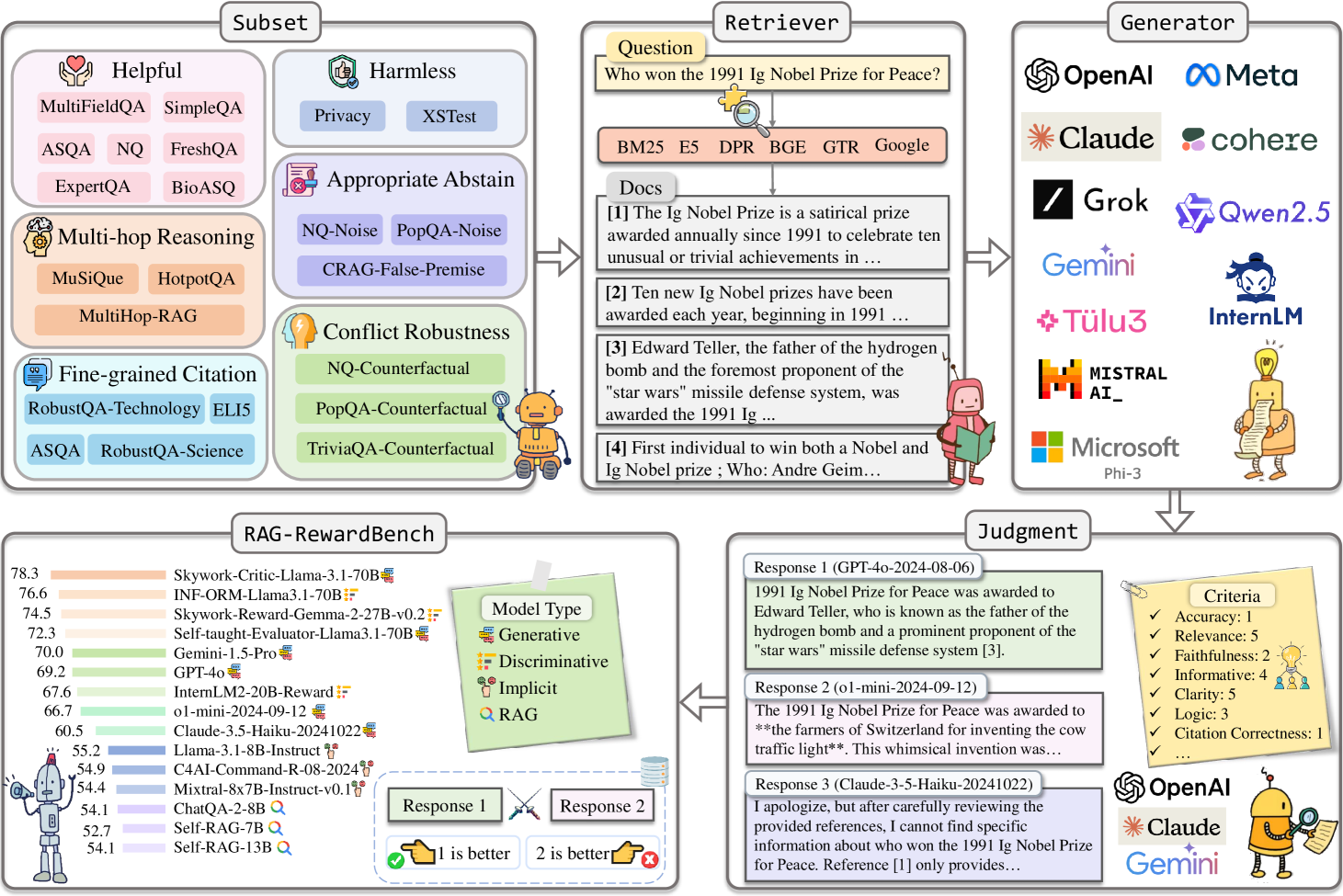
The construction pipeline of RAG-RewardBench, illustrating data sources, RAG scenarios, and the LLM-as-a-judge annotation process.
