📊 Experiments & Results
Evaluation Setup
Multi-hop Question Answering
Benchmarks:
- HotpotQA (Multi-hop QA)
- 2WikiMultiHopQA (Multi-hop QA)
- MuSiQue (Multi-hop QA)
Metrics:
- Accuracy (ACC)
- F1 score
- Exact Match (EM)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Main results comparing R3-RAG against baselines using Llama-3.1-8B as the backbone. | ||||
| HotpotQA | Accuracy | 52.8 | 64.4 | +11.6 |
| 2WikiMultiHopQA | Accuracy | 40.6 | 61.0 | +20.4 |
| MuSiQue | Accuracy | 16.7 | 32.2 | +15.5 |
| Ablation study demonstrating the impact of different reward components. | ||||
| Average (3 datasets) | Accuracy | 45.2 | 46.6 | +1.4 |
| Average (3 datasets) | Accuracy | 41.6 | 46.6 | +5.0 |
| Efficiency comparison against ReSearch baseline. | ||||
| Average (2Wiki + MuSiQue) | Token Usage | 524.46 | 405.01 | -119.45 |
Experiment Figures
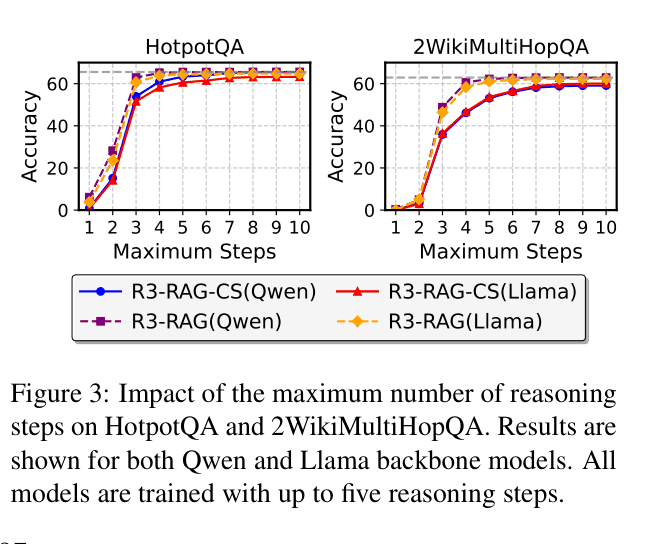
Impact of maximum reasoning steps on accuracy for HotpotQA and 2WikiMultiHopQA.
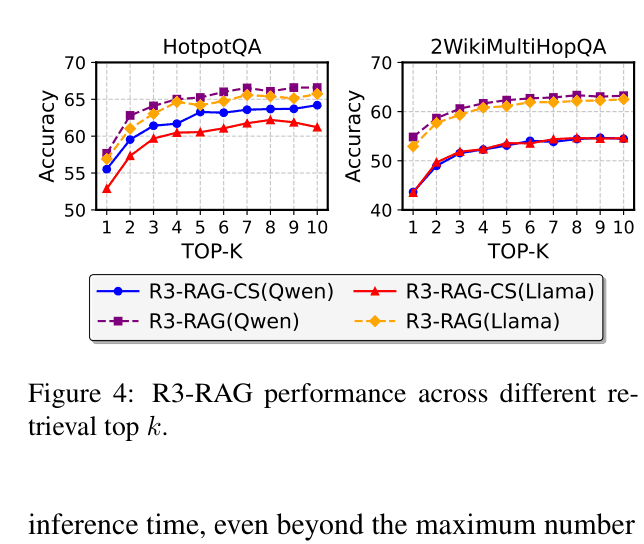
Performance across different retrieval Top-K values.
Main Takeaways
- R3-RAG significantly outperforms static workflows (IRCoT) and prompt-based methods (ReAct) across all datasets
- The combination of outcome and process rewards is crucial; removing the process reward (document relevance) causes a performance drop
- The model generalizes well to unseen retrievers (BM25, BGE) despite being trained only with E5, showing robustness
- RL training on just one dataset (HotpotQA) transfers effectively to others (2Wiki, MuSiQue), indicating the learned reasoning-retrieval policy is generalizable