📝 Paper Summary
Modularized RAG pipeline
RAG Frameworks
RAG Foundry is an open-source framework that integrates data creation, training, inference, and evaluation into a single workflow to facilitate rapid prototyping and fine-tuning of LLMs for RAG use cases.
Core Problem
Implementing RAG systems is complex due to intricate design decisions (retrieval algorithms, prompt design) and the difficulty of ensuring reproducibility and evaluation across disjoint workflows.
Why it matters:
- Design decisions like text embedding, indexing, and prompting significantly impact performance but are hard to optimize in isolation
- Reproducibility is difficult due to variations in preprocessing, data, and hardware across different experiments
- Existing tools (LangChain, LlamaIndex) focus on inference pipelines but lack integrated, robust support for training and comprehensive RAG-specific evaluation
Concrete Example:
A researcher wanting to test if Chain-of-Thought (CoT) improves a specific QA task currently has to manually curate data, run a separate retrieval process, format prompts, fine-tune a model using a different library, and then run a separate evaluation script. RAG Foundry unifies these steps into a single configuration-driven flow.
Key Novelty
Integrated RAG Experimentation Framework
- Unifies the typically disjoint stages of RAG development (dataset creation, training, inference, evaluation) into a single library controlled by configuration files
- Introduces a modular 'processing' pipeline that persists RAG interactions (retrieval results, prompt templates) into a fixed dataset format, ensuring training and inference are perfectly aligned
Architecture
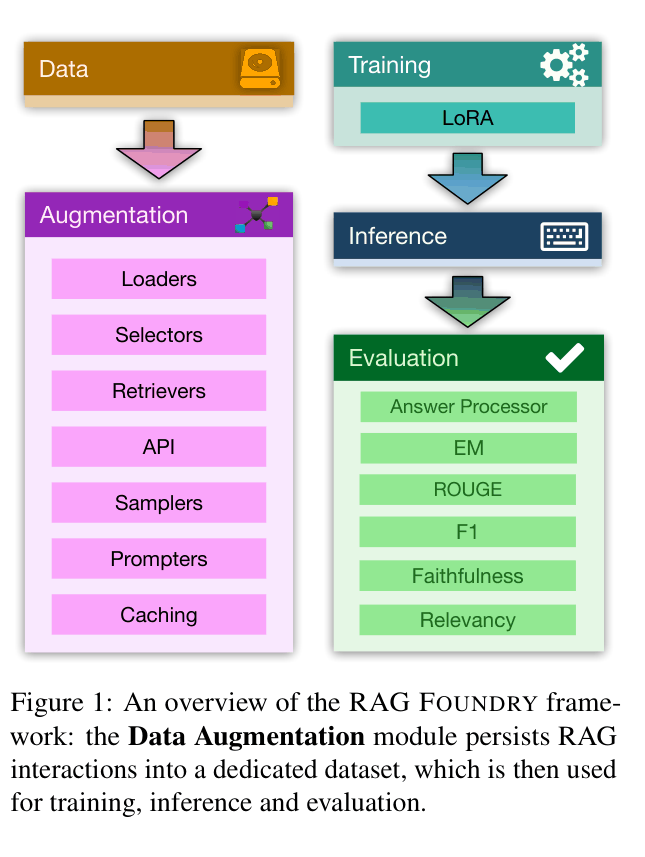
Overview of the RAG Foundry framework workflow and modules
Evaluation Highlights
- Fine-tuning Llama-3-8B-Instruct with RAG interactions improves Exact Match on TriviaQA from 0.722 (Baseline) to 0.916 (RAG-sft)
- Using Chain-of-Thought (CoT) fine-tuning on Phi-3-mini increases STR-EM on ASQA from 0.109 (Baseline) to 0.386 (CoT-sft)
- Framework effectively demonstrates that different datasets require different RAG strategies; CoT degrades performance on TriviaQA (-0.083 EM vs RAG-sft) but improves it on ASQA (+0.134 STR-EM vs RAG-sft) for Llama-3
Breakthrough Assessment
7/10
While not introducing a new model architecture, it provides a significant engineering contribution by unifying the fractured RAG development workflow, enabling systematic comparison of techniques.