Evaluation Highlights
- Existing Reward Models struggle significantly: the top-performing model (Skywork-Critic-Llama-3.1-70B) achieves only 78.3% accuracy
- State-of-the-art trained RALMs (like Self-RAG) show almost no improvement (+0.6%) in preference alignment over base LLMs on this benchmark
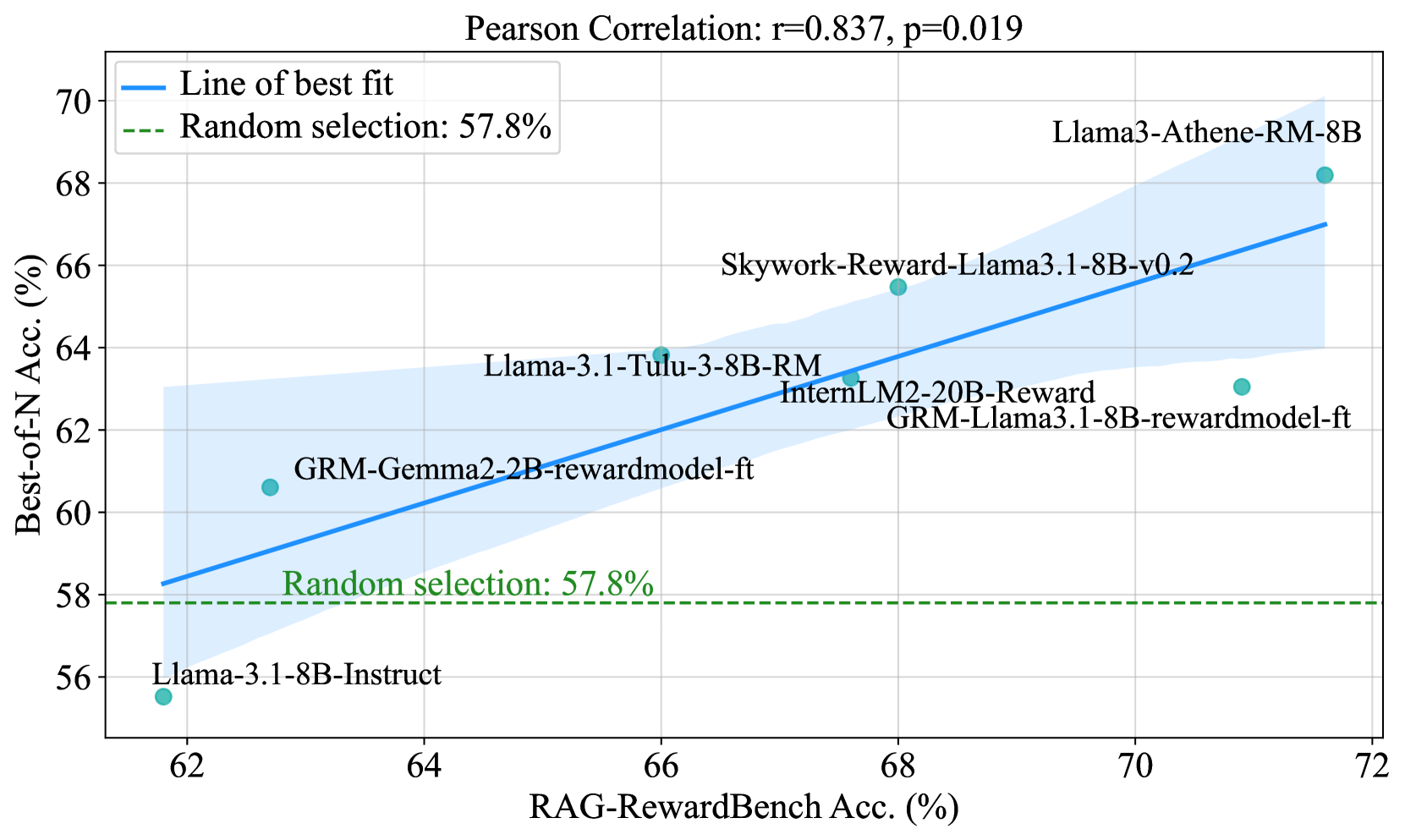
- Dataset labels achieve a Pearson correlation coefficient of 0.84 with human annotations, validating the LLM-as-a-judge construction method
Breakthrough Assessment
8/10
Addresses a critical gap in RAG alignment by establishing the first standardized benchmark for RAG reward models. The rigorous construction and revelation that current RMs fail in RAG settings are significant contributions.