📝 Paper Summary
Agentic RAG pipeline
Reinforcement Learning for RAG
ReasonRAG improves agentic retrieval-augmented generation by using Monte Carlo Tree Search to construct a high-quality process-level reward dataset, enabling the model to learn optimal reasoning steps via process-supervised Direct Preference Optimization.
Core Problem
Existing agentic RAG systems relying on outcome-supervised RL (rewarding only the final answer) suffer from sparse rewards, low exploration efficiency, and gradient conflicts when errors occur late in the reasoning chain.
Why it matters:
- Outcome-based rewards fail to identify exactly which step (query generation, evidence extraction, or reasoning) caused an error, leading to inefficient learning
- Current methods require massive amounts of training data (e.g., 90k samples for Search-R1) to converge due to sparse feedback signals
- Annotating high-quality process-level steps manually for RAG is prohibitively expensive due to the complexity of search and reasoning tasks
Concrete Example:
In a multi-hop question, if a model performs a correct search but fails to extract the key evidence, outcome-based RL penalizes the entire chain (including the correct search). ReasonRAG's process supervision rewards the correct search step while correcting the extraction step.
Key Novelty
ReasonRAG (Process-Supervised Agentic RAG)
- Uses Monte Carlo Tree Search (MCTS) to explore diverse reasoning paths (querying, reading, answering) and identifies high-quality trajectories automatically
- Introduces Shortest Path Reward Estimation (SPRE) to assign rewards to intermediate steps, favoring correct answers reached via the most efficient path
- Constructs RAG-ProGuide, a dataset of 13k process-level preference pairs, to train the model via Direct Preference Optimization (DPO) rather than just outcome-based RL
Architecture
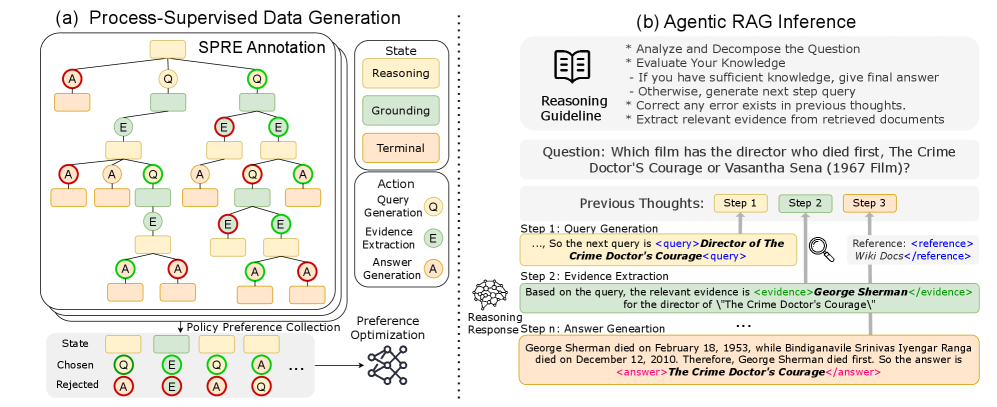
The ReasonRAG framework pipeline, divided into Data Construction (using MCTS and SPRE) and Inference (Agentic RAG workflow)
Evaluation Highlights
- Outperforms Search-R1 on HotpotQA (F1 score) by +2.7% (55.5 vs 52.8) despite using 18x fewer training instances (5k vs 90k)
- Achieves higher F1 scores than GPT-4o on 2WikiMultihopQA (53.7 vs 44.5) using a 7B parameter model
- Demonstrates 35.8% win rate over Search-R1 in pairwise comparisons, with only a 17.0% loss rate
Breakthrough Assessment
8/10
Significantly improves data efficiency for training agentic RAG systems (5k vs 90k samples) by successfully automating process-level reward annotation, addressing a major bottleneck in RL-based RAG.