📝 Paper Summary
Modularized RAG pipeline
Agentic RAG pipeline
DDR (Differentiable Data Rewards) optimizes RAG systems end-to-end by propagating rewards from the final output back to each module, aligning their data preferences to reduce knowledge conflicts.
Core Problem
Current RAG optimization methods (like SFT) train modules independently or overfit to training signals, failing to align the data preferences between the retrieval/refinement module and the generation module.
Why it matters:
- Misalignment leads to the generator ignoring relevant retrieved context or being misled by noise.
- Independent optimization overlooks that the generator often faces knowledge conflicts between parametric memory and external evidence.
- SFT approaches can cause catastrophic forgetting and do not account for how downstream agents actually utilize the data provided by upstream agents.
Concrete Example:
In a standard pipeline, a retriever might provide documents that look relevant but contain subtle conflicts with the generator's internal knowledge. An SFT-trained generator might hallucinate or ignore these documents. DDR trains the generator to signal which documents actually help it answer correctly, then updates the refinement module to prioritize those specific documents.
Key Novelty
Differentiable Data Rewards (DDR) for End-to-End RAG Alignment
- Uses a rollout method to collect rewards from the entire RAG system's final output and back-propagates them to optimize individual agents (modules).
- Employs Direct Preference Optimization (DPO) to align the data preferences of the Knowledge Refinement module with the Generation module, ensuring retrieved data is actually useful for generation.
- Iteratively optimizes agents: first the generator learns to use data effectively, then the refinement module learns to select data that maximizes the generator's performance.
Architecture
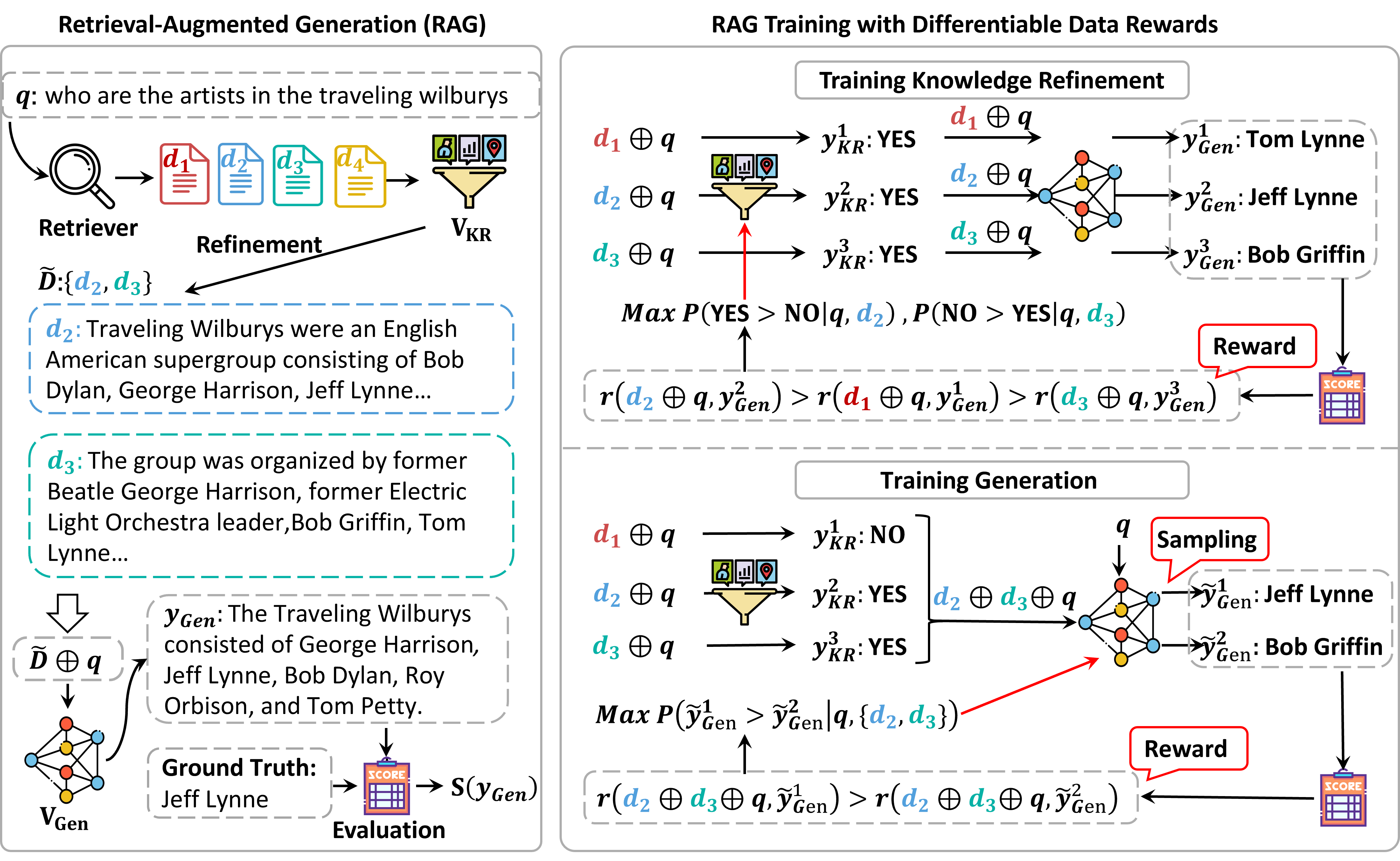
Overview of the RAG-DDR training process involving data propagation and differentiable data rewards.
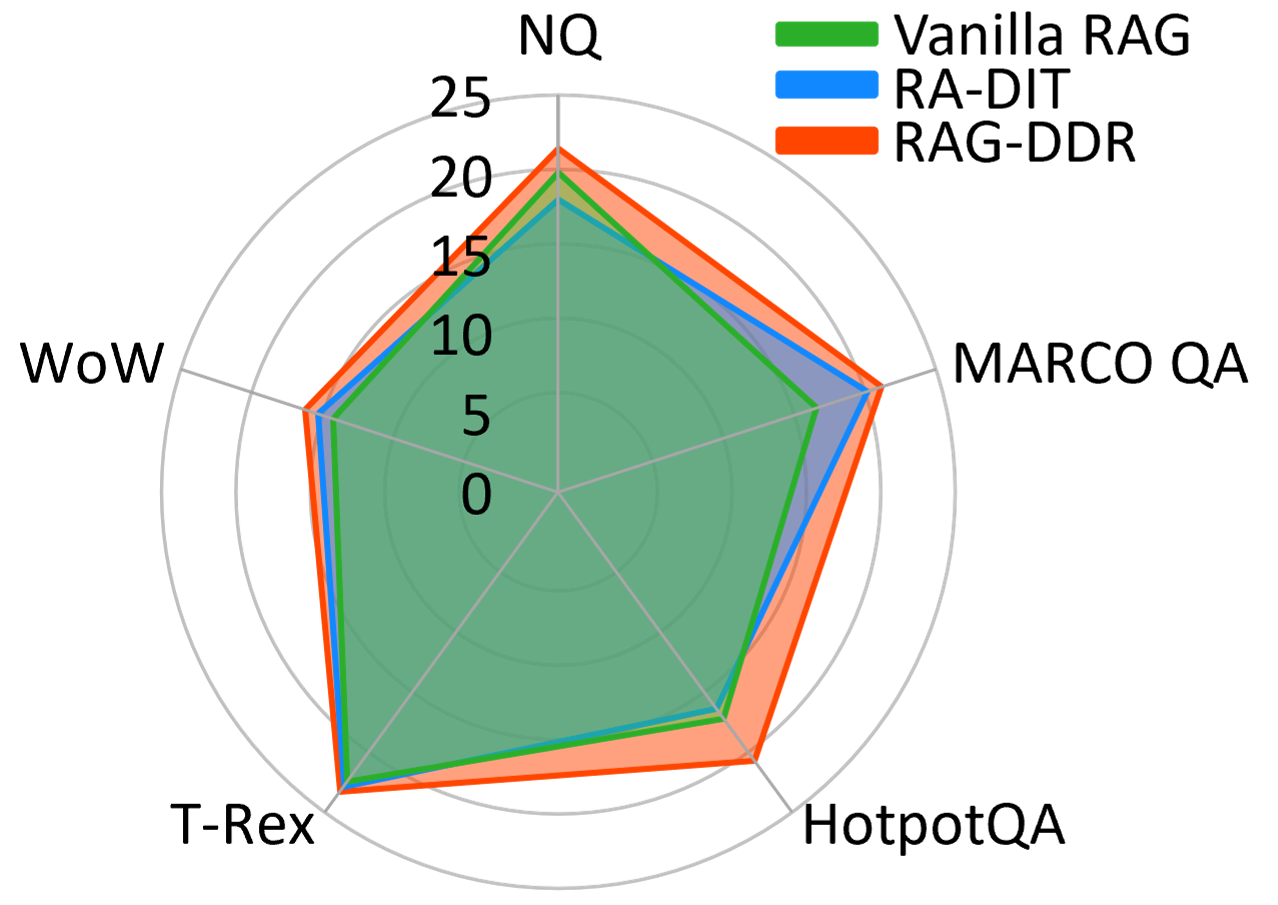
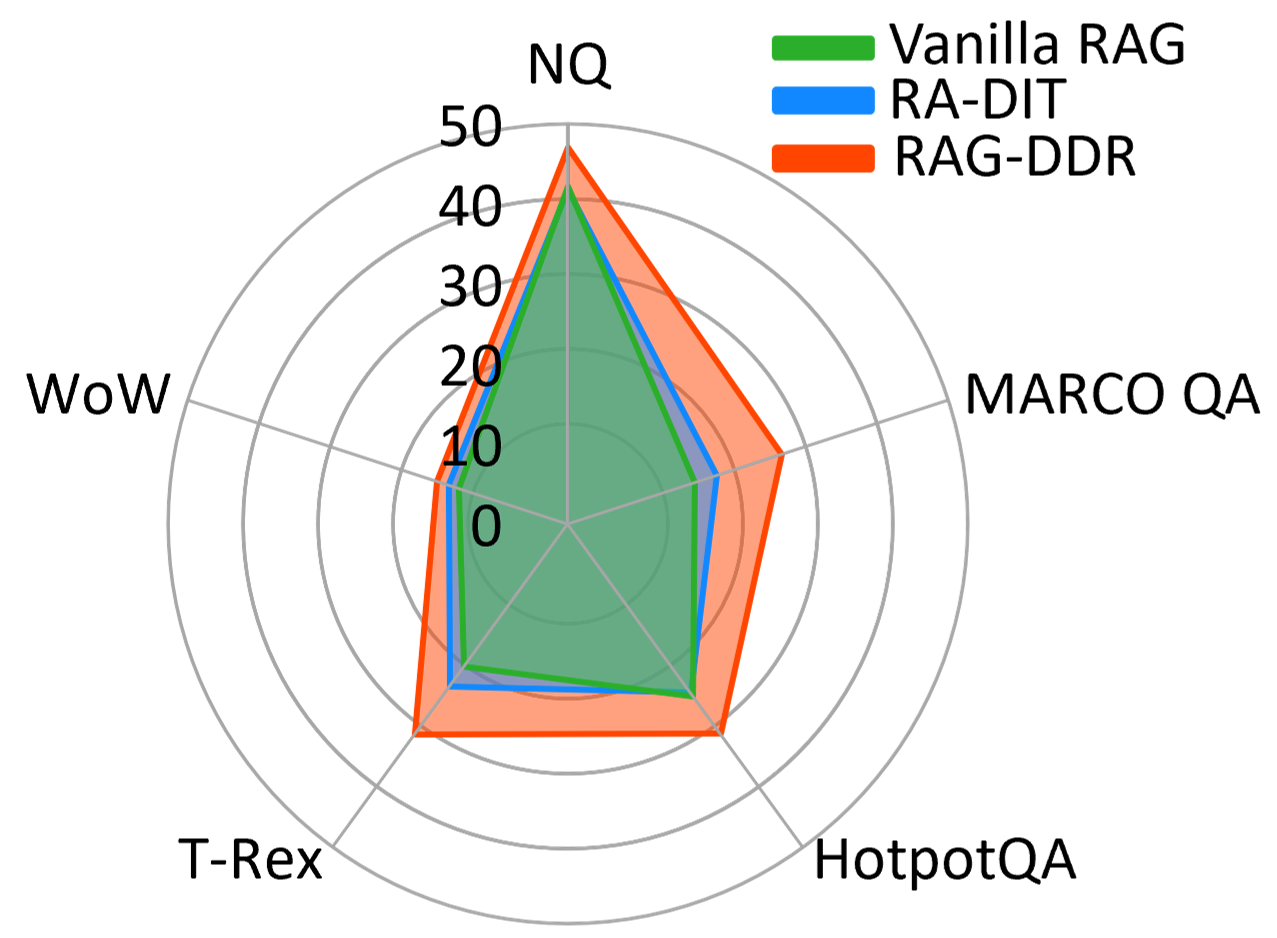
Evaluation Highlights
- Outperforms RA-DIT (SFT-based method) by +3.54 EM on Natural Questions and +2.85 EM on TriviaQA using Llama-2-7B.
- Achieves higher performance with smaller models (Llama-2-7B) than larger baselines (Llama-2-13B) on knowledge-intensive tasks, showing effective parameter efficiency.
- Reduces the average response length on PubHealth by ~35% compared to vanilla RAG while maintaining higher accuracy, indicating more concise and precise generation.
Breakthrough Assessment
7/10
Solid methodological improvement for multi-agent RAG alignment using DPO. While the core idea of end-to-end training exists, applying DPO via rollout for module alignment is a strong, practical contribution.